物理地址对于进程不可见,谁也不能直接访问这个物理地址。操作系统会给进程分配一个虚拟地址。所有进程看到的这个地址都是一样的,里面的内存都是从 0 开始编号。在程序里面,指令写入的地址是虚拟地址。之后,系统会提供一种机制,将不同进程的虚拟地址和不同内存的物理地址映射起来。当程序要访问虚拟地址的时候,由内核的数据结构进行转换,转换成不同的物理地址,这样不同的进程运行的时候,写入的是不同的物理地址,这样就不会冲突了。
总的来说,操作系统的内存管理,主要分为以下三个方面:
- 物理内存的管理
- 虚拟地址的管理
- 虚拟地址和物理地址如何映射
针对 Linux 的内存管理来说,因为 Linux 采用的是分页机制而不是分段机制,所以总的来说可以精细为以下三件事精:
- 虚拟内存的管理,是将虚拟内存划分成大小相等的页;
- 物理内存的管理,是将物理内存划分成大小相等的页;
- 内存映射,是通过页表将虚拟内存页和物理内存页映射起来的,并且在内存紧张的时候可以换出到硬盘中;
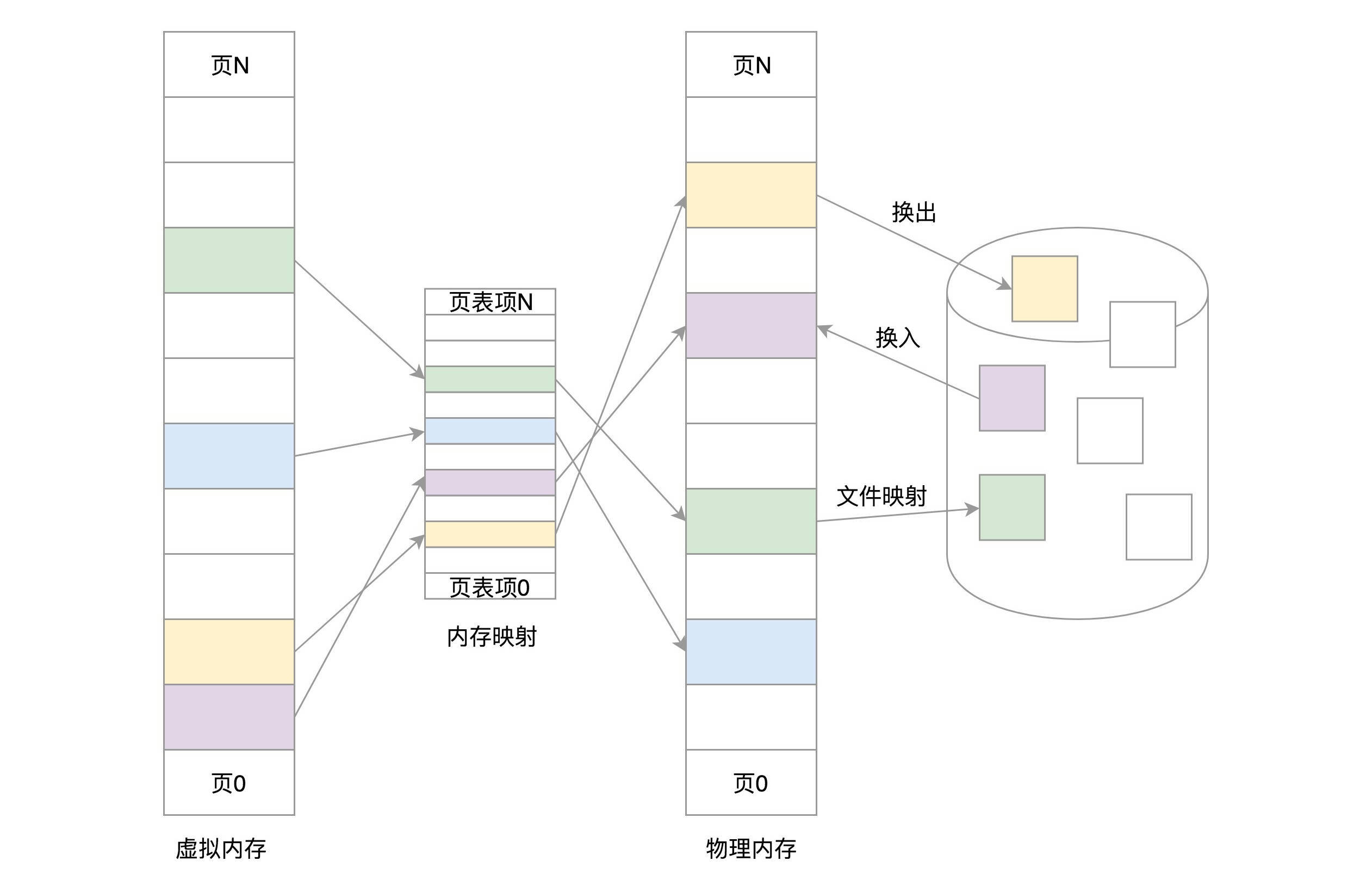
1. 虚拟内存管理
用户态和内核态(除内存管理之外)都只能使用虚拟内存地址访问,只有内核中的内存管理才可以使用物理地址。
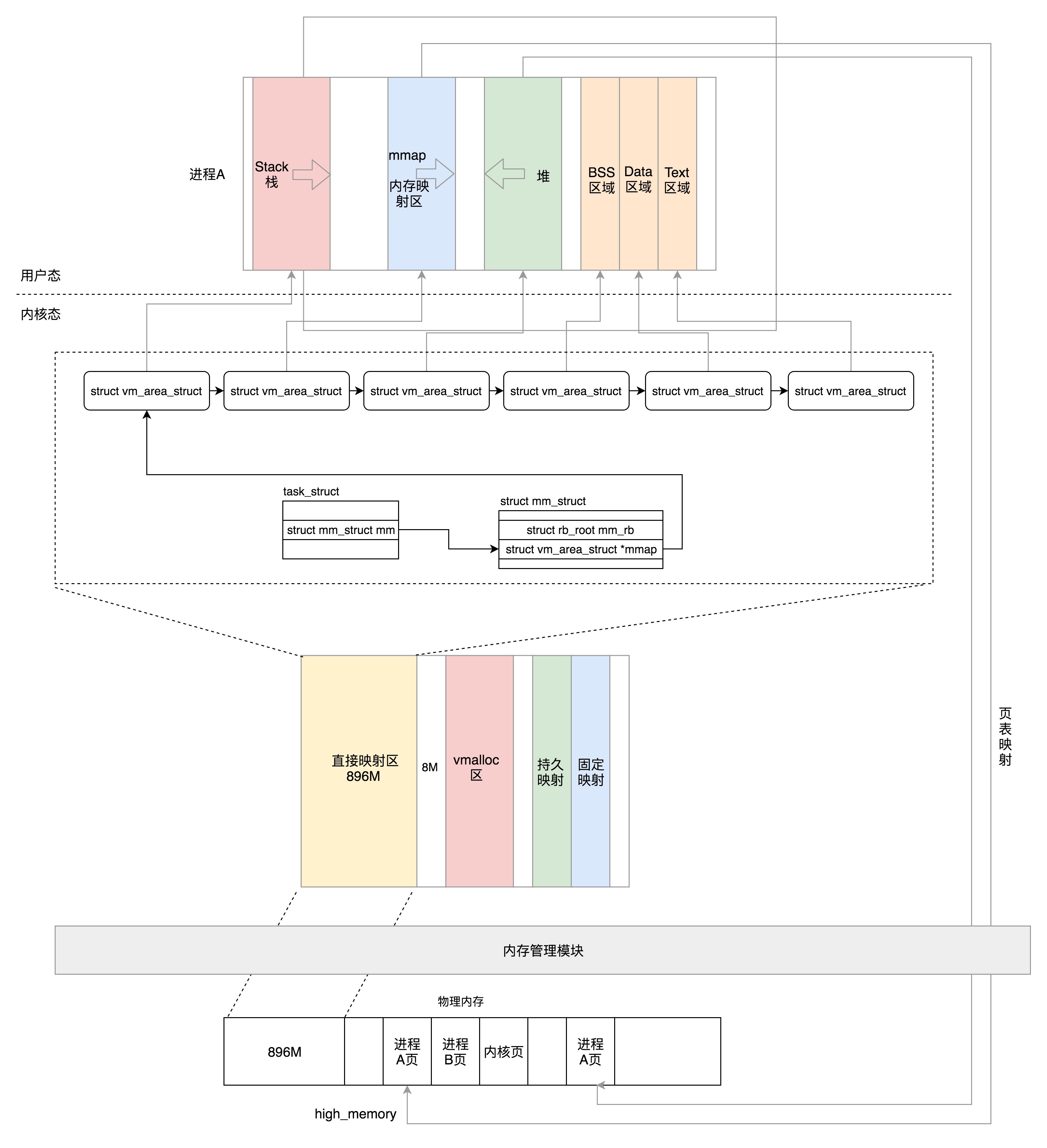
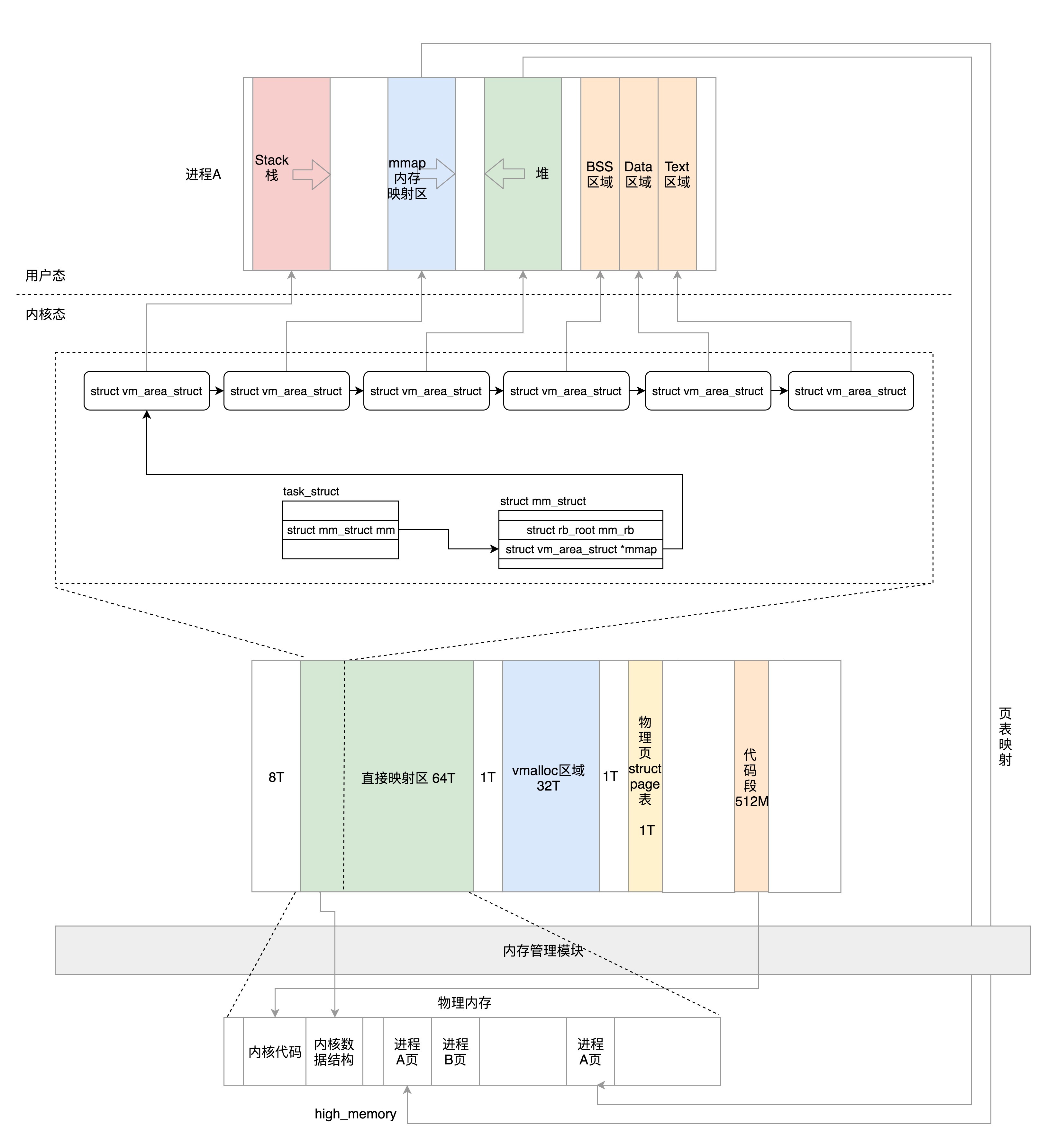
1.1. 虚拟空间的布局
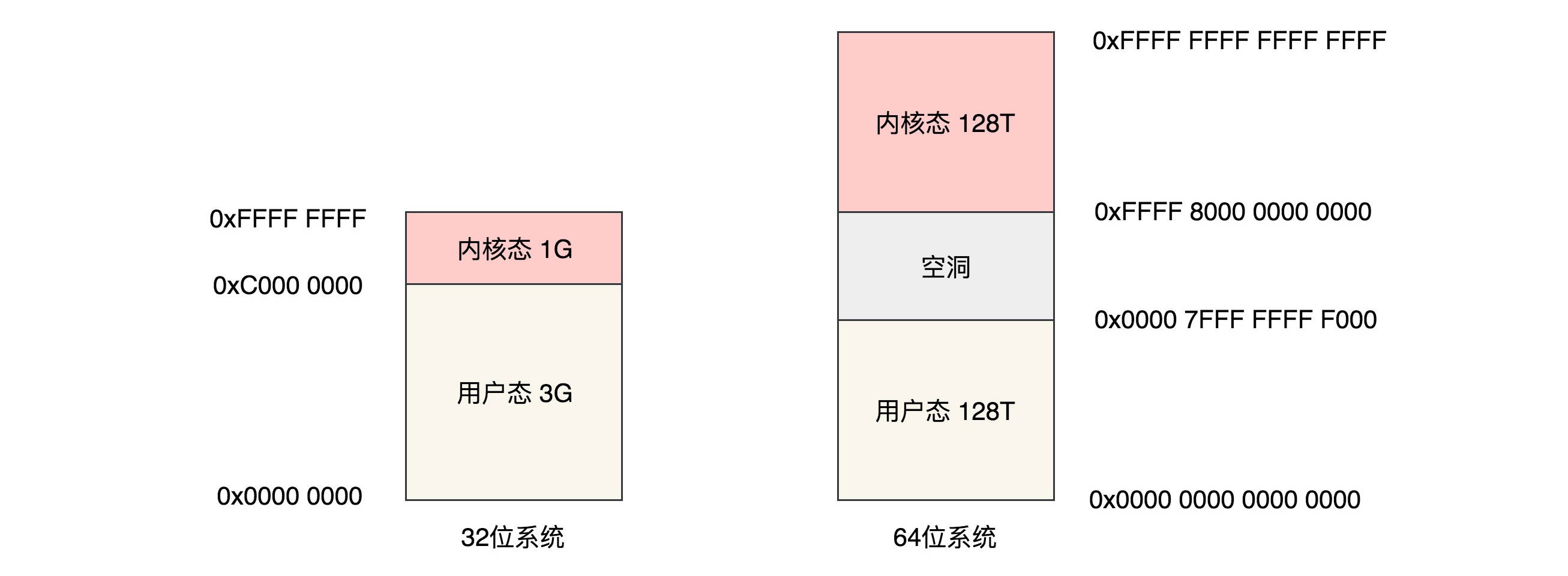
每个进程的虚拟空间被一分为二,一部分被用来放内核的东西,称为内核空间,一部分用来放进程的东西,称为用户空间。用户空间在低地址处,内核空间在高地址处。
vdso、vvar 是与系统调用相关的内存区域
1.1.1. 用户态和内核态的划分
struct task_struct 中的 struct mm_struct 结构是用来管理内存的;struct mm_struct 结构中的 task_size 则用于定义内核态和用户态的分界线。
// include\linux\mm_types.h
struct mm_struct {
struct {
...
unsigned long task_size; /* size of task vm space */
...
}
}
对于 x86 位系统来说,TASK_SIZE 的定义如下所示。
// arch\x86\include\asm\processor.h
#ifdef CONFIG_X86_32
/*
* User space process size: 3GB (default).
*/
...
#define TASK_SIZE PAGE_OFFSET
#define TASK_SIZE_LOW TASK_SIZE
#define TASK_SIZE_MAX TASK_SIZE
#define DEFAULT_MAP_WINDOW TASK_SIZE
#define STACK_TOP TASK_SIZE
...
#else
#define TASK_SIZE_MAX ((1UL << __VIRTUAL_MASK_SHIFT) - PAGE_SIZE)
...
