1. Memory Ggroup
Memory Cgroup 也是 Linux Cgroups 子系统之一,它的作用是对一组进程的 Memory 使用做限制。Memory Cgroup 的虚拟文件系统的挂载点一般在 "/sys/fs/cgroup/memory" 这个目录下。我们可以在 Memory Cgroup 的挂载点目录下,创建一个子目录作为控制组,并且控制组也同样是树状的层次结构。
跟 OOM 最相关的 3 个参数:
-
memory.limit_in_bytes 是一个控制组里所有进程可使用内存的最大值。需要注意的是:Memory Cgroup 限制的两类内存主要是 RSS 和 Page Cache,当然内核使用的内存比如 indode、dentry 等会被记入到 cgroup 中(但不包括页表,slab 等)。
free里的cache/buffer就是 page cache, 早期Linux文件相关的cache内存分buffer cache和page cache, 现在统一成page cache了。
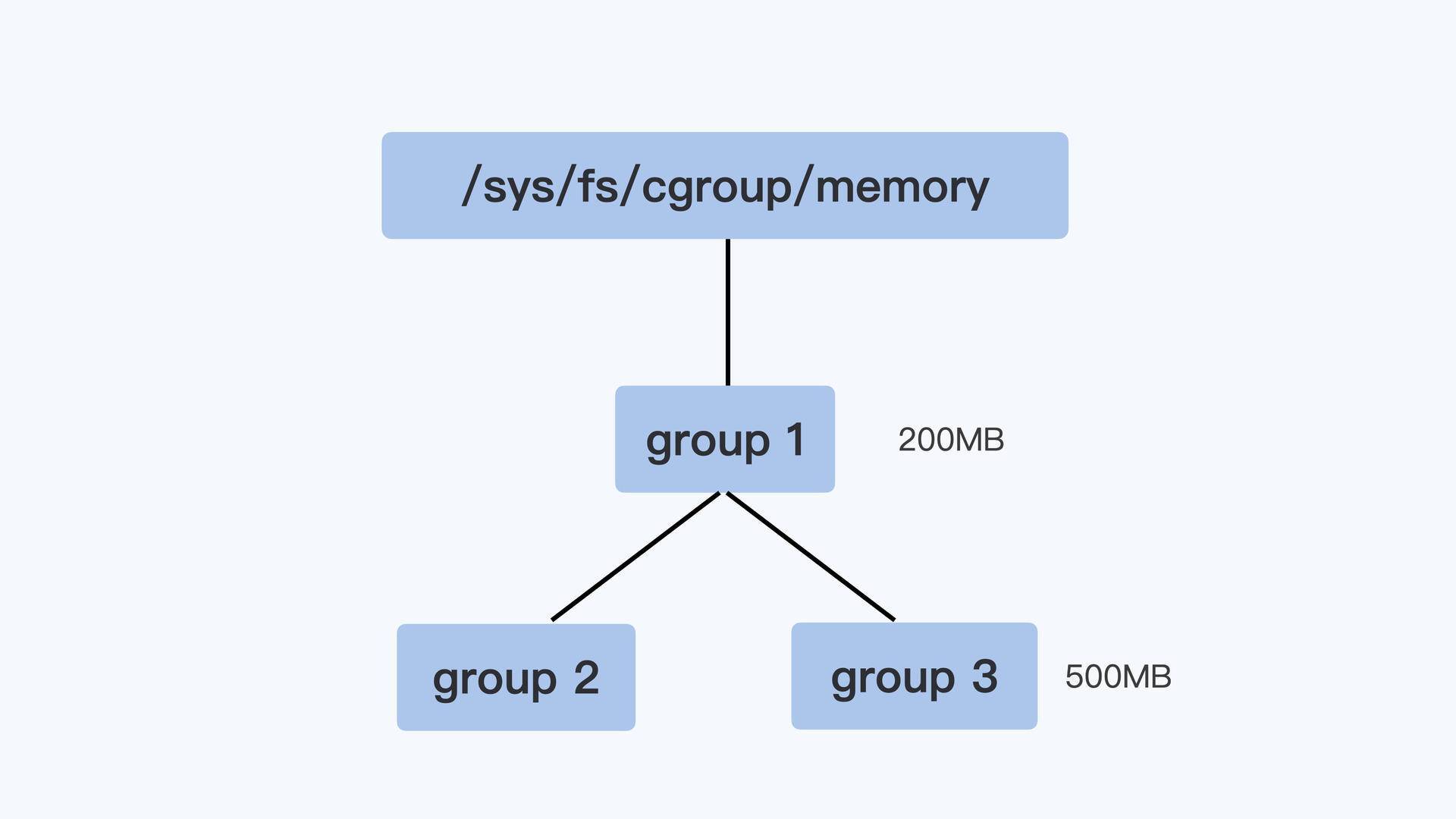
父节点的控制组里的 memory.limit_in_bytes 值可以限制它的子节点中所有进程的内存使用。比如像下面图里展示的那样,group1 里的 memory.limit_in_bytes 设置的值是 200MB,它的子控制组 group3 里 memory.limit_in_bytes 值是 500MB。那么,我们在 group3 里所有进程使用的内存总值就不能超过 200MB,而不是 500MB。同时 group2 + group3 + group1 的所有进程使用的内存总值不能超过 200MB。
-
memory.oom_control 当控制组中的进程内存使用达到上限值时,这个参数能够决定会不会触发 OOM Killer。如果没有人为设置的话,memory.oom_control 的缺省值就会触发 OOM Killer。这是一个控制组内的 OOM Killer,和整个系统的 OOM Killer 的功能差不多,差别只是被杀进程的选择范围:控制组内的 OOM Killer 当然只能杀死控制组内的进程,而不能选节点上的其他进程。
如果不希望触发 OOM Killer,只要执行 echo 1 > memory.oom_control 就行了,这时候即使控制组里所有进程使用的内存达到 memory.limit_in_bytes 设置的上限值,控制组也不会杀掉里面的进程。但是,这样操作之后,就会影响到控制组中正在申请物理内存页面的进程。这些进程的状态会变成因等待资源申请而变成 task interruptable。
-
