1. 分段和分页
1.1. 分段机制
分段机制下的虚拟地址由两部分组成,段选择子和段内偏移量。段选择子就保存在段寄存器里面。段选择子里面最重要的是段号,用作段表的索引。段表里面保存的是这个段的基地址、段的界限和特权等级。段基地址加上段内偏移量就得到了物理内存地址。

在 Linux 里面,段表全称段描述符表(segment description),放在全局描述符表 GDT(Global Descriptor Table)里面。会有下面这些代码来对段表进行初始化,主要就是对内核代码段、内核数据段、用户代码段、用户数据段的段基地址 base、段界限 limit 还有一些标识符进行初始化。
// arch\x86\kernel\cpu\common.c
DEFINE_PER_CPU_PAGE_ALIGNED(struct gdt_page, gdt_page) = { .gdt = {
#ifdef CONFIG_X86_64
[GDT_ENTRY_KERNEL32_CS] = GDT_ENTRY_INIT(0xc09b, 0, 0xfffff),
[GDT_ENTRY_KERNEL_CS] = GDT_ENTRY_INIT(0xa09b, 0, 0xfffff),
[GDT_ENTRY_KERNEL_DS] = GDT_ENTRY_INIT(0xc093, 0, 0xfffff),
[GDT_ENTRY_DEFAULT_USER32_CS] = GDT_ENTRY_INIT(0xc0fb, 0, 0xfffff),
[GDT_ENTRY_DEFAULT_USER_DS] = GDT_ENTRY_INIT(0xc0f3, 0, 0xfffff),
[GDT_ENTRY_DEFAULT_USER_CS] = GDT_ENTRY_INIT(0xa0fb, 0, 0xfffff),
#else
[GDT_ENTRY_KERNEL_CS] = GDT_ENTRY_INIT(0xc09a, 0, 0xfffff),
[GDT_ENTRY_KERNEL_DS] = GDT_ENTRY_INIT(0xc092, 0, 0xfffff),
[GDT_ENTRY_DEFAULT_USER_CS] = GDT_ENTRY_INIT(0xc0fa, 0, 0xfffff),
[GDT_ENTRY_DEFAULT_USER_DS] = GDT_ENTRY_INIT(0xc0f2, 0, 0xfffff),
/* 32-bit code */
[GDT_ENTRY_PNPBIOS_CS32] = GDT_ENTRY_INIT(0x409a, 0, 0xffff),