#define IA32_PAGE_OFFSET ((current->personality & ADDR_LIMIT_3GB) ? \
0xc0000000 : 0xFFFFe000)
#define TASK_SIZE (test_thread_flag(TIF_ADDR32) ? \
IA32_PAGE_OFFSET : TASK_SIZE_MAX)
...
// arch\x86\include\asm\page_64_types.h
#ifdef CONFIG_X86_5LEVEL
#define __VIRTUAL_MASK_SHIFT (pgtable_l5_enabled() ? 56 : 47)
#else
#define __VIRTUAL_MASK_SHIFT 47
#endif
那么当执行一个新的进程的时候,会做如下的设置。
current->mm->task_size = TASK_SIZE;
对于 32 位的系统来说,最大可搜寻的地址范围是 4G,其中用户态虚拟地址空间是 3G,内核态是 1G。
对于 64 位的系统来说,虚拟地址只使用了 48 位。根据代码可以知道,用户态虚拟空间的范围为 0x0000 0000 0000 0000-0x0000 7FFF FFFF F000,其实就是 1 左移 48 位(128T),然后减去一个页,约 128T。而内核空间是 128T,范围是 0xFFFF 8000 0000 0000 - 0xFFFF FFFF FFFF FFFF。也就是说内核空间和用户空间之间隔着很大的空隙,以此来进行隔离。
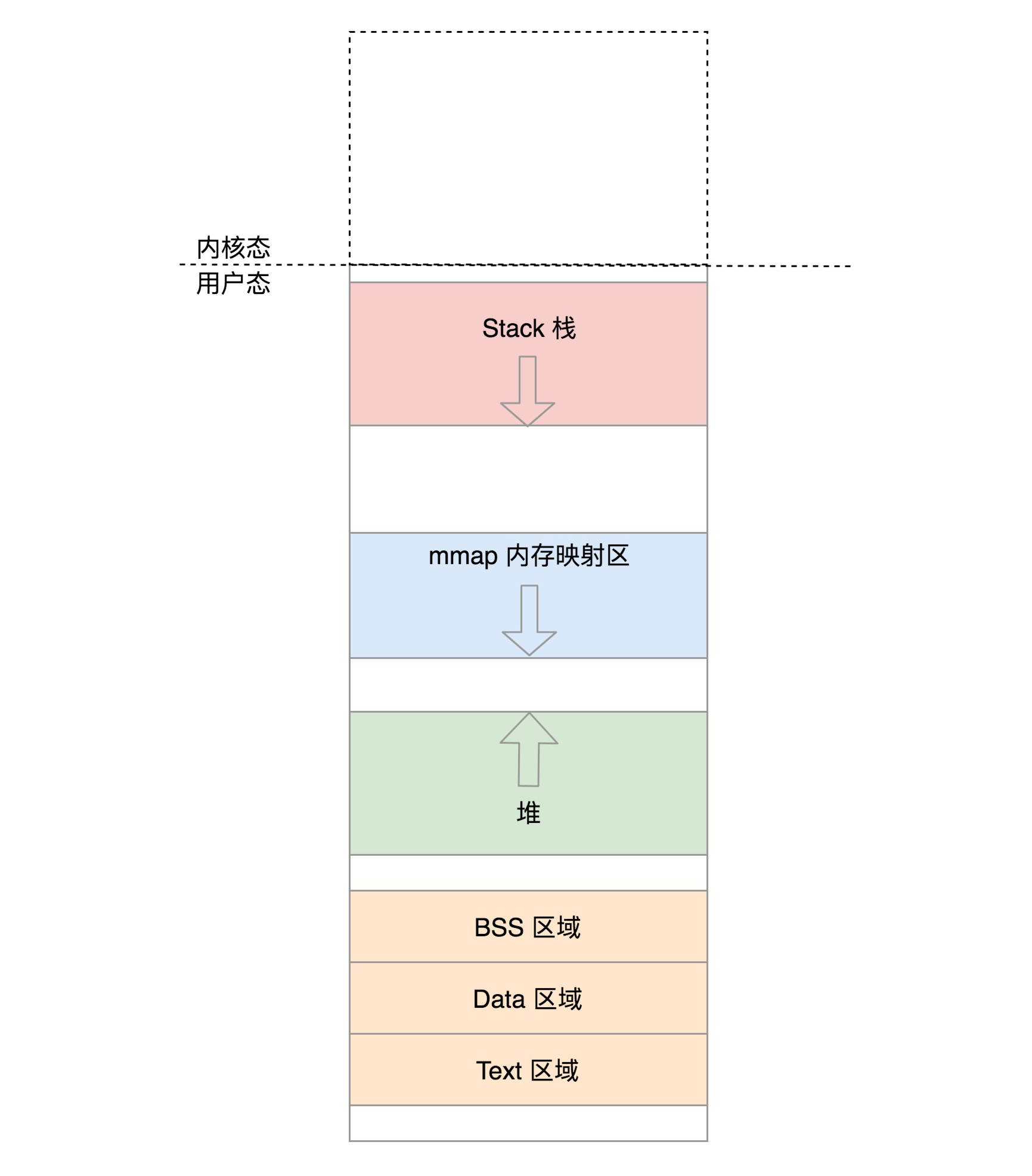
1.1.2. 用户态的布局
下面先来看一下用户态虚拟空间的布局,如下图所示(32 位和 64 位的空间大小相差很大,但是区域的类别和布局是相似的),从最低位开始,依次是
-
text segment 存放二进制可执行代码;
-
data segment 存放静态常量;
-
BSS segment 存放未初始化的静态变量;
-
heap,堆是往高地址增长的,用来动态分配内存的区域,malloc 就是在这里面分配的;
-
memory mapping segment,这个区域是用来把文件映射到内存中的,比如 SO 文件就是被映射到这块内存中;
-
栈地址段,主线程的函数调用就在这里。
堆区和栈区分配内存时的效率:
- 栈分配算法简单,有专门的寄存器,压栈和出栈的指令效率很高。
- 堆分配算法相对复杂,堆在分配和释放时都要调用函数(MALLOC,FREE),比如分配时会到堆空间去寻找足够大小的空间,会造成内存碎片过多,这些都会花费一定的时间,栈却不需要这些。
- 访问堆的一个具体单元,需要两次访问内存,第一次得取得指针,第二次才是真正得数据,而栈只需访问一次。另外,堆的内容被操作系统交换到外存的概率比栈大,栈一般是不会被交换出去的。
- 在分配栈内存的时候,栈内存一定是已经加载到物理内存的,而堆内存在分配的时候可能不一定有相应的物理内存,也就是说可能会涉及到分配物理内存,然后建立映射等等。
struct mm_struct 中有相关的关于 Text、Data、BSS、堆、栈、内存映射区等的统计信息和位置。
// include\linux\mm_types.h
struct mm_struct {
struct {
......
