Cgroups 是 Control Groups(控制组)的缩写,是 Linux 内核(从 Linux 2.6.24 开始)提供的一种可以用来将任务分组,并对一个进程组所能使用的多种物理资源(包括 CPU、内存、磁盘、网络带宽)进行限制、监控和隔离的功能。此外,Cgroups 还能够对进程进行优先级设置、审计,以及将进程挂起和恢复等操作。
那么为什么除了 Namespace 之外还需要 Cgroups 呢?因为虽然容器里的 1 号进程只能看到容器里的情况,但是在宿主机上,它作为 100 号进程(比如宿主机上它的 PID 是 100)与其他所有进程之间依然是平等的竞争关系。也就是说,虽然 100 号进程表面上被隔离了起来,但是它能够使用的资源(比如 CPU、内存)是全部的,它可能把所有资源耗光。那么这样显然不是一个容器应该表现出来的合理行为。
Cgroups 中的分组功能是在内核中的核心 cgroup 代码中实现的,而资源跟踪和限制则是在每一种资源(例如 CPU、内存)的子系统中分别实现的。
之外,Cgroups 通过一个叫做 cgroupfs 的伪文件系统提供了用户接口,即用户操作 Cgroups 可以通过文件系统。cgroupfs 一般被挂载在 /sys/fs/cgroup 路径下。我们可以通过 mount 命令来查看一下,可以发现输出结果是一系列文件系统目录。
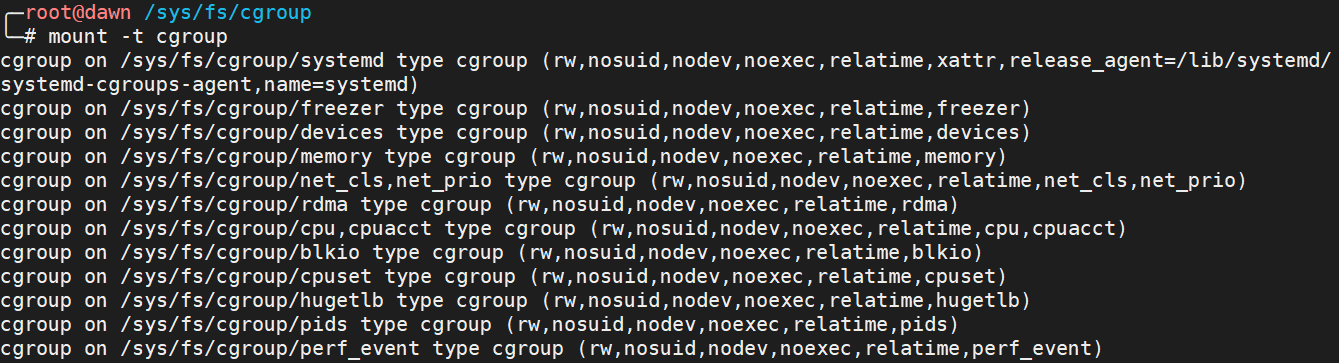
我们查看 /sys/fs/cgroup 的时候还可以看到一系列子目录,这些子目录又被称为子系统。这些都是我这台机器上当前可以被 Cgroups 进行限制的资源种类。 比如:
- cpu 只要限制 CPU 的使用时间
- cpuset 为进程分配单独的 CPU 核和对应的内存节点
- memory 为进程设定内存使用的限制
- blkio 块设备设定 IO 限制,一般用于磁盘等设备

而在子目录下面可以看到该子系统对应的资源可以被限制的方法,比如对于 CPU 子系统来说,我们可以看到如下几个配置文件。

其中 cpu.cfs_period_us 和 cpu.cfs_quota_us 这两个文件组合使用可以限制进程在长度为 cfs_period 的一段时间内,只能被分配到总量为 cfs_quota 的 CPU 时间。