/* 16-bit code */
[GDT_ENTRY_PNPBIOS_CS16] = GDT_ENTRY_INIT(0x009a, 0, 0xffff),
/* 16-bit data */
[GDT_ENTRY_PNPBIOS_DS] = GDT_ENTRY_INIT(0x0092, 0, 0xffff),
/* 16-bit data */
[GDT_ENTRY_PNPBIOS_TS1] = GDT_ENTRY_INIT(0x0092, 0, 0),
/* 16-bit data */
[GDT_ENTRY_PNPBIOS_TS2] = GDT_ENTRY_INIT(0x0092, 0, 0),
/* 32-bit code */
[GDT_ENTRY_APMBIOS_BASE] = GDT_ENTRY_INIT(0x409a, 0, 0xffff),
/* 16-bit code */
[GDT_ENTRY_APMBIOS_BASE+1] = GDT_ENTRY_INIT(0x009a, 0, 0xffff),
/* data */
[GDT_ENTRY_APMBIOS_BASE+2] = GDT_ENTRY_INIT(0x4092, 0, 0xffff),
[GDT_ENTRY_ESPFIX_SS] = GDT_ENTRY_INIT(0xc092, 0, 0xfffff),
[GDT_ENTRY_PERCPU] = GDT_ENTRY_INIT(0xc092, 0, 0xfffff),
GDT_STACK_CANARY_INIT
#endif
} };
// arch\x86\include\asm\desc_defs.h
#define GDT_ENTRY_INIT(flags, base, limit) \
{ \
.limit0 = (u16) (limit), \
.limit1 = ((limit) >> 16) & 0x0F, \
.base0 = (u16) (base), \
.base1 = ((base) >> 16) & 0xFF, \
.base2 = ((base) >> 24) & 0xFF, \
.type = (flags & 0x0f), \
.s = (flags >> 4) & 0x01, \
.dpl = (flags >> 5) & 0x03, \
.p = (flags >> 7) & 0x01, \
.avl = (flags >> 12) & 0x01, \
.l = (flags >> 13) & 0x01, \
.d = (flags >> 14) & 0x01, \