unsigned long mmap_base; /* base of mmap area */
unsigned long total_vm; /* Total pages mapped */
atomic_long_t locked_vm; /* Pages that have PG_mlocked set */
unsigned long pinned_vm; /* Refcount permanently increased */
unsigned long data_vm; /* VM_WRITE & ~VM_SHARED & ~VM_STACK */
unsigned long exec_vm; /* VM_EXEC & ~VM_WRITE & ~VM_STACK */
unsigned long stack_vm; /* VM_STACK */
unsigned long def_flags;
spinlock_t arg_lock; /* protect the below fields */
unsigned long start_code, end_code, start_data, end_data;
unsigned long start_brk, brk, start_stack;
unsigned long arg_start, arg_end, env_start, env_end;
......
}
}
- mmap_base 表示虚拟地址空间用于内存映射的起始地址。一般情况下,内存映射空间是从高地址到低地址增长的。malloc 申请一大块内存的时候,就是通过 mmap 在这个空间里映射一块区域到物理内存。加载动态链接库 so 文件的时候,也是在这个空间将一块区域映射到 so 文件。
- total_vm 总共映射的页的数目。这么大的虚拟地址空间,不可能都有真实内存对应,所以这里是映射的数目。
- locked_vm 表示被锁定不能换出的页数目。
- pinned_vm 表示不能换出也不能移动的页数目。
- data_vm 存放数据的页数目
- exec_vm 存放可执行文件的页数目
- stack_vm 栈所占的页数目
- start_code、end_code 表示可执行代码的开始和结束位置
- start_data、end_data 表示已初始化数据的开始和结束位置
- start_brk、brk 表示堆的开始和当前结束位置。假如使用 malloc 申请内存的时候,会改变 brk 的位置
- start_stack 栈的起始位置,栈的结束位置存放在寄存器的栈顶寄存器中
- arg_start 和 arg_end 表示参数列表的开始和结束位置(位于栈中最高地址的地方)
- env_start 和 env_end 表示环境变量的开始和结束位置(位于栈中最高地址的地方)
1.1.3. 内核态的布局
虽然每个进程的虚拟空间都有内核空间,但是内核空间是不能直接访问的。可以通过系统调用进入内核空间,那么不同进程进入内核空间之后,看到的虚拟地址空间都是一样的,使用的都是同一个内核空间(也就是映射到是同一块物理内存区域)。
虽然每个进程在内核空间都有他自己的内核栈,但是由于是使用同一个内核空间,那么这些内核栈其实都是可以被访问到的。另外,在内核空间中要访问一些公共的数据结构,是需要进行锁保护的。需要注意的是:内核中的代码只能访问内核空间(你就想会有很多个进程进入内核空间,内核代码假如访问用户空间的话,他不清楚这个是用户空间是哪个用户空间的)。
另外,内核代码访问内核空间也是使用虚拟地址,但是内核态中会涉及到物理内存管理,所以需要注意区分物理内存地址和虚拟内存地址。
在内核态,32 位和 64 位的布局差别比较大,主要是因为 32 位内核态空间太小了。
1.1.3.1. 32 位的内核态的布局
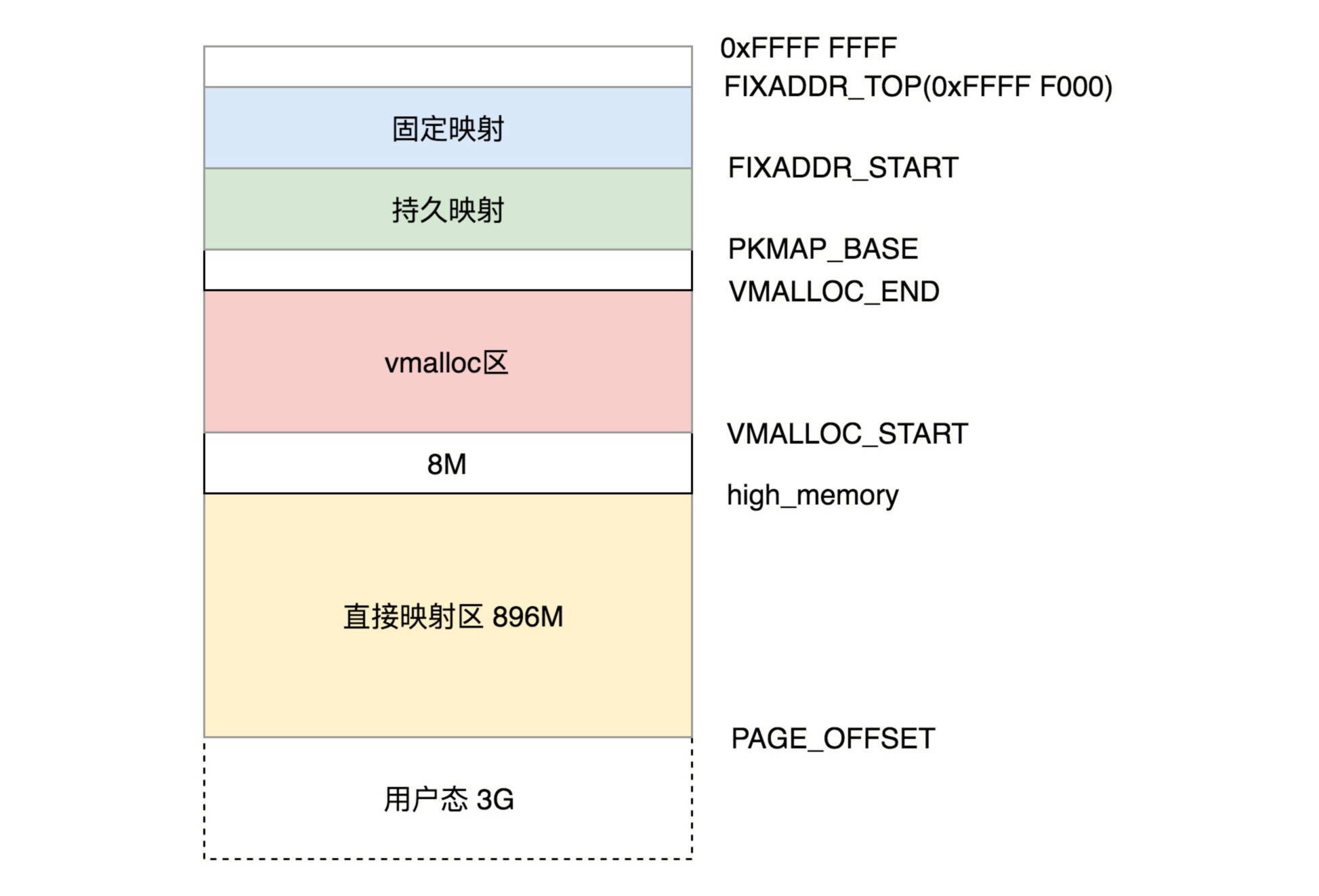

32 位的内核态虚拟地址空间一共就 1G。
-
前 896M,被称为直接映射区。所谓的直接映射区,就是这一块空间是连续的,和物理内存是非常简单的映射关系,物理地址 = 虚拟地址-3G,也就是说物理内存 896M 的空间会被直接映射到 3G-(3G+896M) 的虚拟空间。对于这块虚拟空间的访问其实还是使用虚拟地址,并且将来也会为这一段空间建设页表,对这段地址的访问也会走上一节我们讲的分页地址的流程,只不过页表里面比较简单,是直接的一一对应而已。
内核中有两个宏定义可以直接获取这块区域的物理地址和虚拟地址:
- __pa(vaddr) 返回与虚拟地址 vaddr 相关的物理地址
- __va(paddr) 返回与物理地址 paddr 对应的虚拟地址
// arch\x86\include\asm\page.h #define __va(x) ((void *)((unsigned long)(x)+PAGE_OFFSET)) #define __pa(x) __phys_addr((unsigned long)(x)) // arch\x86\include\asm\page_32.h #define __phys_addr(x) __phys_addr_nodebug(x) #define __phys_addr_nodebug(x) ((x) - PAGE_OFFSET)在这 896M 中,在系统启动的时候,物理内存的前 1M 就已经被占用了。因此,是从 1M 处开始依次加载内核代码、内核的全局变量、BSS。也就是,内核的代码段、全局变量、BSS 也会被映射到 3G 后的虚拟地址空间里面(具体的物理内存布局可以查看 /proc/iomem)。
内核中创建进程时会创建 struct task_struct,而这些创建的 struct task_struct 也会被放到虚拟地址空间 3G-3G+896M 中,也就是物理地址 0-896M 中。相应的页表也会被创建。
内核创建的内核栈跟上面的情况也是一样的。
896M 这个值在内核中被定义为 high_memory,在这个地址之上的常称为“高端内存”。
-
896M 和 VMALLOC_START 之间有 8M 的空洞
-
VMALLOC_START 和 VMALLOC_END 之间被称为内核动态映射空间,该区域是由内核函数
vmalloc来分配(vmalloc 类似于用户态的 malloc)。这个函数分配的特点是:线性空间连续,但是对应的物理地址空间不一定连续。vmalloc分配的线性地址所对应的物理页可能处于低端内存,也可能处于高端内存。所以,必须通过内核页表才可转换为物理地址或物理页,它们有可能尚未被映射,当发生缺页时才真正分配物理页面。另外,每一块
vmalloc分配的内核虚拟内存都对应一个vm_struct结构体,不同的内核空间虚拟地址之间有4k大小的防越界空闲区间隔区。需要注意的是,vmalloc分配的地址则限于vmalloc_start与vmalloc_end之间。 -
PKMAP_BASE 到 FIXADDR_START 的空间被称为持久映射,使用 alloc_pages() 会在物理内存的高端内存得到 struct page 结构,之后可以调用 kmap() 将其映射到这个区域。
-
FIXADDR_START 到 FIXADDR_TOP(0xFFFF F000) 的空间,被称为固定映射区域,主要用于满足特殊需求。
-
而最后剩下的那个区域可以通过 kmap_atomic() 实现临时内核映射。临时内核映射可以用于文件读写的情况。假设用户态的进程要映射一个文件到内存,那么需要先映射用户态进程空间的一段虚拟地址到物理内存,然后将文件内容写入这个物理内存中供用户进程访问,这个时候不需要从内核态虚拟空间中也划出一块来映射这些物理页。但是,假如需要将内容写入文件,那么此时需要内核了,内核先通过 kmap_atomic() 做一个临时映射,映射到相应的物理页,然后将内容写入物理内存,写入完毕之后再使用 kunmap_atomic() 来解除映射即可。
1.1.3.2. 64 位的内核态的布局
64 位的内核布局反而简单,因为虚拟空间实在是太大了,根本不需要所谓的高端内存,因为内核是 128T,根本不可能有物理内存超过这个值。

- 从 0xFFFF 8000 0000 0000 开始就是内核的部分,只不过一开始有 8T 的空档区域。