完整的 Cgroups 子系统的介绍(官方):https://man7.org/linux/man-pages/man7/cgroups.7.html
1. 常用术语和基础知识
下面介绍 cgroups 中的一些常用术语和基本的知识。
-
任务(Task) 是 cgroups 中用于管理的基本单位。在 cgroups v1 中,一个任务就是系统中的一个线程。
-
**控制组(Cgroup)**是一些按照某种标准划分的任务的集合。一个任务可以加入到一个控制组,也可以在不同的控制组之间进行迁移。Cgroups 中的资源限制都是以控制组为单位实现的。一个控制组内的所有任务可以使用 cgroups 为该控制组分配的资源,同时受到 cgroups 为该控制组所设定的限制。
创建一个新的控制组,只需要在相应子系统下面新建一个目录即可,许多配置文件会自动填入目录中。用户对这些配置文件的修改会调用文件系统的相关函数(如 cpu_cfs_quota_write_s64 函数)。
-
子系统(Subsystem) 是一个内核组件,每个子系统会对应一种类型的系统资源。内核中有许多已经实现的子系统,例如 CPU 和内存子系统等。通过这些子系统,用户可以监控和限制一个控制组使用的对应类型物理资源。例如,用户可以限制一个控制组所能使用的 CPU 时间或内存大小、获取该控制组已使用的 CPU 时间和内存等。由于子系统可以控制物理资源分配,它有时候也会被称作资源控制器(Resource Controllers)。
Cgroups 定义了下面的一系列子系统,
- CPU 子系统,主要限制进程的 CPU 使用率。
- cpuacct 子系统,可以统计 cgroup 中的进程的 CPU 使用报告。
- cpuset 子系统,可以为 cgroup 中的进程分配单独的 CPU 节点或者内存节点。
- memory 子系统,可以限制进程的 Memory 使用量。
- blkio 子系统,可以限制进程的块设备 IO。
- devices 子系统,可以控制进程能够访问某些设备。