.g = (flags >> 15) & 0x01, \
}
另外,内核中还有相应段选择子的值指向上面的段描述符表项。这在启动第一个用户态进程的时候,会将这四个值分别赋值给相应的段寄存器。
// arch\x86\include\asm\segment.h
#define __KERNEL_CS (GDT_ENTRY_KERNEL_CS*8)
#define __KERNEL_DS (GDT_ENTRY_KERNEL_DS*8)
#define __USER_DS (GDT_ENTRY_DEFAULT_USER_DS*8 + 3)
#define __USER_CS (GDT_ENTRY_DEFAULT_USER_CS*8 + 3)
#define __ESPFIX_SS (GDT_ENTRY_ESPFIX_SS*8)
但是,通过上述的初始化我们可以看到,所以段的起始地址都是一样的,都是 0。那么相当于 Linux 中并没有使用到全部的分段功能,这里的分段功能仅剩下权限审核,例如用户态 DPL 是 3,内核态 DPL 是 0。当用户态试图访问内核态的时候,会因为权限不足而报错。
1.2. 分页机制
Linux 并没有使用分段机制,而是使用分页机制将虚拟地址转换为物理地址。分页机制中,操作系统把物理内存分成一块一块大小相同的页,页的大小一般为 4KB。为了能够定位和访问每个页,需要有个页表,保存每个页的起始地址(物理地址),之后加上页内的偏移量就得到了需要访问的物理地址。
这个时候,虚拟地址分为两部分,页号和页内偏移。页号作为页表的索引,页表包含物理页每页所在物理内存的基地址。这个基地址与页内偏移的组合就形成了物理内存地址。

1.2.1. x86 32 位系统中使用两级页表来实现虚拟地址到物理地址的转换
在 32 位系统中,两级页表分别称为页目录表和页表。页目录有 1k 项,那么 32 位中的前 10 位就是用来定位到页目录表中的一项,而这一项其实对应的是一页的页表项;每个页表项是 4 bytes,所以一页的页表项是 1k 个,再根据中间 10 位,在这 1k 页表项中找到相应的页表项,这个页表项中记录了数据页的物理地址等信息,对应的就是一个页(存放数据的页);最后这个页的物理地址加上页内偏移就得到了真正的物理地址。
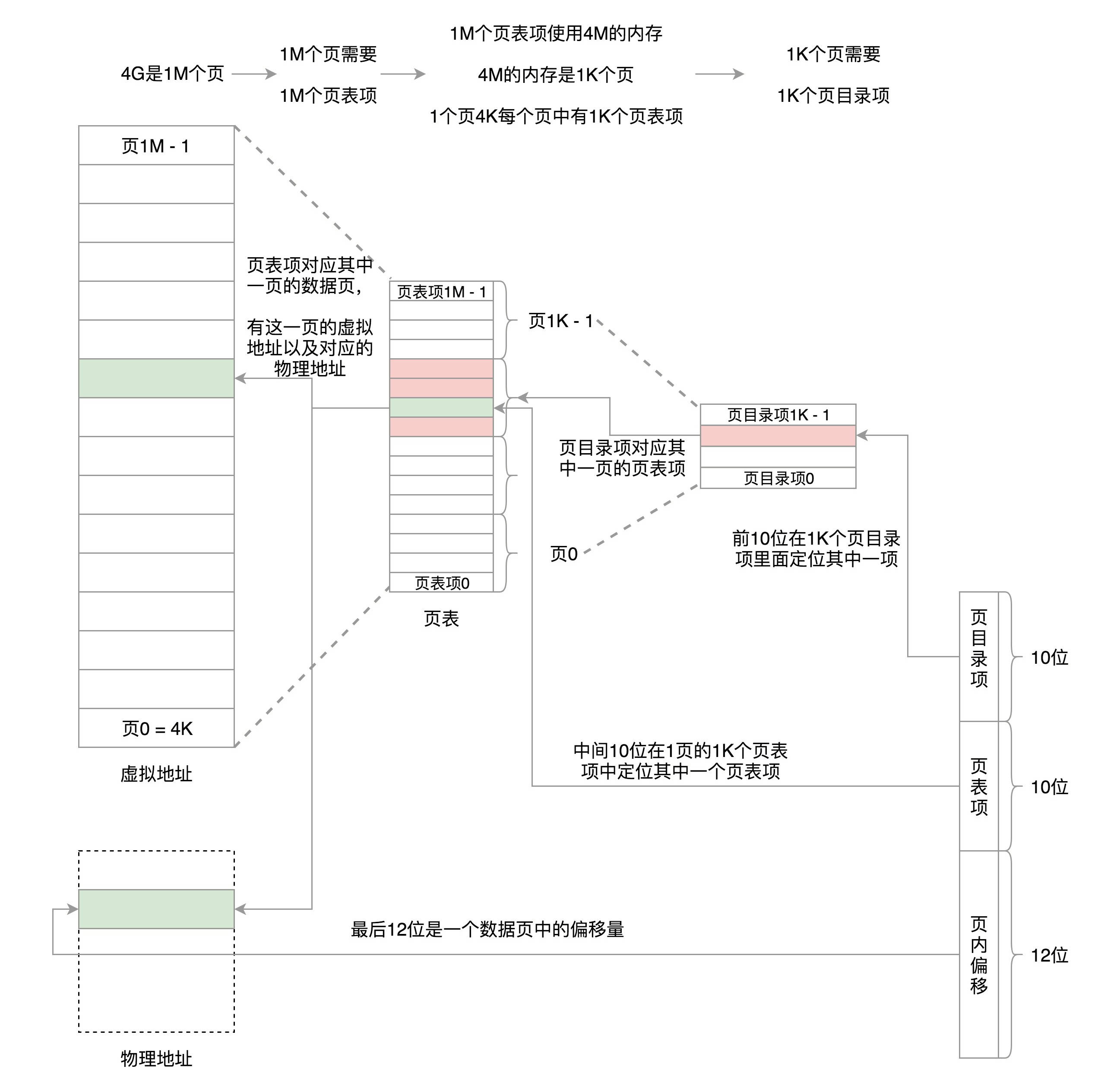
假如采用一级页表,32 位环境下,虚拟地址空间共 4GB。如果分成 4KB 一个页,那就是 1M 个页。每个页表项需要 4 个字节来存储,那么整个 4GB 空间的映射就需要 4MB 的内存来存储映射表。如果每个进程都有自己的映射表,100 个进程就需要 400MB 的内存。对于内核来讲,有点大了 。