memory.usage_in_bytes。这个参数是只读的,它里面的数值是当前控制组里所有进程实际使用的内存总和,主要是 RSS 内存和 Page Cache 内存的和。准确的内存使用量计算公式(memory.kmem.usage_in_bytes 表示该 memcg 内核内存使用量):
memory.usage_in_bytes = memory.stat[rss] + memory.stat[cache] + memory.kmem.usage_in_bytes需要注意的是如果 memory.usage_in_bytes 超过了 memory.limit_in_bytes , 那么应该是先发生 memory reclaim 去释放cache。假如 cache 没有了,还超过了,那才会 OOM kill 了。所以准确点来说,OOM 判断的依据是“新申请的内存+ memory.usage_in_bytes - reclaim memory”。发生 OOM 之后,控制组里的“某个进程”就会被杀死。那么这里杀死某个进程的选择标准是,控制组中总的可用页面乘以进程的 oom_score_adj,加上进程已经使用的物理内存页面,所得值最大的进程,就会被系统选中杀死。
另有一说,OOM 不是真正依据内存使用量 memory.usage_in_bytes,而是依据 working set(working_set应该是cAdvsior里的一个概念,可以看这个https://github.com/google/cadvisor/blob/master/container/libcontainer/handler.go),working set 计算公式:working_set = memory.usage_in_bytes - total_inactive_file。其中,active 和 inactive 的定义如下所示:
Active — The total amount of buffer or page cache memory, in kilobytes, that is in active use. This is memory that has been recently used and is usually not reclaimed for other purposes.
Inactive — The total amount of buffer or page cache memory, in kilobytes, that are free and and available. This is memory that has not been recently used and can be reclaimed for other purposes.