- net_cls 子系统,可以标记 cgroup 中进程的网络数据包,然后可以使用 tc 模块(traffic control)对数据包进行控制。
- freezer 子系统,可以挂起或者恢复 cgroup 中的进程。
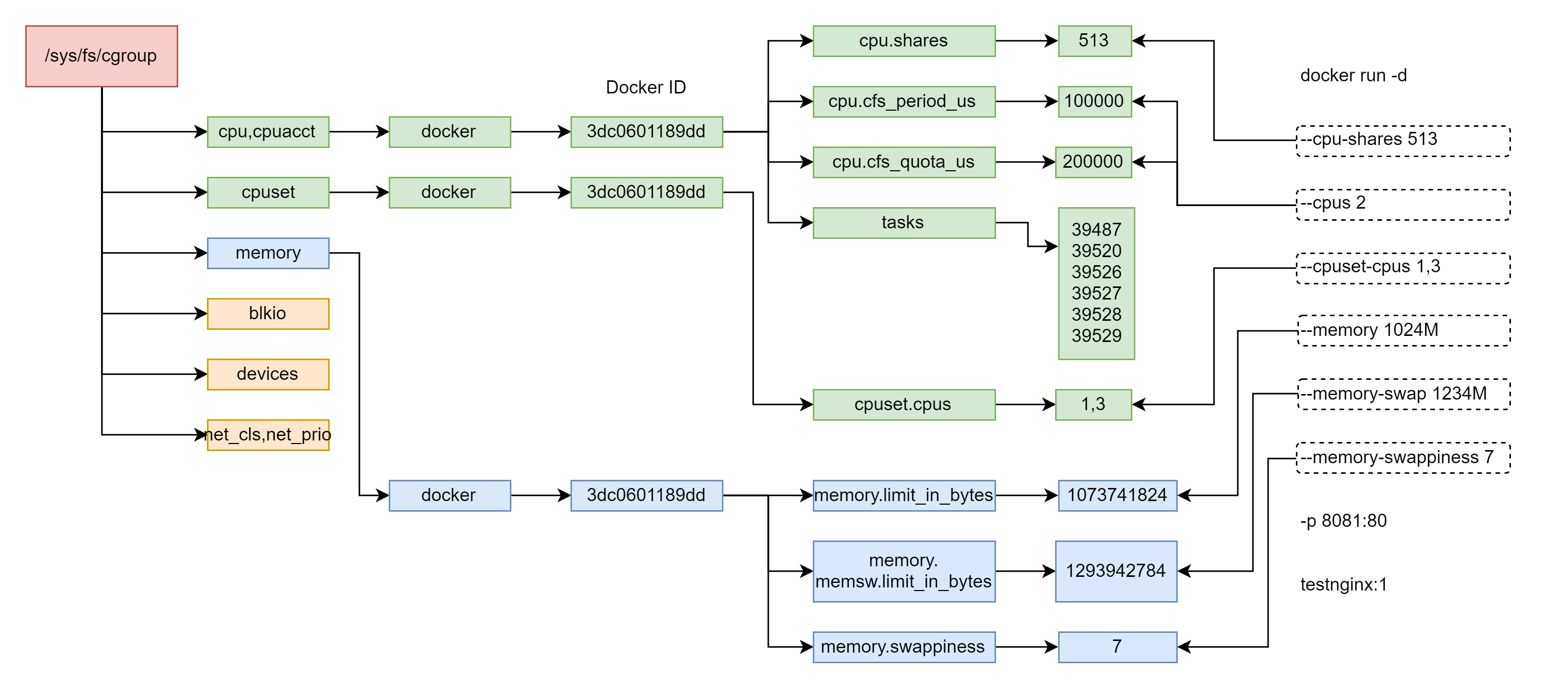
cgroup 文件系统大多数被挂载到 /sys/fs/cgroup 下,如下所示。比如,Memory Cgroup 的虚拟文件系统的挂载点一般在 "/sys/fs/cgroup/memory" 这个目录下。
$ ll /sys/fs/cgroup/ total 0 dr-xr-xr-x 7 root root 0 Jan 11 10:56 blkio lrwxrwxrwx 1 root root 11 Dec 5 08:58 cpu -> cpu,cpuacct lrwxrwxrwx 1 root root 11 Dec 5 08:58 cpuacct -> cpu,cpuacct dr-xr-xr-x 7 root root 0 Jan 11 10:56 cpu,cpuacct dr-xr-xr-x 4 root root 0 Jan 12 11:31 cpuset dr-xr-xr-x 7 root root 0 Jan 11 10:56 devices dr-xr-xr-x 4 root root 0 Jan 12 11:31 freezer dr-xr-xr-x 4 root root 0 Jan 12 11:31 hugetlb dr-xr-xr-x 7 root root 0 Jan 11 10:56 memory lrwxrwxrwx 1 root root 16 Dec 5 08:58 net_cls -> net_cls,net_prio dr-xr-xr-x 4 root root 0 Jan 12 11:31 net_cls,net_prio lrwxrwxrwx 1 root root 16 Dec 5 08:58 net_prio -> net_cls,net_prio dr-xr-xr-x 4 root root 0 Jan 12 11:31 perf_event dr-xr-xr-x 7 root root 0 Jan 11 10:56 pids dr-xr-xr-x 2 root root 0 Jan 11 10:56 rdma dr-xr-xr-x 7 root root 0 Jan 11 10:56 systemd下面是 cgroups 对于 Docker 资源的控制示意图:
-
层级(Hierarchy) 内核将控制组组织成树状结构,每一棵由控制组构成的树称为一个层级结构,它们拥有各自的 cgroups 文件系统。用户可以通过在一个 cgroups 文件系统中创建、删除和重命名子目录来构造或修改这一层级结构。在一个层级结构中,每个子目录都是一个控制组,子目录下有着许多文件,其中有一些文件是所有子系统都拥有的,例如 cgroup.procs 等,向该文件中写入一个进程的 PID 可以将这个进程加入该控制组;还有一些文件则是各个子系统所独有的,例如 cpu 子系统有着一些以 cpu 开头的文件,通过读写这些文件,我们便能与 cgroups 进行交互。
任务在每个层级结构中可以属于一个控制组,同时我们可以为每个层级结构附加一些子系统,但在同一时刻,每个子系统只能被附加到一个层级结构中。这是因为同一任务在不同的层级结构中可能会属于不同的控制组,若一个任务属于的两个控制组对于同一种系统资源的限制不一致,则会产生矛盾。
如图所示,我们将 cpu 和 cpuacct 两个子系统附加到了层级结构 A 中,将 memory 子系统附加到了层级结构 B 中。其实,就相当于层级结构 A 被挂载到了 /cpu,cpuacct 目录下,而层级结构 B 被挂载到了 /memory 目录下。
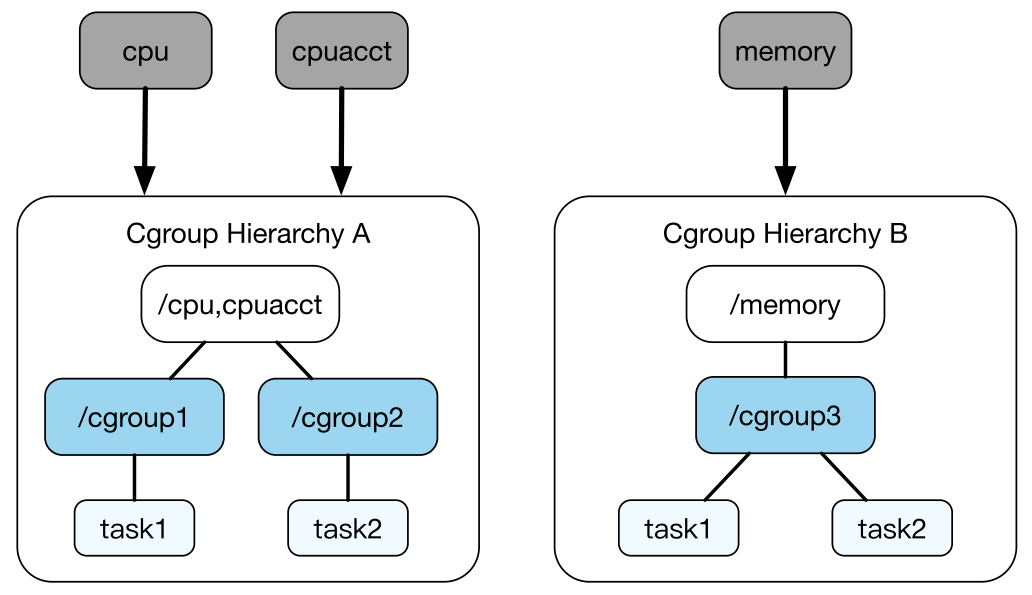
理解思路:Cgroups 是指一种机制,里面包含了分组和资源限制、监控和隔离两个功能,而分组功能对应的是控制组,资源限制、监控和隔离对应的是子系统。
2. Cgroups V2