并且采用一级页表之后,页表中所有页表项必须提前建好,并且要求是连续的。如果不连续,就没有办法通过虚拟地址里面的页号找到对应的页表项了。
虽然映射 4GB 地址空间需要 4MB+4KB 的内存,但是这种情况只存在 4GB 的内存空间都被分配完了,而一个进程往往不会分配这么多内存。那么这个时候,二级页表的好处就显示出来啦,它可以节省页表所占内存。考虑极端情况,只给这个进程分配了一个数据页,那么其实只需要 4KB 的页目录项和 4KB 的页表项即可。
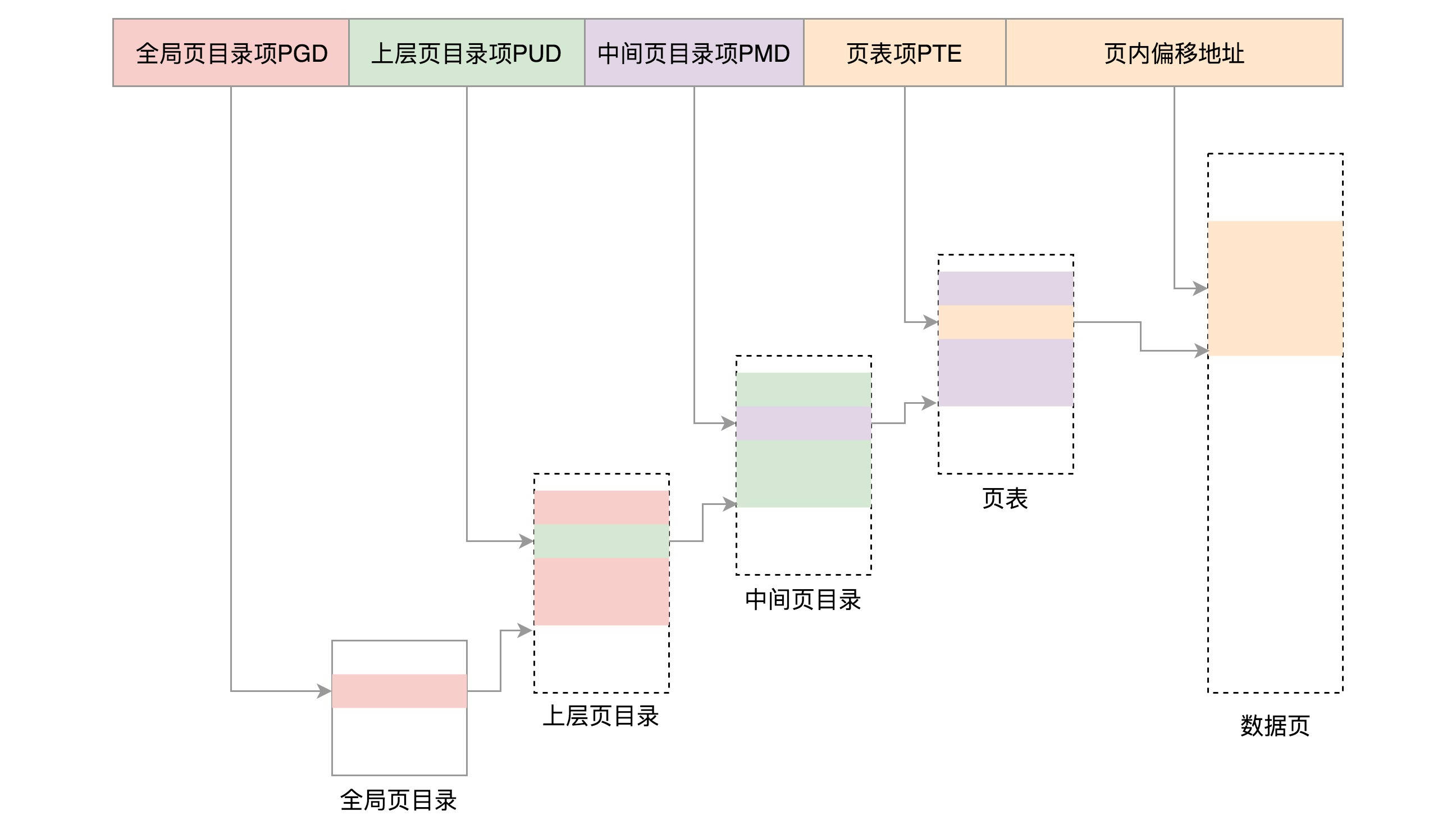
1.2.2. x86 64 位系统中使用四级页表来实现虚拟地址到物理地址的转换
对于 64 位的系统来说,两级页表肯定是不够的,需要使用四级,分别是全局页目录项 PGD(Page Global Directory)、上层页目录项 PUD(Page Upper Directory)、中间页目录项 PMD(Page Middle Directory)和页表项 PTE(Page Table Entry)。
由于 x86_64 处理器硬件限制,x86_64 处理器地址线只有 48 位,从而导致硬件要求传入的地址 48 位到 63 位必须相同。以 4K 为单位的页中,位宽度分别是 9、9、9、9、12。
1.3. 分段、分页比较
-
分页机制更方便管理,例如有的内存页面长时间不用了,可以暂时写到硬盘上,称为换出。一旦需要的时候,再加载进来,叫做换入。这样可以扩大可用物理内存的大小,提高物理内存的利用率。
所以说,分段容易产生碎片,并且不容易换入换出。
-
对程序员的透明性:分页透明,但是分段需要程序员显式划分每个段。
-
地址空间的维度:分页是一维地址空间,分段是二维的。
-
大小是否可以改变:页的大小不可变,段的大小可以动态改变。
-
出现的原因:分页主要用于实现虚拟内存,从而获得更大的地址空间;分段主要是为了使程序和数据可以被划分为逻辑上独立的地址空间并且有助于共享和保护。
2. 页表
每个进程都有独立的地址空间,因此每个进程都有独立的进程页表,这个页表的最顶级的 pgd 存放在 task_struct 中的 mm_struct 的 pgd 变量里面。
2.1. 进程页表的创建
在一个进程新创建的时候,会调用 fork,对于内存部分来说,它会调用 copy_mm,而这里会调用 dup_mm。
/*
* Allocate a new mm structure and copy contents from the
* mm structure of the passed in task structure.