- 从
__PAGE_OFFSET_BASE(0xFFFF 8800 0000 0000) 开始的 64T 虚拟地址空间是直接映射区域,与 32 位一样,这个区域的虚拟地址减去 PAGE_OFFSET 就是物理地址。虚拟地址和物理地址之间的映射在大部分情况下还是会通过建立页表的方式进行映射。 - VMALLOC_START(0xFFFF C900 0000 0000) 开始到 VMALLOC_END(0xFFFF E900 0000 0000) 的 32T 空间是给 vmalloc 的。
- VMEMMAP_START(0xFFFF EA00 0000 0000) 开始的 1T 空间用于存放物理页面的描述结构 struct page。
__START_KERNEL_map(0xFFFF FFFF 8000 0000) 开始的 512M 用于存放内核代码段、全局变量、BSS 等。这里对应到物理内存开始的位置,就是减去__START_KERNEL_map。换句话说,这里的虚拟地址减去__START_KERNEL_map就能得到物理内存的地址了,跟直接映射区有点像。
1.1.4. 查看内存布局
# 查看某个进程的内存空间布局
$ cat /proc/$pid/maps
$ pmap
1.1.5. 总结
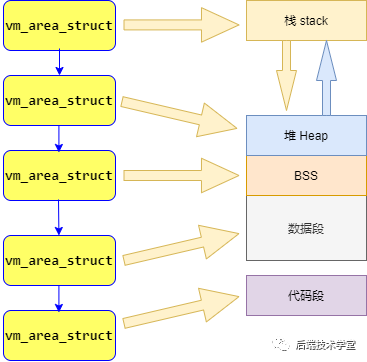
进程运行状态在 32 位下对应关系:
对于 64 位的对应关系,只是稍有区别:
1.1.6. 巨人的肩膀
https://zhuanlan.zhihu.com/p/67435146
https://manybutfinite.com/post/how-the-kernel-manages-your-memory/
1.2. 虚拟内存管理和分配
虚拟内存管理和分配不仅仅是物理内存和虚拟内存之间的映射,也包括将文件中的内容映射到虚拟内存空间(访问内存空间就能够访问到文件里面的数据)。
1.2.1. 用户态
1.2.1.1. vm_area_struct
之前我们讲过用户空间的布局如下所示:
在 struct mm_struct 中有相关的关于 Text、Data、BSS、堆、栈、内存映射区等的统计信息和位置。那么,除了基本的位置信息外,还有专门的结构 struct vm_area_struct 用来描述这些区域的属性(一个区域用一个 struct vm_area_struct)。其中 struct mm_struct 中的 mmap 指向一个链表,这个链表将描述区域的 struct vm_area_struct 全都链接起来。而 mm_rb 则是红黑树的根节点,这棵红黑树由描述区域的 struct vm_area_struct 组成。使用红黑树的目的自然是为了让查找和修改都很快,在这里则是为了在给定一个虚拟地址后,我们可以快速查找到这个虚拟地址所在的内存区域。
这里同时使用两种数据结构是因为,链表用于需要遍历全部节点的时候用,而红黑树适用于在地址空间中定位特定内存区域。内核为了内存区域上的各种不同操作都能获得高性能,所以同时使用了这两种数据结构。
// include\linux\mm_types.h
struct mm_struct {
struct {
struct vm_area_struct *mmap; /* list of VMAs */
struct rb_root mm_rb;
......
};
......
};
struct vm_area_struct {
unsigned long vm_start; /* Our start address within vm_mm. */
unsigned long vm_end; /* The first byte after our end address within vm_mm. */
/* linked list of VM areas per task, sorted by address */
struct vm_area_struct *vm_next, *vm_prev;
struct rb_node vm_rb;
struct mm_struct *vm_mm; /* The address space we belong to. */
struct anon_vma *anon_vma; /* Serialized by page_table_lock */
/* Function pointers to deal with this struct. */
const struct vm_operations_struct *vm_ops;
struct file * vm_file; /* File we map to (can be NULL). */
void * vm_private_data; /* was vm_pte (shared mem) */
};
- vm_start、vm_end 指定了该区域在用户空间中的起始和结束地址
- vm_next、vm_prev 相当于前后指针,将 struct vm_area_struct 这个结构体串在链表上
- vm_rb 将 struct vm_area_struct 这个结构体放在红黑树上
- vm_ops 表示对这个内存区域可以做的操作的定义
- 虚拟内存区域可以映射到物理内存,也可以映射到文件。映射到物理内存的时候称为匿名映射,会使用到 annon_vma;映射到文件的时候,vm_file 需要指定被映射的文件。
将虚拟内存区域和相关的数据结构串起来之后,示意图如图所示。
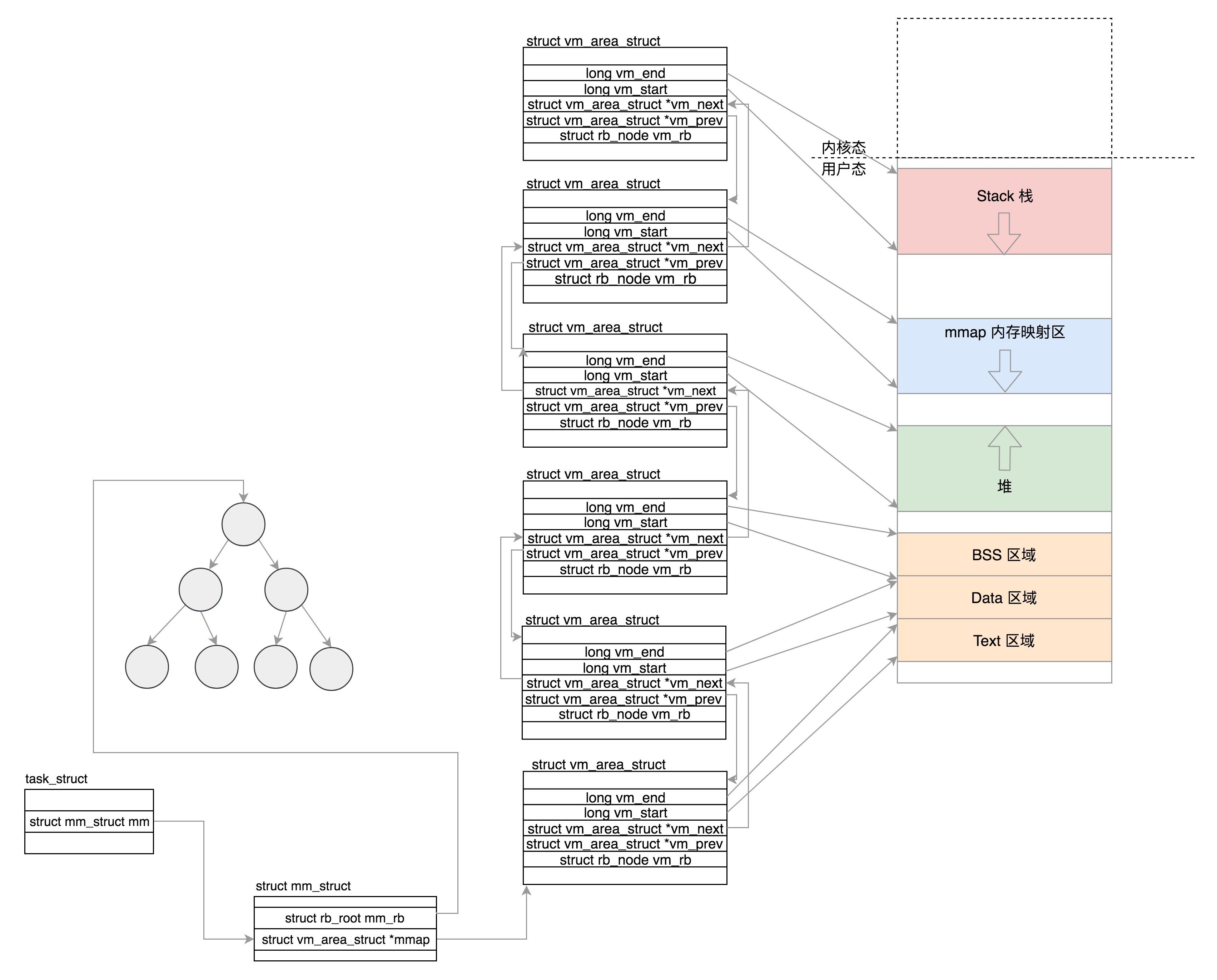
堆区中假如分配多个映射区域,那么会有多个 vm_area_struct。
那么什么时候会构建如上图的所示的情况呢?这个是发生在函数 load_elf_binary() 中(加载内核、启动第一个用户态进程、exec 运行一个二进制程序调用的都是这个函数)。
load_elf_binary() 除解析 ELF 格式之外,还会建立内存映射。针对内存映射来说,主要做以下这些事:
- setup_new_exec() 设置内存映射区域 mmap_base
- setup_arg_pages() 设置栈对应的 struct vm_area_struct,这个函数中会设置 mm->arg_start 为栈底地址
- elf_map() 映射 ELF 中的代码部分
- set_brk() 设置堆对应的 struct vm_area_struct,这个函数中会设置 current->mm->start_brk=current->mm->brk
- load_elf_interp() 将依赖的 so 映射到内存映射区域
// fs\binfmt_elf.c
static int load_elf_binary(struct linux_binprm *bprm)
{
......
setup_new_exec(bprm);
......
retval = setup_arg_pages(bprm, randomize_stack_top(STACK_TOP),
executable_stack);
......
error = elf_map(bprm->file, load_bias + vaddr, elf_ppnt,
elf_prot, elf_flags, total_size);
......
retval = set_brk(elf_bss, elf_brk, bss_prot);
......
elf_entry = load_elf_interp(&loc->interp_elf_ex,
interpreter,
&interp_map_addr,
load_bias, interp_elf_phdata);
......
current->mm->end_code = end_code;
current->mm->start_code = start_code;
current->mm->start_data = start_data;
current->mm->end_data = end_data;
current->mm->start_stack = bprm->p;
......