Cgroups 有 v1 和 v2 两个版本:Cgroups v1 在 Linux 中很早就实现了,各种子系统比较独立,每个进程在各个 Cgroups 子系统中独立配置,可以属于不同的 group。虽然这样比较灵活,但是也存在问题,会导致对同一进程的资源协调比较困难(比如 memory Cgroup 与 blkio Cgroup 之间就不能协作)。虽然 v1 有缺陷,但是在主流的生产环境中,大部分使用的还是 v1。Cgroups v2 做了设计改进,解决了 v1 的问题,使各个子系统可以协调统一地管理资源。不过 Cgroups v2 在生产环境的应用还很少,因为该版本很多子系统的实现需要较新版本的 Linux 内核,还有无论是主流的 Linux 发行版本还是容器云平台,比如 Kubernetes,对 v2 的支持也刚刚起步。从 Linux4.5 内核开始,cgroupsV2 已经被标记为官方发布。相对于 cgroupsV1,cgroupsV2 有如下变化:
- 整个系统只有一个层级,也就是整个 cgroups 系统只有一棵树(而不是之前的多棵树)。
- 层级下的控制组可以选择拥有哪些子系统,即一个控制组可以拥有多个子系统。
- 只通过将任务绑定到 1 个控制组,就可以控制多种系统资源的使用。
要想使用 Cgroup V2,需要在 Linux 系统里打开 Cgroup V2 的功能。因为目前即使最新版本的 Ubuntu Linux 或者 Centos Linux,仍然在使用 Cgroup v1 作为缺省的 Cgroup。
3. Cgroups 实现
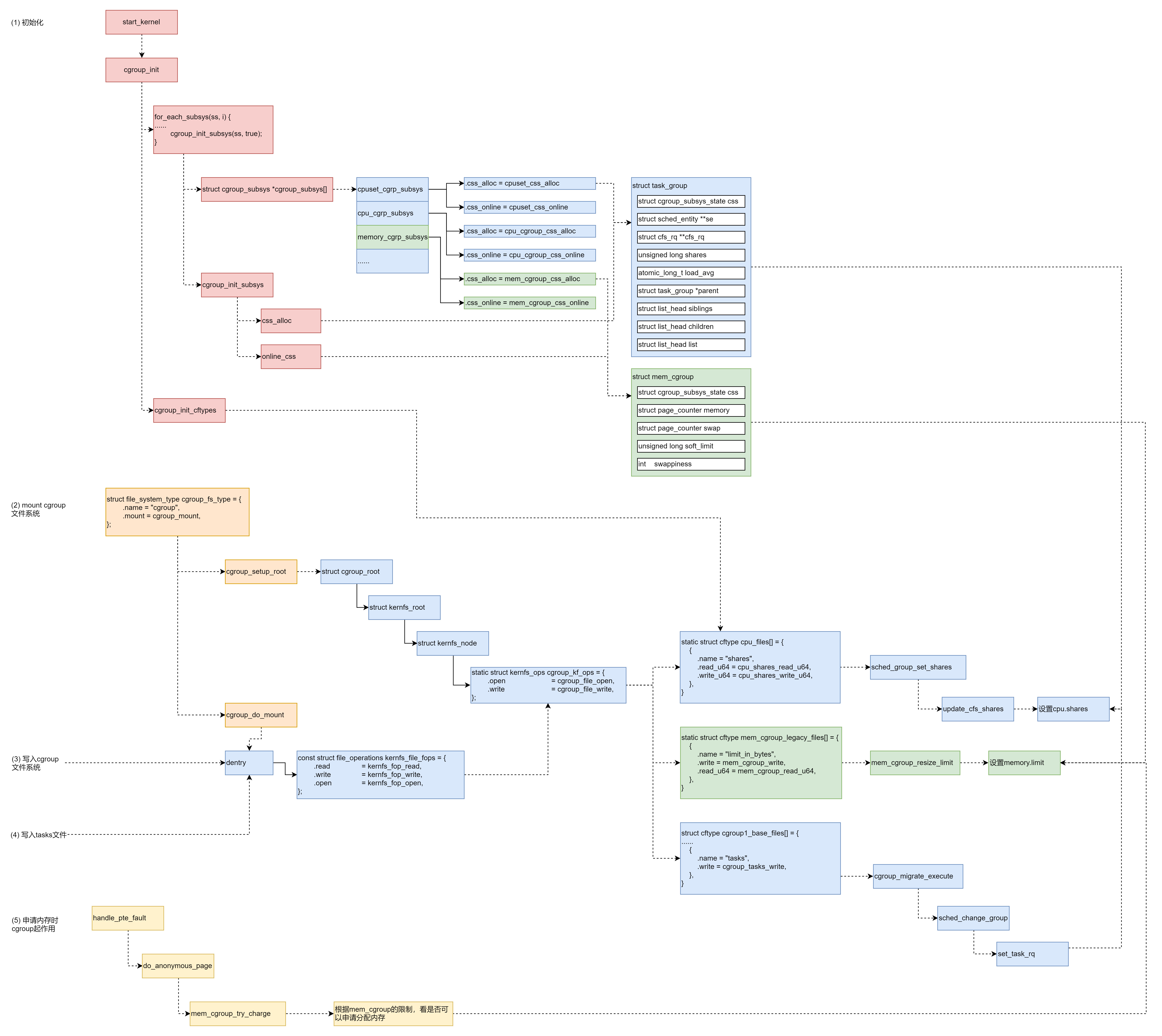
整体实现过程是:
- 系统初始化的时候,初始化 Croups 各个子系统的操作函数,分配各个子系统的数据结构。
- mount cgroups 文件系统,创建文件系统的树形结构,以及操作函数。
- 写入子系统文件,设置 cpu 或者 memory 的相关参数,这个时候文件系统的操作函数会调用到 cgroups 子系统的操作函数,从而将参数设置到 cgroups 子系统的数据结构中。
- 写入 tasks 文件,将进程交给某个 cgroup 进行管理,因为 tasks 文件也是一个 cgroups 文件,所以也会调用相应的文件系统的操作函数将进程和 cgroup 关联起来,同时将进程和某个子系统关联起来,比如这个进程和某个 cgroup 关联起来之后并且和 CPU 子系统建立了联系,那么下次调用到这个进程的时候,会以 cgroup 方式的调度(调度是 CPU 子系统的);比如内存分配,那么也是类似的,CPU 子系统的 cgroup 是 task_group,mem 子系统的 cgroup 则是 mem_group。