*/
static struct mm_struct *dup_mm(struct task_struct *tsk)
{
struct mm_struct *mm, *oldmm = current->mm;
mm = allocate_mm();
memcpy(mm, oldmm, sizeof(*mm));
if (!mm_init(mm, tsk, mm->user_ns))
goto fail_nomem;
err = dup_mmap(mm, oldmm);
return mm;
}
- 在这里会先创建一个新的 mm_struct;
- 然后通过 memcpy 将父进程的 mm 都复制过来,也就是父子进程是一模一样的;
- 最后会调用 mm_init 进行初始化。而 mm_init 调用 mm_alloc_pgd。在 mm_alloc_pgd 里会调用 pgd_alloc 分配全局页目录项,赋值给 mm_struct 的 pgd 成员变量。
static inline int mm_alloc_pgd(struct mm_struct *mm)
{
mm->pgd = pgd_alloc(mm);
return 0;
}
而 pgd_alloc 里面除了分配 PGD 之外,还做了很重要的一个事情,就是调用 pgd_ctor。
static void pgd_ctor(struct mm_struct *mm, pgd_t *pgd)
{
/* If the pgd points to a shared pagetable level (either the
ptes in non-PAE, or shared PMD in PAE), then just copy the
references from swapper_pg_dir. */
if (CONFIG_PGTABLE_LEVELS == 2 ||
(CONFIG_PGTABLE_LEVELS == 3 && SHARED_KERNEL_PMD) ||
CONFIG_PGTABLE_LEVELS >= 4) {
clone_pgd_range(pgd + KERNEL_PGD_BOUNDARY,
swapper_pg_dir + KERNEL_PGD_BOUNDARY,
KERNEL_PGD_PTRS);
}
......
}
在 pgd_ctor 中,它拷贝了对于 swapper_pg_dir 的引用。swapper_pg_dir 是内核页表的最顶级的全局页目录。这里需要拷贝内核页表最顶级的全局页目录是因为一个进程的虚拟地址空间包含用户态和内核态两部分。为了从虚拟地址空间映射到物理页面,页表也分为用户地址空间的页表和内核页表。当进程进入内核态之后,映射就是靠内核页表(系统调用不会改变 CR3 寄存器的值)。
至此,当一个进程 fork 完毕之后,有了内核页表,有了自己顶级的 PGD。
2.2. 进程页表的切换
当这个进程被调度到某个 CPU 上运行的时候,会调用 context_switch 进行上下文切换。对于内存方面的切换会调用 switch_mm_irqs_off,这里面会调用 load_new_mm_cr3。
cr3 是 CPU 的一个寄存器,它会存着当前进程的顶级 pgd 的物理地址。如果 CPU 的指令要访问进程的虚拟内存,它就会自动从 cr3 里面得到 pgd 在物理内存的地址,然后根据里面的页表解析虚拟内存的地址为物理内存,从而访问真正的物理内存上的数据。这里需要注意两点:
- 第一点,cr3 里面存放的是当前进程的顶级 pgd,这个是硬件的要求。cr3 里面需要存放 pgd 在物理内存的地址,不能是虚拟地址。因而 load_new_mm_cr3 里面会使用 __pa,将 mm_struct 里面的成员变量 pgd(mm_struct 里面存的都是虚拟地址)变为物理地址,才能加载到 cr3 里面去。
- 第二点,用户进程在用户态运行时,访问虚拟内存中的数据,会被 cr3 里面指向的页表转换为物理地址后,才在物理内存中访问数据,这个过程都是在用户态运行的,地址转换的过程无需进入内核态。
2.3. 内核页表
内核页表中构建的内核空间布局如下所示(详细可以看「虚拟内存管理」)

在系统初始化的时候,就需要创建内核页表了。内核页表最顶级的目录(pgd)是 swapper_pg_dir。剩下的 XXX_ident_pgt 对应的是直接映射区,XXX_kernel_pgt 对应的是内核代码区,XXX_fixmap_pgt 对应的是固定映射区。可以在 arch/x86/include/asm/pgtable_64.h 中找到它们的定义。
// arch/x86/include/asm/pgtable_64.h
extern pud_t level3_kernel_pgt[512];
extern pud_t level3_ident_pgt[512];
extern pmd_t level2_kernel_pgt[512];
extern pmd_t level2_fixmap_pgt[512];
extern pmd_t level2_ident_pgt[512];
extern pte_t level1_fixmap_pgt[512];
extern pgd_t init_top_pgt[];
#define swapper_pg_dir init_top_pgt
这个页表定义的过程可以看汇编语言的文件里面的 arch\x86\kernel\head_64.S。
// arch\x86\kernel\head_64.S
__INITDATA
NEXT_PAGE(init_top_pgt)
.quad level3_ident_pgt - __START_KERNEL_map + _KERNPG_TABLE
.org init_top_pgt + PGD_PAGE_OFFSET*8, 0
.quad level3_ident_pgt - __START_KERNEL_map + _KERNPG_TABLE
.org init_top_pgt + PGD_START_KERNEL*8, 0
/* (2^48-(2*1024*1024*1024))/(2^39) = 511 */
.quad level3_kernel_pgt - __START_KERNEL_map + _PAGE_TABLE
NEXT_PAGE(level3_ident_pgt)
.quad level2_ident_pgt - __START_KERNEL_map + _KERNPG_TABLE
.fill 511, 8, 0
NEXT_PAGE(level2_ident_pgt)
/* Since I easily can, map the first 1G.