}
那么映射的情况什么时候会改变呢?
- 一是在函数调用的时候,因为会改变栈顶指针,即相应的区域也被改变了;
- 二是 malloc() 申请一块内存的时候,此时如果分配的是大内存(大于 128K),那么就会调用 mmap() 分配内存,是用 sys_mmap 系统调用;如果分配的是小内存(小于 128K),那么则调用 brk(),是用 sys_brl 系统调用。这两者的区别在于分配的内存区域不同。
- 三是直接调用 mmap 系统调用分配。
1.2.1.2. mmap
如果申请一大块内存,就要用 mmap。
- 对于匿名映射来讲,mmap 会映射内存空间到物理内存
- 对于映射文件来讲,mmap 会映射内存空间到物理内存再到文件。
下面我们来看 mmap 这个系统调用:
SYSCALL_DEFINE6(mmap, unsigned long, addr, unsigned long, len,
unsigned long, prot, unsigned long, flags,
unsigned long, fd, unsigned long, off)
{
......
error = sys_mmap_pgoff(addr, len, prot, flags, fd, off >> PAGE_SHIFT);
......
}
SYSCALL_DEFINE6(mmap_pgoff, unsigned long, addr, unsigned long, len,
unsigned long, prot, unsigned long, flags,
unsigned long, fd, unsigned long, pgoff)
{
struct file *file = NULL;
......
file = fget(fd);
......
retval = vm_mmap_pgoff(file, addr, len, prot, flags, pgoff);
return retval;
}
-
如果要映射到文件,fd 会传进来一个文件描述符,并且 mmap_pgoff 里面通过 fget 函数,根据文件描述符获得 struct file,struct file 表示打开的一个文件。
-
如果是匿名映射,就不用 fd 这些。
接下来的调用链是 vm_mmap_pgoff->do_mmap_pgoff->do_mmap。这里面主要干了两件事情:
- 调用 get_unmapped_area 找到一个没有映射的区域;
- 调用 mmap_region 映射这个区域;
对于 get_unmapped_area 函数来说:
unsigned long
get_unmapped_area(struct file *file, unsigned long addr, unsigned long len,
unsigned long pgoff, unsigned long flags)
{
unsigned long (*get_area)(struct file *, unsigned long,
unsigned long, unsigned long, unsigned long);
......
get_area = current->mm->get_unmapped_area;
if (file) {
if (file->f_op->get_unmapped_area)
get_area = file->f_op->get_unmapped_area;
}
......
}
-
如果是匿名映射,调用 mm_struct(current->mm) 里面的 get_unmapped_area 函数。这个函数其实是 arch_get_unmapped_area。它会调用 find_vma_prev,在表示虚拟内存区域的 vm_area_struct 红黑树上找到相应的位置。之所以叫 prev,是说这个时候虚拟内存区域还没有建立,找到前一个 vm_area_struct。
-
如果是映射到一个文件,这样在 Linux 里面,每个打开的文件都有一个 struct file 结构,里面有一个 file_operations,用来表示和这个文件相关的操作。
如果是我们熟知的 ext4 文件系统,调用的是 thp_get_unmapped_area。如果我们仔细看这个函数,最终还是调用 mm_struct 里面的 get_unmapped_area 函数。殊途同归。
const struct file_operations ext4_file_operations = { ...... .mmap = ext4_file_mmap .get_unmapped_area = thp_get_unmapped_area, }; unsigned long __thp_get_unmapped_area(struct file *filp, unsigned long len, loff_t off, unsigned long flags, unsigned long size) { unsigned long addr; loff_t off_end = off + len; loff_t off_align = round_up(off, size); unsigned long len_pad; len_pad = len + size; ...... addr = current->mm->get_unmapped_area(filp, 0, len_pad, off >> PAGE_SHIFT, flags); addr += (off - addr) & (size - 1); return addr; }
接下来,我们再来看 mmap_region,看它如何映射这个虚拟内存区域。
unsigned long mmap_region(struct file *file, unsigned long addr,
unsigned long len, vm_flags_t vm_flags, unsigned long pgoff,
struct list_head *uf)
{
struct mm_struct *mm = current->mm;
struct vm_area_struct *vma, *prev;
struct rb_node **rb_link, *rb_parent;
/*
* Can we just expand an old mapping?
*/
vma = vma_merge(mm, prev, addr, addr + len, vm_flags,
NULL, file, pgoff, NULL, NULL_VM_UFFD_CTX);
if (vma)
goto out;
/*
* Determine the object being mapped and call the appropriate
* specific mapper. the address has already been validated, but
* not unmapped, but the maps are removed from the list.
*/
vma = kmem_cache_zalloc(vm_area_cachep, GFP_KERNEL);
if (!vma) {
error = -ENOMEM;
goto unacct_error;
}
vma->vm_mm = mm;
vma->vm_start = addr;
vma->vm_end = addr + len;
vma->vm_flags = vm_flags;
vma->vm_page_prot = vm_get_page_prot(vm_flags);
vma->vm_pgoff = pgoff;
INIT_LIST_HEAD(&vma->anon_vma_chain);
if (file) {
vma->vm_file = get_file(file);
error = call_mmap(file, vma);
addr = vma->vm_start;
vm_flags = vma->vm_flags;
}
......
vma_link(mm, vma, prev, rb_link, rb_parent);
return addr;
.....
}
-
前面我们找到了虚拟内存区域的前一个 vm_area_struct,我们首先要看,是否能够基于它进行扩展,也即调用 vma_merge,和前一个 vm_area_struct 合并到一起。
-
如果不能,就需要调用 kmem_cache_zalloc,在 Slub 里面创建一个新的 vm_area_struct 对象,设置起始和结束位置,将它加入队列。
-
如果是映射到文件,则设置 vm_file 为目标文件,调用 call_mmap。其实就是调用 file_operations 的 mmap 函数。对于 ext4 文件系统,调用的是 ext4_file_mmap。
从这个函数的参数可以看出,这一刻文件和内存开始发生关系了。这里我们将 vm_area_struct 的内存操作设置为文件系统操作,也就是说,读写内存其实就是读写文件系统。
static inline int call_mmap(struct file *file, struct vm_area_struct *vma) { return file->f_op->mmap(file, vma); } static int ext4_file_mmap(struct file *file, struct vm_area_struct *vma) { ...... vma->vm_ops = &ext4_file_vm_ops; ...... } -
如果是匿名映射,那么就不用上述的操作,就是创建一个新的 vm_area_struct 对象。
-
-
之后回到 mmap_region 函数。vma_link 函数将新创建的 vm_area_struct 挂在了 mm_struct 里面的红黑树上。
-
对于映射到文件来说,上述操作其实已经在逻辑层面建立起来了。
之后,vma_link 还做了另外一件事情,会调用 __vma_link_file,它会建立文件到内存的映射关系。对于打开的文件,会有一个结构 struct file 来表示,它有个成员指向 struct address_space 结构,这里面有棵变量名为 i_mmap 的红黑树,vm_area_struct 也会挂载到这棵树上。
struct address_space { struct inode *host; /* owner: inode, block_device */ ...... struct rb_root i_mmap; /* tree of private and shared mappings */ ...... const struct address_space_operations *a_ops; /* methods */ ...... } static void __vma_link_file(struct vm_area_struct *vma) { struct file *file; file = vma->vm_file; if (file) { struct address_space *mapping = file->f_mapping; vma_interval_tree_insert(vma, &mapping->i_mmap); } }
-
至此,内核映射完成了,但是此时并没有和物理内存发生任何关系。因为对于 mmap 来说,它只负责建立内存映射,当没有开始真正访问内存的时候,内存管理并不会给它分配物理内存,只有等真正用到内存的时候才会开始分配。这个时候会触发「用户态缺页异常」。
1.2.1.3. brk
如果我们要申请小块内存,就用 brk。brk() 系统调用将会调用的是 sys_brk() 函数,sys_brk() 的代码如下所示。
// mm\mmap.c
SYSCALL_DEFINE1(brk, unsigned long, brk)
{
unsigned long retval;
unsigned long newbrk, oldbrk;
struct mm_struct *mm = current->mm;
struct vm_area_struct *next;
......
newbrk = PAGE_ALIGN(brk);
oldbrk = PAGE_ALIGN(mm->brk);
if (oldbrk == newbrk)
goto set_brk;
/* Always allow shrinking brk. */
if (brk <= mm->brk) {
if (!do_munmap(mm, newbrk, oldbrk-newbrk, &uf))
goto set_brk;
goto out;
}
/* Check against existing mmap mappings. */
next = find_vma(mm, oldbrk);
if (next && newbrk + PAGE_SIZE > vm_start_gap(next))
goto out;
/* Ok, looks good - let it rip. */
if (do_brk_flags(oldbrk, newbrk-oldbrk, 0, &uf) < 0)
goto out;
set_brk:
mm->brk = brk;
......