- 对于 CPU 来讲,会修改 scheduled entity,放入相应的队列里面去,从而下次调度的时候就起作用了。对于内存的 cgroup 设定,在申请内存的时候就起作用。
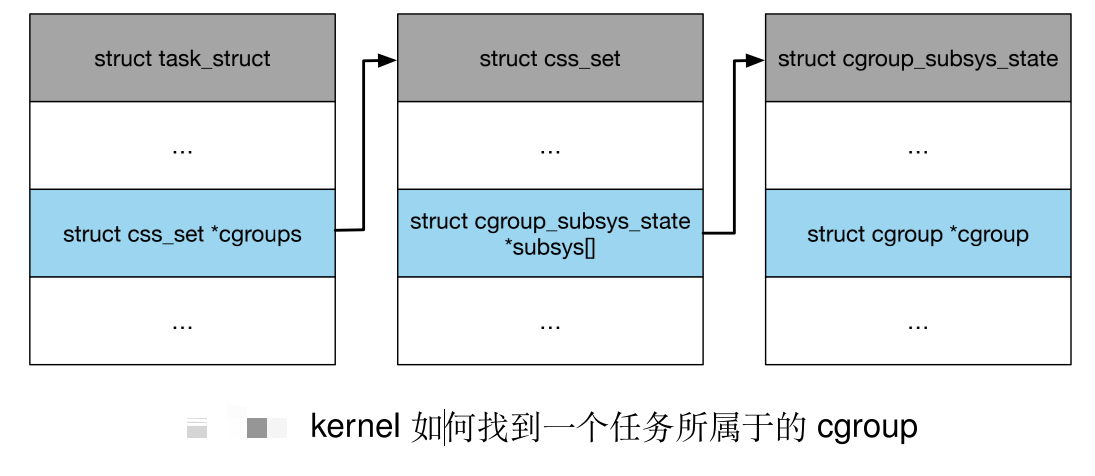
4. Cgoups 配置示例
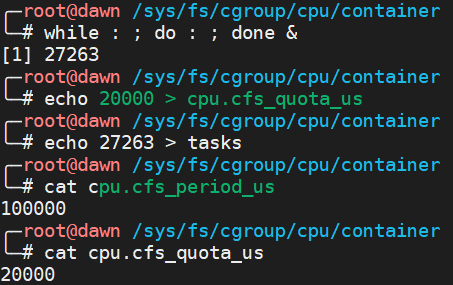
下面基于 Cgroups 提供的操作接口进行配置,我们先在相应的子系统中再创建一个目录,比如 container ,这个目录就被称为“控制组”。当将这个目录创建好了之后,你会发现这个目录已经生成了该子系统对应的资源限制文件。

接下去,我们通过修改 container 中的文件内容来设置限制。比如向 container 中的 cpu.cfs_quota_us 中写入 20 ms,也就是 20000,就表示每 cpu_period_us (100ms)被控制组限制的进程只能使用 20ms 的 CPU 时间。
接下去我们把要限制的进程 PID 写入 container 目录中的 tasks 文件中,那么该设置对要限制的进程就有效了。

5. Docker 实现
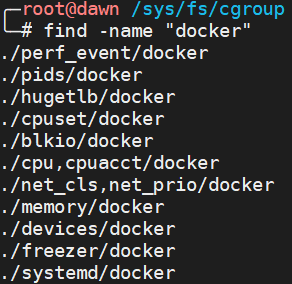
对于 Docker 等 Linux 容器项目来说,它们只需要在每个子系统下面,为每个容器创建一个控制组(也就是创建一个新目录),然后在启动容器进程之后,把这个进程的 PID 写入到这个控制组的 tasks 文件中即可。而控制组中的资源限制要填上什么值,就要看用户执行 docker run 时指定的参数内容。在 Docker 主机中,每个子系统下面都有 docker 控制组。
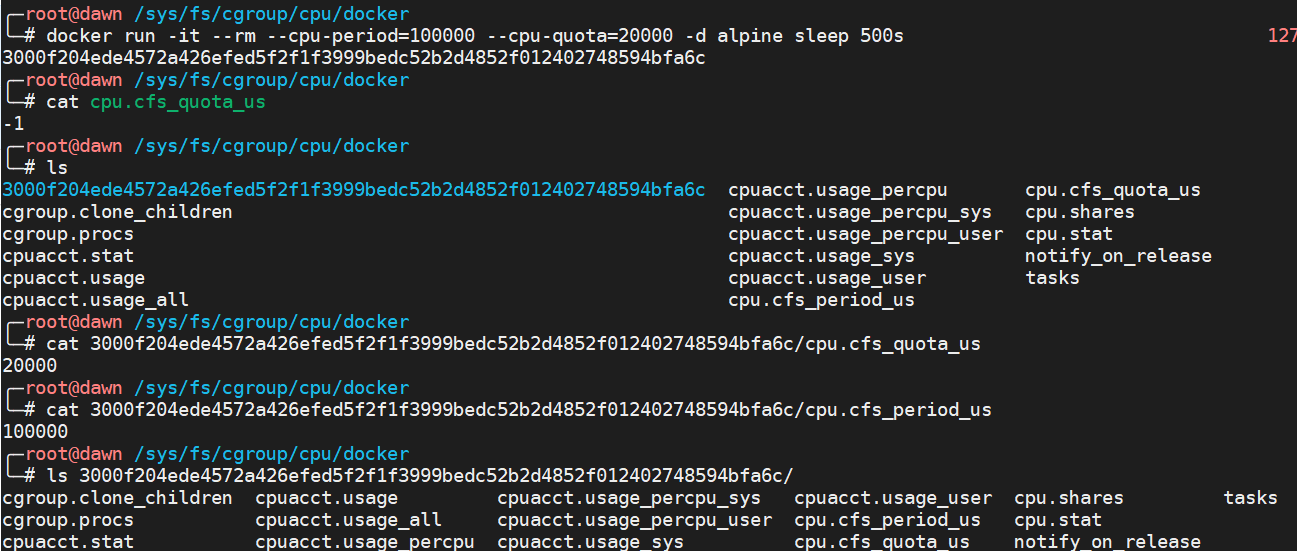
下面我们来演示 docker 进行设置的效果,就会在 CPU 子系统的 docker 控制组中进行相关的设置。