https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/6/html/deployment_guide/s2-proc-meminfo不过在memory reclaim的时候,可以reclaim的memory是大于 inactive_file memory的。所以,个人觉得还是以“新申请的内存+ memory.usage_in_bytes - reclaim memory”为准。
-
memory.stat 保存内存相关的统计数据,可以显示在当前控制组里各种内存类型的实际的开销。想要判断容器真实的内存使用量,我们不能用 Memory Cgroup 里的 memory.usage_in_bytes,而需要用 memory.stat 里的 rss 值。
-
memory.swappiness 可以控制这个 Memroy Cgroup 控制组下面匿名内存和 page cache 的回收,取值的范围和工作方式和全局的 swappiness 差不多。这里有一个优先顺序,在 Memory Cgorup 的控制组里,如果你设置了 memory.swappiness 参数,它就会覆盖全局的 swappiness,让全局的 swappiness 在这个控制组里不起作用。不同于 /proc 文件系统下全局的 swappiness,当 memory.swappiness = 0 的时候,对匿名页的回收是始终禁止的,也就是始终都不会使用 Swap 空间。因此,我们可以通过 memory.swappiness 参数让需要使用 Swap 空间的容器和不需要 Swap 的容器,同时运行在同一个宿主机上。
容器可以通过设置 memory.swappiness 参数来决定是否使用 swap 空间。
其他参数可以参考内核的文档说明:https://www.kernel.org/doc/Documentation/cgroup-v1/memory.txt
如果被删的 memory cgroup 还有 cache memory, 对应的 memroy cgroup 控制块不会随 /sys/fs/cgroup/memory/.../<memory_cgroup> 的删除而马上删掉。
你可以用 “echo 3 > /proc/sys/vm/drop_caches” 释放cache之后, memory cgroup num_cgroups的数值应该会下降一些。
1.1. 内核实现
1.1.1. 限制的大概思路
在 Linux 中,对于每个控制组,内存控制器中都有一个结构体 mem_cgroup 与其对应。在每个 mem_cgroup 中又有一个名为 memory 的 page_counter 结构体,它跟踪了每个 mem_cgroup 的内存使用情况,也就是每个控制组的内存使用情况。每当我们要为这个mem_cgroup 分配新的内存时,便会调用 page_counter_try_charge 函数来尝试对这些新的内存进行 charge 操作,即将这些页加入到该 page_counter 里。如果加上这些页之后,这个 page_counter 的值大于了我们给它设定的最大值,则会导致这次 charge 失败,随后根据其他设置可能会进一步触发内存不足的操作 oom(Out of Memory)。如果没有超过最大值的限制,则此次 charge 成功,新的页成功被加入 mem_cgroup 的计数器中。
bool page_counter_try_charge(struct page_counter *counter, unsigned long nr_pages, struct page_counter **fail)
{
...
for (c = counter; c; c = c->parent) {
long new;
new = atomic_long_add_return(nr_pages, &c->usage);
if (new > c->max) {
atomic_long_sub(nr_pages, &c->usage);
...
goto failed;
}
}
...
failed:
for (c = counter; c != *fail; c = c->parent)
page_counter_cancel(c, nr_pages);
return false;
}
反之,每当内存要被释放时,需要使用相反的流程来进行uncharge操作。通过这些操作,我们成功地记录了每个控制组所使用的内存大小,也成功地限制了每个控制组所能使用的最大内存。
1.1.2. 如何修改一个控制组所能使用的最大内存
“/mm/memcontrol.c’’ 中有这样一段代码。
static struct cftype mem_cgroup_legacy_files[] = {
{
.name = "usage_in_bytes",
.private = MEMFILE_PRIVATE(_MEM, RES_USAGE),
.read_u64 = mem_cgroup_read_u64,
},
{
.name = "max_usage_in_bytes",
.private = MEMFILE_PRIVATE(_MEM, RES_MAX_USAGE),
.write = mem_cgroup_reset,
.read_u64 = mem_cgroup_read_u64,
},
{
.name = "limit_in_bytes",
.private = MEMFILE_PRIVATE(_MEM, RES_LIMIT),
.write = mem_cgroup_write,
.read_u64 = mem_cgroup_read_u64,
},
{
.name = "soft_limit_in_bytes",
.private = MEMFILE_PRIVATE(_MEM, RES_SOFT_LIMIT),
.write = mem_cgroup_write,
.read_u64 = mem_cgroup_read_u64,
},
}
当我们向内存控制器文件接口 memory.limit_in_bytes 中写入一个值时,cgroups 会调用mem_cgroup_write 函数。在这个函数中,最终会修改该控制组对应的 mem_cgroup 中名为 memory 的 page_counter 的最大值。
static ssize_t mem_cgroup_write(struct kernfs_open_file *of, char *buf, size_t nbytes, loff_t off) {
struct mem_cgroup *memcg = mem_cgroup_from_css(of_css(of));
...
ret = mem_cgroup_resize_max(memcg, nr_pages, false);
...
}
static int mem_cgroup_resize_max(struct mem_cgroup *memcg, unsigned long max, bool memsw) {
...
struct page_counter *counter = memsw ? &memcg->memsw : &memcg->memory;
ret = page_counter_set_max(counter, max);
...
}
int page_counter_set_max(struct page_counter *counter, unsigned long nr_pages) {
...
old = xchg(&counter->max, nr_pages);
...
}
1.2. kubernetes 中的使用
Kubernetes 都会为容器设置一个内存使用的上限。这个内存的上限值会被写入 Cgroup 里,具体来说就是容器对应的 Memory Cgroup 控制组里 memory.limit_in_bytes 这个参数中。
而对于 k8s request 来说,它不会修改 Memory Cgroup 里的参数。只是在 kube scheduler 里调度的时候看做个计算,看节点上是否还有内存给这个新的 Pod。
2. Memory Cgroup 相关问题
2.1. 怎么才能快速确定容器发生了 OOM 并处理呢?