return brk;
out:
retval = mm->brk;
up_write(&mm->mmap_sem);
return retval;
}
sys_brk() 将会在堆中进行连续分配,也就是说紧接在堆顶的后面分配一块内存(堆是从低地址往高地址增长的)。参数 brk 是新的堆顶位置,mm->brk 是原来堆顶的位置。
-
因此,首先是将原来的堆顶和现在的堆顶都按照页对齐,之后将对齐之后的地址进行比较。如果两者相同就说明,这次增加的量很小,还在一个页里面,不需要另行分配页,所以直接设置 mm->brk 为 brk 即可。
-
继续,此时表示已经不在一个页中了。如果发现新堆顶小于旧堆顶,那么就需要释放页,于是调用do_munmap() 将页的内存映射释放掉。
-
如果发现新堆顶大于旧堆顶,也就是要分配新的页来扩大堆。那么将会调用函数 find_vma()。这个函数是对红黑树进行查找,找到堆所在的 struct vm_area_struct 的下一个 vm_area_struct,看当前的堆顶和下一个 struct vm_area_struct 之间还能不能分配完整的页。如果不能,那就返回,因为没有内存空间可以继续使用了;如果可以,那就调用 do_brk_flags() 继续分配堆空间。
需要注意的是这里新分配的堆空间还是没有物理页与之对应的,也就是说还没有做映射,只在虚拟空间的层面上将其分配给了这个进程。等到进程第一次读取新分配的堆空间的时候,会发生缺页中断,这个时候,内核才会给新分配的堆空间分配对应的物理页。也就是说如果使用 malloc() 分配了一块新的堆空间,但是从来不访问它的话,那么新的堆空间对应的物理页是不会被分配的。
-
在 do_brk_flags() 中,find_vma_links() 找到要分配的区域对应的 struct vm_area_struct 应该位于红黑树的哪个位置(相当于先找到要插入的位置),也就是相应的前驱节点和父节点。
-
之后调用 vma_merge() 看要插入的 struct vm_area_struct 能否和现有的 struct vm_area_struct 进行合并。如果可以合并的话,那就合并咯;如果不能合并那就创建新的 struct vm_area_struct ,然后加入到链表中,也加入到红黑树中。
// mm\mmap.c static int do_brk_flags(unsigned long addr, unsigned long len, unsigned long flags, struct list_head *uf) { struct mm_struct *mm = current->mm; struct vm_area_struct *vma, *prev; struct rb_node **rb_link, *rb_parent; pgoff_t pgoff = addr >> PAGE_SHIFT; int error; ...... /* * Clear old maps. this also does some error checking for us */ while (find_vma_links(mm, addr, addr + len, &prev, &rb_link, &rb_parent)) { if (do_munmap(mm, addr, len, uf)) return -ENOMEM; } /* Check against address space limits *after* clearing old maps... */ if (!may_expand_vm(mm, flags, len >> PAGE_SHIFT)) return -ENOMEM; ...... /* Can we just expand an old private anonymous mapping? */ vma = vma_merge(mm, prev, addr, addr + len, flags, NULL, NULL, pgoff, NULL, NULL_VM_UFFD_CTX); if (vma) goto out; /* * create a vma struct for an anonymous mapping */ vma = vm_area_alloc(mm); if (!vma) { vm_unacct_memory(len >> PAGE_SHIFT); return -ENOMEM; } vma_set_anonymous(vma); vma->vm_start = addr; vma->vm_end = addr + len; vma->vm_pgoff = pgoff; vma->vm_flags = flags; vma->vm_page_prot = vm_get_page_prot(flags); vma_link(mm, vma, prev, rb_link, rb_parent); out: perf_event_mmap(vma); mm->total_vm += len >> PAGE_SHIFT; mm->data_vm += len >> PAGE_SHIFT; if (flags & VM_LOCKED) atomic_long_add(len >> PAGE_SHIFT, &mm->locked_vm); vma->vm_flags |= VM_SOFTDIRTY; return 0; } -
内存分配的原理:http://abcdxyzk.github.io/blog/2015/08/05/kernel-mm-malloc/
1.2.2. 内核态
对于内核态来说,
- kmalloc 分配的是内核的内存(内核函数,返回的地址是虚拟地址),可以分配大内存也可以分配小内存,分配大内存的时候使用伙伴系统,分配小内存的时候使用 slub 分配器(也就是将伙伴系统分配出来的大块内存切成一小块一小块进行分配)。kmalloc 分配的内存在物理内存上是连续的,一般只有在 DMA 的时候才需要物理上的连续。
- vmalloc 分配的也是内核的内存(内核函数),在虚拟内存上是连续的,但是对应的物理地址空间不一定连续,也是直接使用伙伴系统。通过 vmalloc 获得的页必须一个一个地进行映射,效率不高。因此,只在不得已时使用(一般是为了获得大块内存)。vmalloc 不能从中断上下文中进行调用,也不能从其它不允许阻塞的情况下调用。
- kmem_cache 分配小内存,则使用 slub 分配器。
需要注意的是:
- kmem_cache 和 kmalloc 的部分不会被换出,因为用这两个函数分配的内存多用于保持内核关键的数据结构。
- 内核态中 vmalloc 分配的部分会被换出,因而当访问的时候,发现不在,就会调用 do_page_fault。
1.2.2.1. vmalloc
在虚拟地址空间里面,有个 vmalloc 区域,从 VMALLOC_START 开始到 VMALLOC_END,可以用于映射一段物理内存。
vmalloc 只分配了内核的虚拟地址,所以可能会触发缺页异常。
/**
* vmalloc - allocate virtually contiguous memory
* @size: allocation size
* Allocate enough pages to cover @size from the page level
* allocator and map them into contiguous kernel virtual space.
*
* For tight control over page level allocator and protection flags
* use __vmalloc() instead.
*/
void *vmalloc(unsigned long size)
{
return __vmalloc_node_flags(size, NUMA_NO_NODE,
GFP_KERNEL);
}
static void *__vmalloc_node(unsigned long size, unsigned long align,
gfp_t gfp_mask, pgprot_t prot,
int node, const void *caller)
{
return __vmalloc_node_range(size, align, VMALLOC_START, VMALLOC_END,
gfp_mask, prot, 0, node, caller);
}
1.2.2.2. kmap_atomic
kmap_atomic 是内核的临时映射函数。从下面的代码我们可以看出,如果是 32 位有高端地址的,就需要调用 set_pte 通过内核页表进行临时映射;如果是 64 位没有高端地址的,就调用 page_address,里面会调用 lowmem_page_address,直接使用 __va 进行临时映射。
kmap_atomic 在分配的时候,如果发现没有页表,那么就会直接创建页表进行映射了。
void *kmap_atomic(struct page *page)
{
return kmap_atomic_prot(page, kmap_prot);
}
void *kmap_atomic_prot(struct page *page, pgprot_t prot)
{
......
if (!PageHighMem(page))
return page_address(page);
......
vaddr = __fix_to_virt(FIX_KMAP_BEGIN + idx);
set_pte(kmap_pte-idx, mk_pte(page, prot));
......
return (void *)vaddr;
}
static __always_inline void *lowmem_page_address(const struct page *page)
{
return page_to_virt(page);
}
#define page_to_virt(x) __va(PFN_PHYS(page_to_pfn(x)
1.3. 缺页异常
当访问未分配的虚拟页时会触发异常,内核会先判断这个虚拟页是不是在虚拟地址空间对应的 VMA(虚拟内存区域)中先区分是未分配还是已分配但未映射(在 VMA 中)。
那么当访问已分配但未映射到物理内存的虚拟页时,会触发缺页异常。调用 do_page_fault这个缺页异常处理函数(内核态和用户态都会调用这个函数)。该函数会找到一个空闲物理页(可能也会通过换页的方式),将磁盘上的数据加载到物理页中。
dotraplinkage void notrace
do_page_fault(struct pt_regs *regs, unsigned long error_code)
{
unsigned long address = read_cr2(); /* Get the faulting address */
......
__do_page_fault(regs, error_code, address);
......
}
/*
* This routine handles page faults. It determines the address,
* and the problem, and then passes it off to one of the appropriate
* routines.
*/
static noinline void
__do_page_fault(struct pt_regs *regs, unsigned long error_code,
unsigned long address)
{
struct vm_area_struct *vma;
struct task_struct *tsk;
struct mm_struct *mm;
tsk = current;
mm = tsk->mm;
if (unlikely(fault_in_kernel_space(address))) {
if (vmalloc_fault(address) >= 0)
return;
}
......
vma = find_vma(mm, address);
......
fault = handle_mm_fault(vma, address, flags);
......
1.3.1. 用户态
如果是发生在用户空间里面,则找到你访问的那个地址所在的区域 vm_area_struct,然后调用 handle_mm_fault 来映射这个区域(注意:前面用户态中是先分配了 vm_area_struct 的,只是没有真正分配物理内存而已)。
static int __handle_mm_fault(struct vm_area_struct *vma, unsigned long address,
unsigned int flags)
{
struct vm_fault vmf = {
.vma = vma,
.address = address & PAGE_MASK,
.flags = flags,
.pgoff = linear_page_index(vma, address),
.gfp_mask = __get_fault_gfp_mask(vma),
};
struct mm_struct *mm = vma->vm_mm;
pgd_t *pgd;
p4d_t *p4d;
int ret;
pgd = pgd_offset(mm, address);
p4d = p4d_alloc(mm, pgd, address);
......
vmf.pud = pud_alloc(mm, p4d, address);
......
vmf.pmd = pmd_alloc(mm, vmf.pud, address);
......
return handle_pte_fault(&vmf);
}
在这里,我们看到了分页中提到的 PGD、PUD、PMD、PTE,因为暂且不考虑五级页表,我们暂时忽略 P4G。pgd_t 用于全局页目录项,pud_t 用于上层页目录项,pmd_t 用于中间页目录项,pte_t 用于直接页表项。
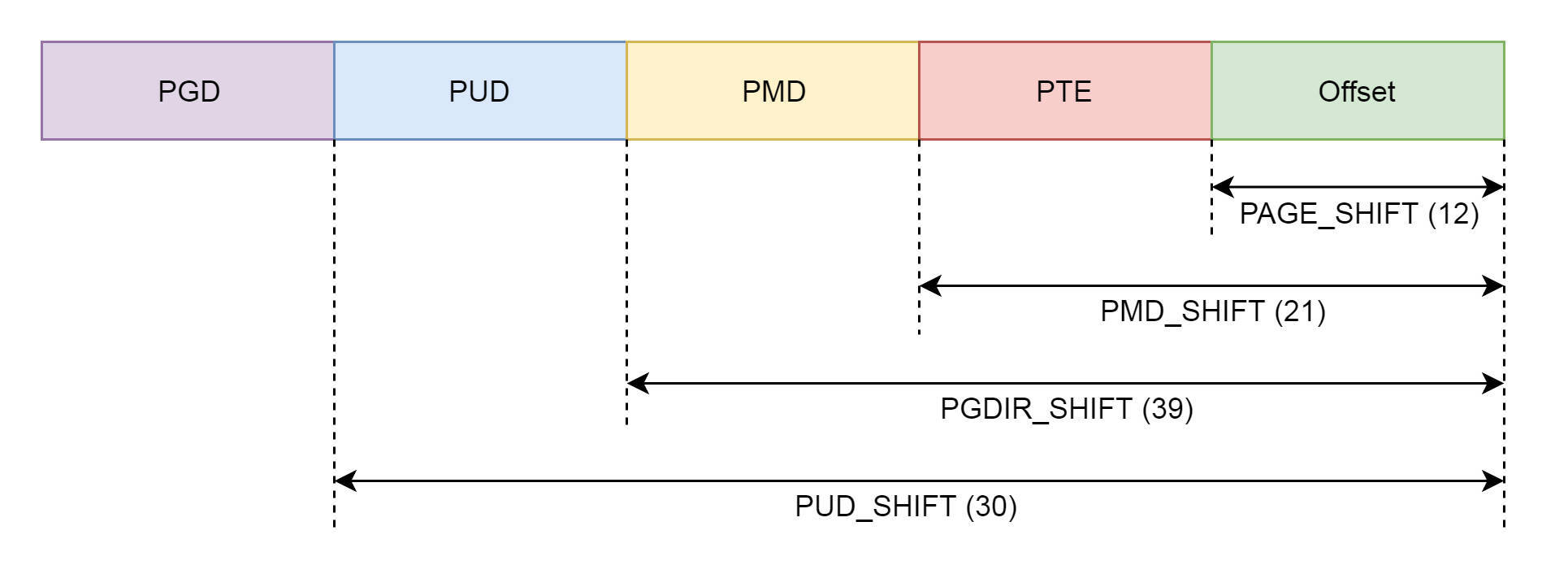
TODO:这个图画错了吧
由于页表最顶级的 pgd 存放在 task_struct 中的 mm_struct 的 pgd 变量里面,所以 __handle_mm_fault 只需要调用 pud_alloc 和 pmd_alloc,来创建相应的页目录项,最后调用 handle_pte_fault 来创建页表项,并且分配真正的物理内存。
static int handle_pte_fault(struct vm_fault *vmf)
{
pte_t entry;
......
vmf->pte = pte_offset_map(vmf->pmd, vmf->address);
vmf->orig_pte = *vmf->pte;
......
if (!vmf->pte) {
if (vma_is_anonymous(vmf->vma))
return do_anonymous_page(vmf);
else
return do_fault(vmf);
}
if (!pte_present(vmf->orig_pte))
return do_swap_page(vmf);
......