* Don't set NX because code runs from these pages.
*/
PMDS(0, __PAGE_KERNEL_IDENT_LARGE_EXEC, PTRS_PER_PMD)
NEXT_PAGE(level3_kernel_pgt)
.fill L3_START_KERNEL,8,0
/* (2^48-(2*1024*1024*1024)-((2^39)*511))/(2^30) = 510 */
.quad level2_kernel_pgt - __START_KERNEL_map + _KERNPG_TABLE
.quad level2_fixmap_pgt - __START_KERNEL_map + _PAGE_TABLE
NEXT_PAGE(level2_kernel_pgt)
/*
* 512 MB kernel mapping. We spend a full page on this pagetable
* anyway.
*
* The kernel code+data+bss must not be bigger than that.
*
* (NOTE: at +512MB starts the module area, see MODULES_VADDR.
* If you want to increase this then increase MODULES_VADDR
* too.)
*/
PMDS(0, __PAGE_KERNEL_LARGE_EXEC,
KERNEL_IMAGE_SIZE/PMD_SIZE)
NEXT_PAGE(level2_fixmap_pgt)
.fill 506,8,0
.quad level1_fixmap_pgt - __START_KERNEL_map + _PAGE_TABLE
/* 8MB reserved for vsyscalls + a 2MB hole = 4 + 1 entries */
.fill 5,8,0
NEXT_PAGE(level1_fixmap_pgt)
.fill 51
-
内核页表的顶级目录 init_top_pgt,定义在 __INITDATA 里面。可以看到,页表的根其实是全局变量,这就使得我们初始化的时候,甚至内存管理还没有初始化的时候,很容易就可以定位到。
-
接下来,将定义 init_top_pgt 包含哪些项,其中 quad 是声明一项内容,org 是跳到某个位置。
PGD_PAGE_OFFSET = pgd_index(__PAGE_OFFSET_BASE) PGD_START_KERNEL = pgd_index(__START_KERNEL_map) L3_START_KERNEL = pud_index(__START_KERNEL_map)init_top_pgt 有三项:
- 第一项指向的是 level3_ident_pgt,也即直接映射区页表的三级目录。这里减去 __START_KERNEL_map 是因为 __START_KERNEL_map 正好是虚拟地址空间的内核代码段的起始地址。减去这个值之后就得到了相应的物理地址了。
- 第一项定义完了以后,接下来我们跳到 PGD_PAGE_OFFSET 的位置,再定义一项。从定义可以看出,这一项就应该是 __PAGE_OFFSET_BASE 对应的。__PAGE_OFFSET_BASE 是虚拟地址空间里面内核的起始地址。第二项也指向 level3_ident_pgt,直接映射区。