docker run -it --rm --cpu-period=100000 --cpu-quota=20000 -d alpine sleep 500s
如下所示,docker 还会在 docker 控制组创建一个新的目录,在这个目录中对资源进行设置,从而达到限制资源使用的效果。
6. 总结
跟 Namespace 情况类似,Cgoups 对资源的限制能力也有很多不完善的地方,其中被提及最多的是 /proc 文件系统的问题。/proc 目录存储着当前内核运行状态的一系列特殊文件,用户可以通过访问这些文件,查看系统以及当前正在运行的进程的信息,比如 CPU 使用情况、内存占用率等,这些文件也是 top 指令查看系统信息的主要数据来源。
但是,如果你在容器里执行 top 指令,就会发现,它显示的信息居然还是宿主机的 CPU 和内存数据。这是因为 /proc 文件系统并不知道用户通过 Cgroups 给这个容器做了什么样的资源限制,所以它返回的还是整个宿主机的。那么这个问题会导致,容器内的应用程序读取到的 CPU 核数、可用内存等信息还是宿主机的,而不是做了限制之后的。这就是容器相比较于虚拟机另一个不尽如人意的地方。
当然,为了解决上面的那个问题。直观的做法就是容器不挂载宿主机的该目录就可以了,那么实际上可以通过 lxcfs 来实现隔离,lxcfs 在宿主机上维护进程组的信息,然后容器启动的时候将 lxcfs 维护的进程组信息所在的目录挂载到容器的 /proc 目录,当容器中获取 /proc 信息时,实际上获取宿主机上对该容器的进程组信息。
20201008理解:/proc 存的是当前宿主机内核运行状态的情况,比如 CPU 使用情况、内存占用率等。容器在它看来其实就是一个做了限制的进程而已,它做计算还是针对整个内核的情况。但是,容器内的实际使用情况应该是根据容器中的相关限制来得出的,比如已经对容器做了 CPU 使用的限制,那么 top 命令得到的应该是在这个限制下,容器内进程的实际使用情况。
巨人的肩膀
- 极客时间.《深入剖析 Kubernetes》.张磊老师."白话容器基础(二):隔离与限制"
- 极客时间.《趣谈Linux操作系统》
- 极客时间.《容器实战》