}
在这里总的来说分了三种情况:
- 如果 PTE 也就是页表项,没有出现过(表示是新映射的页),而且是匿名页的话,那么会调用 do_anonymous_page。
- 如果 PTE 也就是页表项,没有出现过(表示是新映射的页),而且是映射到文件的话,那么会调用 do_fault。
- 如果 PTE 原来出现过,说明原来页面在物理内存中,后来换出到硬盘了,现在应该换回来,调用的是 do_swap_page(可能是 swap 空间也可能是直接换出到文件)。
1.3.1.1. 未映射并且是匿名页
static int do_anonymous_page(struct vm_fault *vmf)
{
struct vm_area_struct *vma = vmf->vma;
struct mem_cgroup *memcg;
struct page *page;
int ret = 0;
pte_t entry;
......
if (pte_alloc(vma->vm_mm, vmf->pmd, vmf->address))
return VM_FAULT_OOM;
......
page = alloc_zeroed_user_highpage_movable(vma, vmf->address);
......
entry = mk_pte(page, vma->vm_page_prot);
if (vma->vm_flags & VM_WRITE)
entry = pte_mkwrite(pte_mkdirty(entry));
vmf->pte = pte_offset_map_lock(vma->vm_mm, vmf->pmd, vmf->address,
&vmf->ptl);
......
set_pte_at(vma->vm_mm, vmf->address, vmf->pte, entry);
......
}
- 对于匿名页的映射,我们需要先通过 pte_alloc 分配一个页表项;
- 然后通过 alloc_zeroed_user_highpage_movable 分配一个页。之后它会调用 alloc_pages_vma,并最终调用 __alloc_pages_nodemask。而这个函数则是伙伴系统的核心函数,专门用来分配物理页面的。
- do_anonymous_page 接下来要调用 mk_pte,将页表项指向新分配的物理页;
- set_pte_at 会将页表项塞到页表里面。
1.3.1.2. 未映射并且是映射文件
第二种情况映射到文件 do_fault,最终会调用 __do_fault。
static int __do_fault(struct vm_fault *vmf)
{
struct vm_area_struct *vma = vmf->vma;
int ret;
......
ret = vma->vm_ops->fault(vmf);
......
return ret;
}
static const struct vm_operations_struct ext4_file_vm_ops = {
.fault = ext4_filemap_fault,
.map_pages = filemap_map_pages,
.page_mkwrite = ext4_page_mkwrite,
};
int ext4_filemap_fault(struct vm_fault *vmf)
{
struct inode *inode = file_inode(vmf->vma->vm_file);
......
err = filemap_fault(vmf);
......
return err;
}
在 mmap 映射文件的时候,对于 ext4 文件系统,vma->vm_ops 指向了 ext4_file_vm_ops。那么,这里调用 fault 的函数其实调用的是 struct vm_operations_struct vm_ops 的 fault 函数,也就是 ext4_filemap_fault。ext4_filemap_fault 函数里:
- vmf->vma->vm_file 就是在 mmap 时候,映射的那个文件;
- 之后就是调用 filemap_fault。
int filemap_fault(struct vm_fault *vmf)
{
int error;
struct file *file = vmf->vma->vm_file;
struct address_space *mapping = file->f_mapping;
struct inode *inode = mapping->host;
pgoff_t offset = vmf->pgoff;
struct page *page;
int ret = 0;
......
page = find_get_page(mapping, offset);
if (likely(page) && !(vmf->flags & FAULT_FLAG_TRIED)) {
do_async_mmap_readahead(vmf->vma, ra, file, page, offset);
} else if (!page) {
goto no_cached_page;
}
......
vmf->page = page;
return ret | VM_FAULT_LOCKED;
no_cached_page:
error = page_cache_read(file, offset, vmf->gfp_mask);
......
}
-
对于文件映射来说,一般这个文件在物理内存里面有它的缓存,find_get_page 就是找那个页。如果找到了,就调用 do_async_mmap_readahead,预读一些数据到内存里面;如果没有,就跳到 no_cached_page。
-
跳转到 no_cached_page 之后,会调用 page_cache_read。
在这里显示分配一个缓存页,将这一页加到 lru 表里面,然后在 address_space 中调用address_space_operations 的 readpage 函数,将文件内容读到内存中。address_space 之前介绍过了。
static int page_cache_read(struct file *file, pgoff_t offset, gfp_t gfp_mask) { struct address_space *mapping = file->f_mapping; struct page *page; ...... page = __page_cache_alloc(gfp_mask|__GFP_COLD); ...... ret = add_to_page_cache_lru(page, mapping, offset, gfp_mask & GFP_KERNEL); ...... ret = mapping->a_ops->readpage(file, page); ...... }struct address_space_operations 对于 ext4 文件系统的定义如下所示。那么,上面的 readpage 调用的其实是 ext4_readpage。而 ext4_readpage 最后会调用 ext4_read_inline_page,这里面有部分逻辑和内存映射有关。
static const struct address_space_operations ext4_aops = { .readpage = ext4_readpage, .readpages = ext4_readpages, ...... }; static int ext4_read_inline_page(struct inode *inode, struct page *page) { void *kaddr; ...... kaddr = kmap_atomic(page); ret = ext4_read_inline_data(inode, kaddr, len, &iloc); flush_dcache_page(page); kunmap_atomic(kaddr); ...... }- 在 ext4_read_inline_page 函数里,我们需要先调用 kmap_atomic,将物理内存映射到内核的虚拟地址空间,得到内核中的地址 kaddr。kmap_atomic,它是用来做临时内核映射的。本来把物理内存映射到用户虚拟地址空间,不需要在内核里面映射一把。但是,现在因为要从文件里面读取数据并写入这个物理页面,又不能使用物理地址,我们只能使用虚拟地址,这就需要在内核里面临时映射一把。
- 临时映射后,ext4_read_inline_data 读取文件到这个虚拟地址。
- 读取完毕后,我们取消这个临时映射 kunmap_atomic 就行了。
1.3.1.3. 换出到硬盘
第三种情况,do_swap_page。在物理内存管理那里,我们曾经提过如果有些内存长时间不用,就要换出到硬盘,对于匿名内存来说是换到 swap 文件,对于文件映射来说是直接换到文件中。那么,当这部分数据又要访问的时候,我们还需要将其再次读取到内存中。
int do_swap_page(struct vm_fault *vmf)
{
struct vm_area_struct *vma = vmf->vma;
struct page *page, *swapcache;
struct mem_cgroup *memcg;
swp_entry_t entry;
pte_t pte;
......
entry = pte_to_swp_entry(vmf->orig_pte);
......
page = lookup_swap_cache(entry);
if (!page) {
page = swapin_readahead(entry, GFP_HIGHUSER_MOVABLE, vma,
vmf->address);
......
}
......
swapcache = page;
......
pte = mk_pte(page, vma->vm_page_prot);
......
set_pte_at(vma->vm_mm, vmf->address, vmf->pte, pte);
vmf->orig_pte = pte;
......
swap_free(entry);
......
}
do_swap_page 函数会先查找 swap 文件有没有缓存页。如果没有,就调用 swapin_readahead,将 swap 文件读到内存中来,形成内存页,并通过 mk_pte 生成页表项。set_pte_at 将页表项插入页表,swap_free 将 swap 文件清理。因为重新加载回内存了,不再需要 swap 文件了。
而 swapin_readahead 会最终调用 swap_readpage,在这里,我们看到了熟悉的 readpage 函数,也就是说读取普通文件和读取 swap 文件,过程是一样的,同样需要用 kmap_atomic 做临时映射。
int swap_readpage(struct page *page, bool do_poll)
{
struct bio *bio;
int ret = 0;
struct swap_info_struct *sis = page_swap_info(page);
blk_qc_t qc;
struct block_device *bdev;
......
if (sis->flags & SWP_FILE) {
struct file *swap_file = sis->swap_file;
struct address_space *mapping = swap_file->f_mapping;
ret = mapping->a_ops->readpage(swap_file, page);
return ret;
}
......
}
通过上面的过程,用户态缺页异常处理完毕了。物理内存中有了页面,页表也建立好了映射。用户程序从出错的地方继续运行的时候,可以通过虚拟地址顺利经过页表转换,从而访问到了物理页面上的数据了。
1.3.1.4. 总结
在用户态访问没有映射的内存会引发缺页异常,分配物理页表、补齐页表。

1.3.2. 内核态
内核态的缺页异常还是会调用 do_page_fault。而在 __do_page_fault 里面,也会先判断缺页中断是否发生在内核。如果发生在内核则调用 vmalloc_fault。vmalloc_fault 这个函数主要用于关联内核页表项。
/*
* 32-bit:
*
* Handle a fault on the vmalloc or module mapping area
*/
static noinline int vmalloc_fault(unsigned long address)
{
unsigned long pgd_paddr;
pmd_t *pmd_k;
pte_t *pte_k;
/* Make sure we are in vmalloc area: */
if (!(address >= VMALLOC_START && address < VMALLOC_END))
return -1;
/*
* Synchronize this task's top level page-table
* with the 'reference' page table.
*
* Do _not_ use "current" here. We might be inside
* an interrupt in the middle of a task switch..