我们通过查看内核的日志,使用 journalctl -k 命令,或者直接查看日志文件 /var/log/message。容器发生 OOM Kill 的时候,内核会输出下面的这段信息,大致包含下面这三部分的信息:
-
第一个部分就是容器里每一个进程使用的内存页面数量。
在"rss"列里,"rss'是 Resident Set Size 的缩写,指的就是进程真正在使用的物理内存页面数量。可以看到 init 进程的"rss"是 1 个页面,mem_alloc 进程的"rss"是 130801 个页面,内存页面的大小一般是 4KB,我们可以做个估算,130801 * 4KB 大致等于 512MB。

-
第二部分是 "oom-kill" 这行,这一行里列出了发生 OOM 的 Memroy Cgroup 的控制组,我们可以从控制组的信息中知道 OOM 是在哪个容器发生的。
-
第三部分显示了最终被 OOM Killer 杀死的进程。如图中"Killed process 7445 (mem_alloc)" 这行。
通过了解内核日志里的这些信息,可以很快地判断出容器是因为 OOM 而退出的,并且还可以知道是哪个进程消耗了最多的 Memory。那么知道了哪个进程消耗了最大内存之后,针对这个进程一般有两种处理方式:
- 第一种情况是这个进程本身的确需要很大的内存,这说明我们给 memory.limit_in_bytes 里的内存上限值设置小了,那么就需要增大内存的上限值。
- 第二种情况是进程的代码中有 Bug,会导致内存泄漏,进程内存使用到达了 Memory Cgroup 中的上限。如果是这种情况,就需要我们具体去解决代码里的问题了。
2.2. 为什么容器内存使用量总是在临界点附近?
在一些容器的使用场景中,比如容器里的应用有很多文件读写,你会发现整个容器的内存使用量已经很接近 Memory Cgroup 的上限值了,但是在容器中我们接着再申请内存,还是可以申请出来,并且没有发生 OOM。
这个是因为 Linux 的内存回收(page frame reclaim)会被调用起来。那么在这个控制组里的 page cache 的内存会根据新申请的内存大小释放一部分,这样我们还是能成功申请到新的物理内存,整个控制组里总的物理内存开销 memory.usage_in_bytes 还是不会超过上限值 memory.limit_in_bytes。当然前提条件是申请的内存大小小于 page cache 的大小。
2.3. 容器如何对 swap 空间进行使用
Memory Cgroup 控制组下面的参数,你会看到有一个 memory.swappiness 参数。memory.swappiness 可以控制这个 Memroy Cgroup 控制组下面匿名内存和 page cache 的回收,取值的范围和工作方式和全局的 swappiness 差不多。这里有一个优先顺序,在 Memory Cgorup 的控制组里,如果你设置了 memory.swappiness 参数,它就会覆盖全局的 swappiness,让全局的 swappiness 在这个控制组里不起作用。
不过,这里有一点不同,当 memory.swappiness = 0 的时候,对匿名页的回收是始终禁止的,也就是始终都不会使用 Swap 空间。这时 Linux 系统不会再去比较 free 内存和 zone 里的 high water mark 的值,再决定一个 Memory Cgroup 中的匿名内存要不要回收了。
那么,在设置了 memory.swappiness = 0 情况下,如果容器申请的内存超过了 memory.limit_in_bytes 之后,是会发生 OOM kill。而当没有设置 memory.swappiness = 0 情况下,如果容器申请的内存超过了 memory.limit_in_bytes 之后,不一定会发生 OOM kill,因为申请的内存中可能会被交换到 swap 空间了(也就是说这部分被换到 swap 空间中的内存是不会被 memory cgroup 所控制的)。
综上来说,使用 memory.swappiness 可以让需要使用 swap 空间的容器和不需要 swap 空间的容器,同时运行在一个宿主机上。比如,在同一个宿主机上,同时存在容器 A 和其他容器,容器 A 上运行着需要使用 Swap 空间的应用,而别的容器不需要使用 Swap 空间。那么,我们还是可以在宿主机节点上打开 Swap 空间,同时在其他容器对应的 Memory Cgroups 控制组里,把 memory.swappiness 这个参数设置为 0(A 容器的 swapiness 参数不为 0)。这样一来,我们不但满足了容器 A 的需求,而且别的容器也不会受到影响,仍然可以严格按照 Memory Cgroups 里的 memory.limit_in_bytes 来限制内存的使用。
巨人的肩膀
- 极客时间.《容器实战》