- 第二项定义完了以后,接下来跳到 PGD_START_KERNEL 的位置,再定义一项。从定义可以看出,这一项应该是 __START_KERNEL_map 对应的项,__START_KERNEL_map 是虚拟地址空间里面内核代码段的起始地址。第三项指向 level3_kernel_pgt,内核代码区。
-
接下来的代码就很类似了,就是初始化各个表项,然后指向下一级目录,最终形成下面这张图。

至此,内核页表定义完了,一开始这里面的页表能够覆盖的内存范围比较小。例如,内核代码区 512M,直接映射区 1G。这个时候,其实只要能够映射基本的内核代码和数据结构就可以了。可以看出,里面还空着很多项,可以用于将来映射巨大的内核虚拟地址空间,等用到的时候再进行映射。
这个时候,内核也会像用户进程页表那样(用户态进程页表会有 mm_struct 指向进程顶级目录 pgd)定义了一个 mm_struct,指向 swapper_pg_dir。
struct mm_struct init_mm = {
.mm_rb = RB_ROOT,
.pgd = swapper_pg_dir,
.mm_users = ATOMIC_INIT(2),
.mm_count = ATOMIC_INIT(1),
.mmap_sem = __RWSEM_INITIALIZER(init_mm.mmap_sem),
.page_table_lock = __SPIN_LOCK_UNLOCKED(init_mm.page_table_lock),
.mmlist = LIST_HEAD_INIT(init_mm.mmlist),
.user_ns = &init_user_ns,
INIT_MM_CONTEXT(init_mm)
};
定义完内核页表,接下来是初始化内核页表,在系统启动的时候 start_kernel 会调用 setup_arch。
void __init setup_arch(char **cmdline_p)
{
/*
* copy kernel address range established so far and switch
* to the proper swapper page table
*/
clone_pgd_range(swapper_pg_dir + KERNEL_PGD_BOUNDARY,
initial_page_table + KERNEL_PGD_BOUNDARY,
KERNEL_PGD_PTRS);
load_cr3(swapper_pg_dir);
__flush_tlb_all();
......
init_mm.start_code = (unsigned long) _text;
init_mm.end_code = (unsigned long) _etext;
init_mm.end_data = (unsigned long) _edata;
init_mm.brk = _brk_end;
......
init_mem_mapping();
......
}
在 setup_arch 中,load_cr3(swapper_pg_dir) 说明内核页表要开始起作用了,并且刷新了 TLB,初始化 init_mm 的成员变量,最重要的就是 init_mem_mapping。最终它会调用 kernel_physical_mapping_init。
/*
* Create page table mapping for the physical memory for specific physical
* addresses. The virtual and physical addresses have to be aligned on PMD level