*/
pgd_paddr = read_cr3_pa();
pmd_k = vmalloc_sync_one(__va(pgd_paddr), address);
if (!pmd_k)
return -1;
pte_k = pte_offset_kernel(pmd_k, address);
if (!pte_present(*pte_k))
return -1;
return 0
}
1.3.3. 总结(虚拟内存管理和缺页异常)
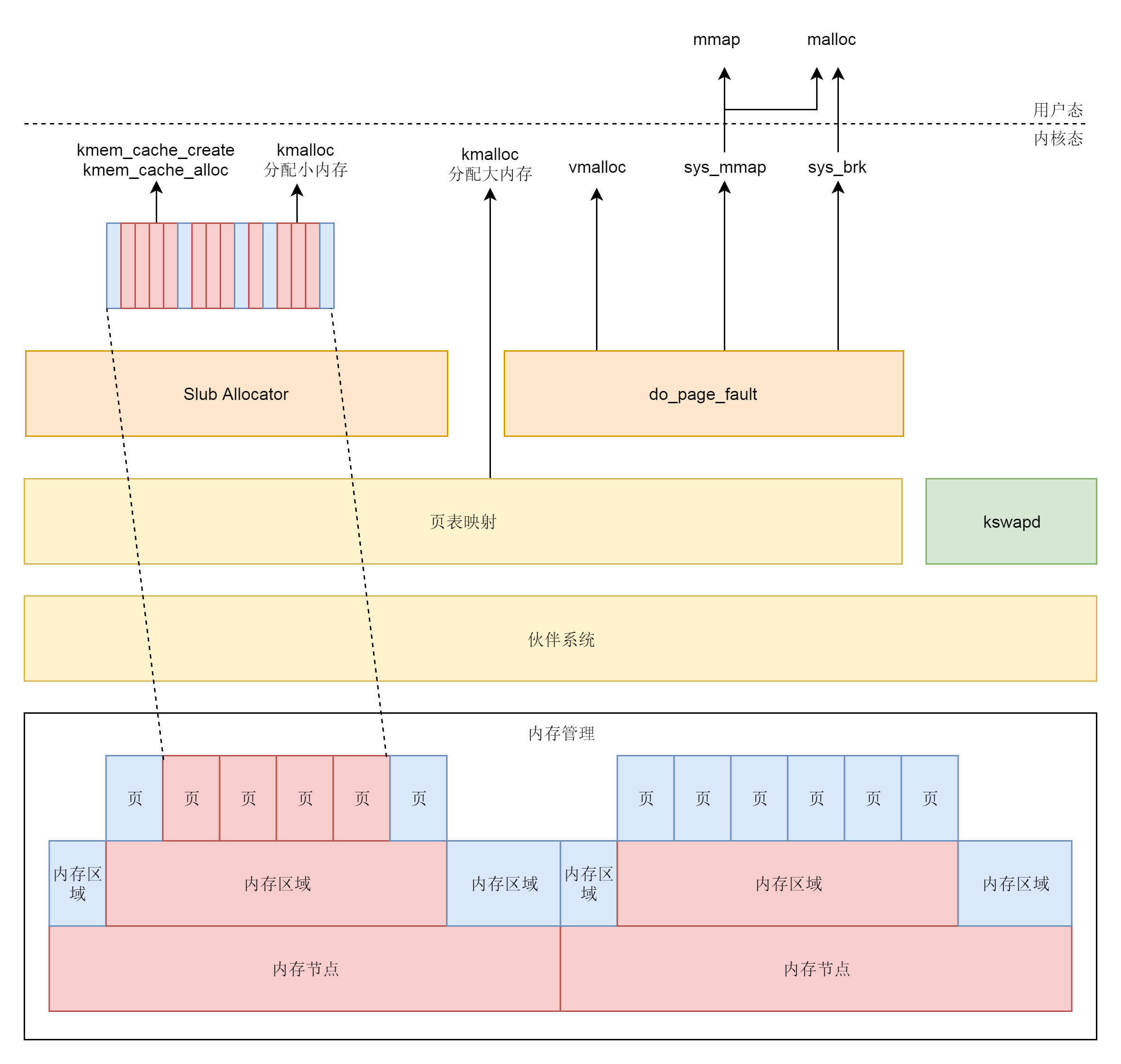
1.4. Linux 内存类型
Linux 的各个模块都需要内存,比如内核需要分配内存给页表、内核栈、slab、inode、dentry;用户态进程里的堆内存、栈内存、共享库的内存,还有文件读写的 Page Cache。
与用户态相关的两个内存类型,RSS 和 Page Cache:
-
RSS 是 Resident Set Size 的缩写,简单来说它就是指进程真正申请到物理页面的内存大小,RSS 内存包含了进程的代码段内存,栈内存,堆内存,共享库的内存, 这些内存是进程运行所必须的。需要注意通过 malloc 申请到的内存并不会算到 RSS 中,因为 malloc 这时候并没有真正申请到物理页面的内存大小。但是当使用 memset 进行初始化的时候,就会申请物理内存,而申请到的这部分物理内存就会算到 RSS 中。
具体的每一部分的 RSS 内存的大小,可以查看 /proc/[pid]/smaps 文件。
-
Page Cache,每个进程除了各自独立分配到的 RSS 内存外,如果进程对磁盘上的文件做了读写操作,Linux 还会分配内存,把磁盘上读写到的页面存放在内存中,这部分的内存就是 Page Cache。Page Cache 的主要作用是利用物理内存来提高磁盘文件的读写性能。在 Linux 系统里只要有空闲的内存,系统就会自动地把读写过的磁盘文件页面放入到 Page Cache 里(系统调用 read() 和 write() 的缺省行为)。
当这些内存都被 Page Cache 占用时,而进程需要用到更多的物理内存的时候将会启用内存页面回收机制(page frame reclaim)。Linux 内存管理的内存页面回收机制,会根据系统里空闲物理内存是否低于某个阈值(wartermark),来决定是否启动内存的回收。内存回收的算法会根据不同类型的内存以及内存的 LRU(Least Recently Used)算法决定哪些内存页面先被释放。由于 Page Cache 只是起到 Cache 的作用,所以它的回收并不会影响程序的正常运行,所以将会被优先释放。那么空出来的内存又可以分配给新的内存申请了。
1.4.1. OOM killer
OOM 是 Out of Memory 的缩写,顾名思义就是内存不足的意思,而 Killer 在这里指需要杀死某个进程。那么 OOM Killer 就是在 Linux 系统里如果内存不足时,需要杀死一个正在运行的进程来释放一些内存。
Linux 里的程序都是调用 malloc() 来申请内存,并且在申请内存的时候是 overcommit 的,也就是说允许进程申请超过实际物理内存上线的内存。比如,节点上的空闲物理内存只有 512MB 了,但是如果一个进程调用 malloc() 申请了 600MB,那么 malloc() 的这次申请还是被允许的。这个是因为,malloc() 申请的是内存的虚拟地址,系统只是给了程序一个地址范围,由于没有写入数据,所以程序并没有得到真正的物理内存。物理内存只有程序真的往这个地址写入数据的时候,才会分配给程序。
overcommit 的内存申请模式带来的一个好处就是它可以有效提高系统的内存利用率(理解:我申请了 100M,但是实际可能只会用到 50MB,所以采用这种方式的话,不会分配 100MB 的物理内存,而是只分配用到了的 50MB 内存)。但是,overcommit 的内存申请模式也会带来一个问题,那就是当物理内存真的不够用的时候,Linux 会杀死某个正在运行的进程。
那么杀死哪个正在运行的进程将由内核中的 oom_badness() 函数决定。这个函数涉及到两个条件:
- 第一,进程已经使用的物理内存页面数。
- 第二,每个进程的 OOM 校准值 oom_score_adj。在 /proc 文件系统中,每个进程都有一个 /proc/<pid>/oom_score_adj 的接口文件。我们可以在这个文件中输入 -1000 到 1000 之间的任意一个数值,调整进程被 OOM Kill 的几率。
adj = (long)p->signal->oom_score_adj;
points = get_mm_rss(p->mm) + get_mm_counter(p->mm, MM_SWAPENTS) +mm_pgtables_bytes(p->mm) / PAGE_SIZE;
adj *= totalpages / 1000;
points += adj;
最终计算方法是这样的:用系统总的可用页面数,去乘以 OOM 校准值 oom_score_adj,然后再除以 1000。最后,再加上进程已经使用的物理页面数,计算出来的值越大,那么这个进程被 OOM Kill 的几率也就越大。
在早期内核版本里使用oom_adj, 后来改用oom_socre_adj了。不过为了兼容一些老的应用程序,oom_adj还保留着。
1.4.2. swappiness 参数
前面说到,在有磁盘文件访问的时候,Linux 会尽量把系统的空闲内存用作 Page Cache 来提高文件的读写性能。在没有打开 Swap 空间的情况下,一旦内存不够,这种情况下就只能把 Page Cache 释放了,而 RSS 内存是不能释放的。而在 RSS 里的内存,大部分都是没有对应磁盘文件的内存,比如用 malloc() 申请得到的内存,它们就没有对应磁盘文件,而这种内存也被称为匿名内存(Anonymous memory)。那么当 Swap 空间打开后,这些匿名内存可以写入 Swap 空间。
那么在 Swap 空间打开的时候,在内存紧张的时候,Linux 系统有两种方式来缓解内存紧张,一种是释放 page cache,另一种是将 anon-rss 存到 swap 空间中。那 Linux 系统怎么决定是先释放 Page Cache,还是先把匿名内存释放并写入到 Swap 空间里呢?
这个时候需要用到 swappiness 这个参数了,这个参数的值可以通过 proc 文件系统下的 /proc/sys/vm/swappiness 进行设置,参数的取值在 0-100 之间,缺省值是 60。除了 swappiness 这个参数之外,还会有一个参数 file_prio。这两个参数像是一个权重决定了匿名内存和 page cache 的一个释放比例问题。在下面的代码中 anon_prio 的值就等于 swappiness。
/*
* With swappiness at 100, anonymous and file have the same priority.
* This scanning priority is essentially the inverse of IO cost.
*/
anon_prio = swappiness;
file_prio = 200 - anon_prio;
下面我们分三种情况进行讨论:
-
当 anon_prio 的值为 100 的时候,anon_prio:file_prio=100:100,匿名内存和 page cache 内存的释放比例就是 100:100,相当于等比例释放。
-
第二种情况,就是 swappiness 缺省值是 60 的时候,匿名内存和 Page Cache 内存的释放比例就是 60 : 140,Page Cache 内存的释放要优先于匿名内存。
-
第三种当 swappiness 的值等于 0 时,并不会不允许匿名内存写入 swap 空间了。当空闲内存少于内存一个 zone 的“high water mark”中的值的时候(这个值表示剩余内存的大小),Linux 还是会把匿名内存写入到 swap 空间后释放内存。这里的 zone 是 Linux 划分物理内存的一个区域,里面有 3 个水位线(water mark):high、low、min,这些水位线可以用来警示空闲内存的紧张程度,其中 high 是剩余内存最多的。
可以做下面这个实验:
-
实验的节点上内存有 12GB,同时有 2GB 的 Swap

-
接下去运行 echo 0 > /proc/sys/vm/swappiness 命令把 swappiness 设置为 0。同时用 mem_alloc 申请 12GB 的内存,我们可以看到 swap 空间就被使用了。这个是因为申请的 12GB 内存已经和节点最大内存差不多了,会触发水位线,还是会将匿名内存写到 swap 中。

-
接下去查看 cat /proc/zoneinfo ,也可以看到 normal zone 里 high (water mark)的值和 free 的值差不多,但是 free > high,这表示不会触发 swap。

-
综上来说,swappiness 的取值范围在 0 到 100,值为 100 的时候系统平等回收匿名内存和 Page Cache 内存;一般缺省值为 60,就是优先回收 Page Cache;即使 swappiness 为 0,也不能完全禁止 Swap 分区的使用,就是说在内存紧张的时候,也会使用 Swap 来回收匿名内存。