* down. It returns the last physical address mapped.
*/
unsigned long __meminit
kernel_physical_mapping_init(unsigned long paddr_start,
unsigned long paddr_end,
unsigned long page_size_mask)
{
unsigned long vaddr, vaddr_start, vaddr_end, vaddr_next, paddr_last;
paddr_last = paddr_end;
vaddr = (unsigned long)__va(paddr_start);
vaddr_end = (unsigned long)__va(paddr_end);
vaddr_start = vaddr;
for (; vaddr < vaddr_end; vaddr = vaddr_next) {
pgd_t *pgd = pgd_offset_k(vaddr);
p4d_t *p4d;
vaddr_next = (vaddr & PGDIR_MASK) + PGDIR_SIZE;
if (pgd_val(*pgd)) {
p4d = (p4d_t *)pgd_page_vaddr(*pgd);
paddr_last = phys_p4d_init(p4d, __pa(vaddr),
__pa(vaddr_end),
page_size_mask);
continue;
}
p4d = alloc_low_page();
paddr_last = phys_p4d_init(p4d, __pa(vaddr), __pa(vaddr_end),
page_size_mask);
p4d_populate(&init_mm, p4d_offset(pgd, vaddr), (pud_t *) p4d);
}
__flush_tlb_all();
return paddr_l
}
在 kernel_physical_mapping_init 里,我们先通过 __va 将物理地址转换为虚拟地址,然后再创建虚拟地址和物理地址的映射页表。既然这里可以使用 __va 和 __ pa 直接在虚拟地址和物理地址进行转换,但是别忘了,这都是在软件中进行转换。而在真实的内存访问中还是需要用到页表,所以还是需要建立页表。
上述介绍的页表是指后面我们系统起来之后真正的内核页表,而在定义和初始化这个页表之前会有一个早期的页表。
可以去看 arch\x86\kernel\head_64.S,这里面除了初始化内核页表之外,在这之前,还有另一个页表 early_top_pgt。这个页表就是专门用在真正的内核页表初始化之前。
所以这个时候上面为什么 level3_ident_pgt 是虚拟地址也能够解释地通了。
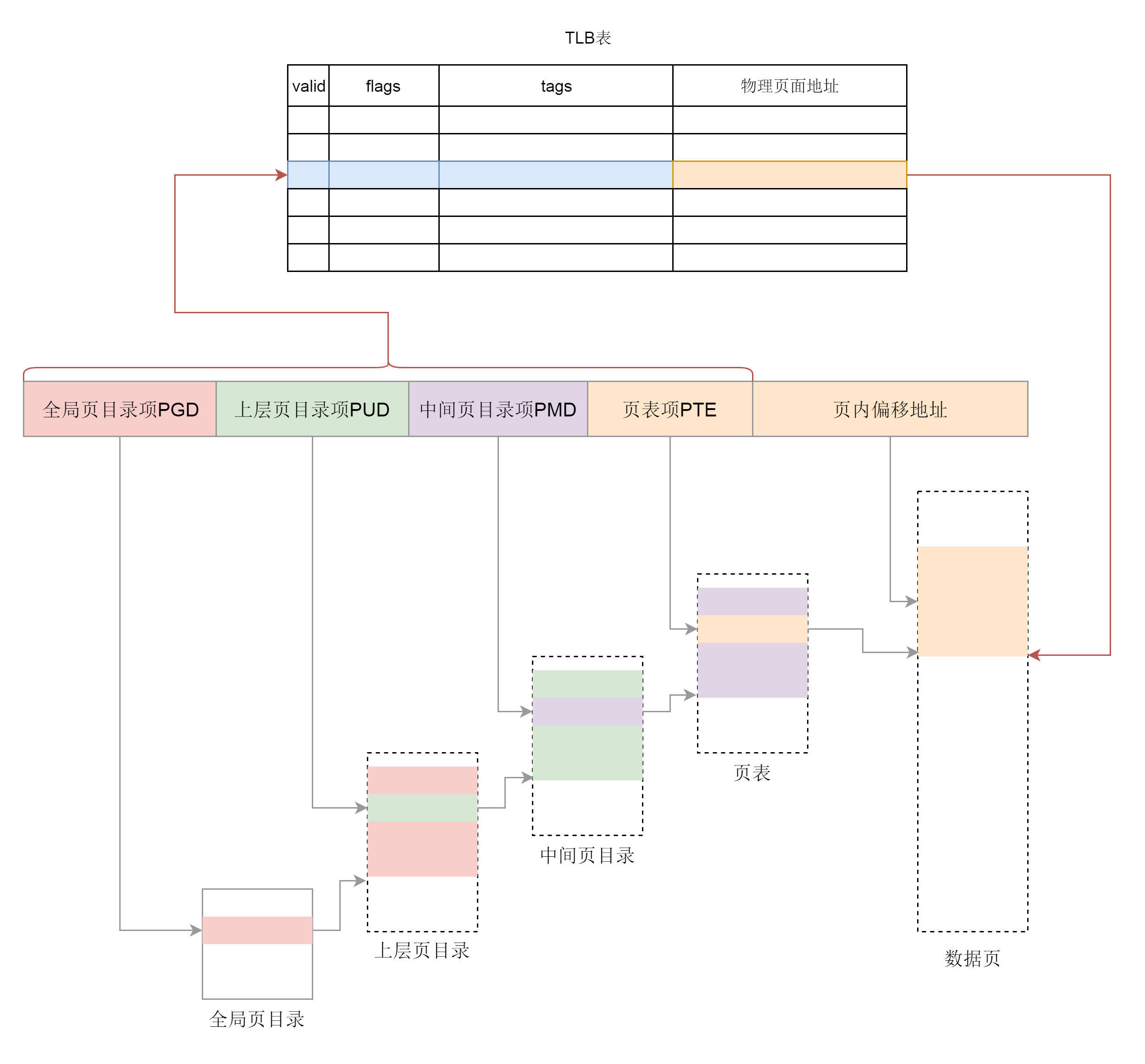
3. TLB
页表一般都很大,只能存放在内存中,假 每次从虚拟地址到物理地址的转换都走一遍页表的话,太耗时了。为了加快映射速度,引入了 TLB(Translation Lookaside Buffer),称之为快表,是专门用来做地址映射的硬件设备。它不在内存中,可存储的数据比较少,但是比内存要快。TLB 中存储了当前最可能被访问到的页表项,其内容是部分页表项的一个副本。
有了 TLB 之后,地址映射的过程就如图所示。我们先查块表,块表中有映射关系,然后直接转换为物理地址。如果在 TLB 查不到映射关系时,才会到内存中查询页表。换句话说,TLB 相当于页表的 Cache。