1. 容器网络
容器有自己的 Network Namespace,eth0 是这个 Network Namespace 里的网络接口。而宿主机上也有自己的 eth0,宿主机上的 eth0 对应着真正的物理网卡,可以和外面通讯。

要让容器 Network Namespace 中的数据包最终发送到物理网卡上,最终大致需要经过以下两个步骤:
- 第一步,就是要让数据包从容器的 Network Namespace 发送到 Host Network Namespace 上。
- 第二步,数据包发到了 Host Network Namespace 之后,还要解决数据包怎么从宿主机上的 eth0 发送出去的问题。
针对这两个步骤的实现,可以查看 Docker 网络的文档(https://docs.docker.com/network/)或者 kubernetes 网络的文档(https://kubernetes.io/docs/concepts/cluster-administration/networking/),这些文档里面介绍了多种容器网络配置的方式。
不过对于容器从自己的 Network Namespace 连接到 Host Network Namespace 的方法,一般来说就只有两类设备接口:
- 一类是veth(https://man7.org/linux/man-pages/man4/veth.4.html);
- 另外一类是 macvlan/ipvlan。
veth 的方式
下面将重点讲解使用 veth+bridge+nat 方式的容器数据发送过程,也就是绝大部分容器用的缺省的网络配置方式。从 veth 的这种网络接口配置上看,一个数据包要从容器里发送到宿主机外,需要先从容器里的 eth0 (veth_container) 把包发送到宿主机上 veth_host,然后再在宿主机上通过 nat 或者路由的方式,经过宿主机上的 eth0 向外发送。
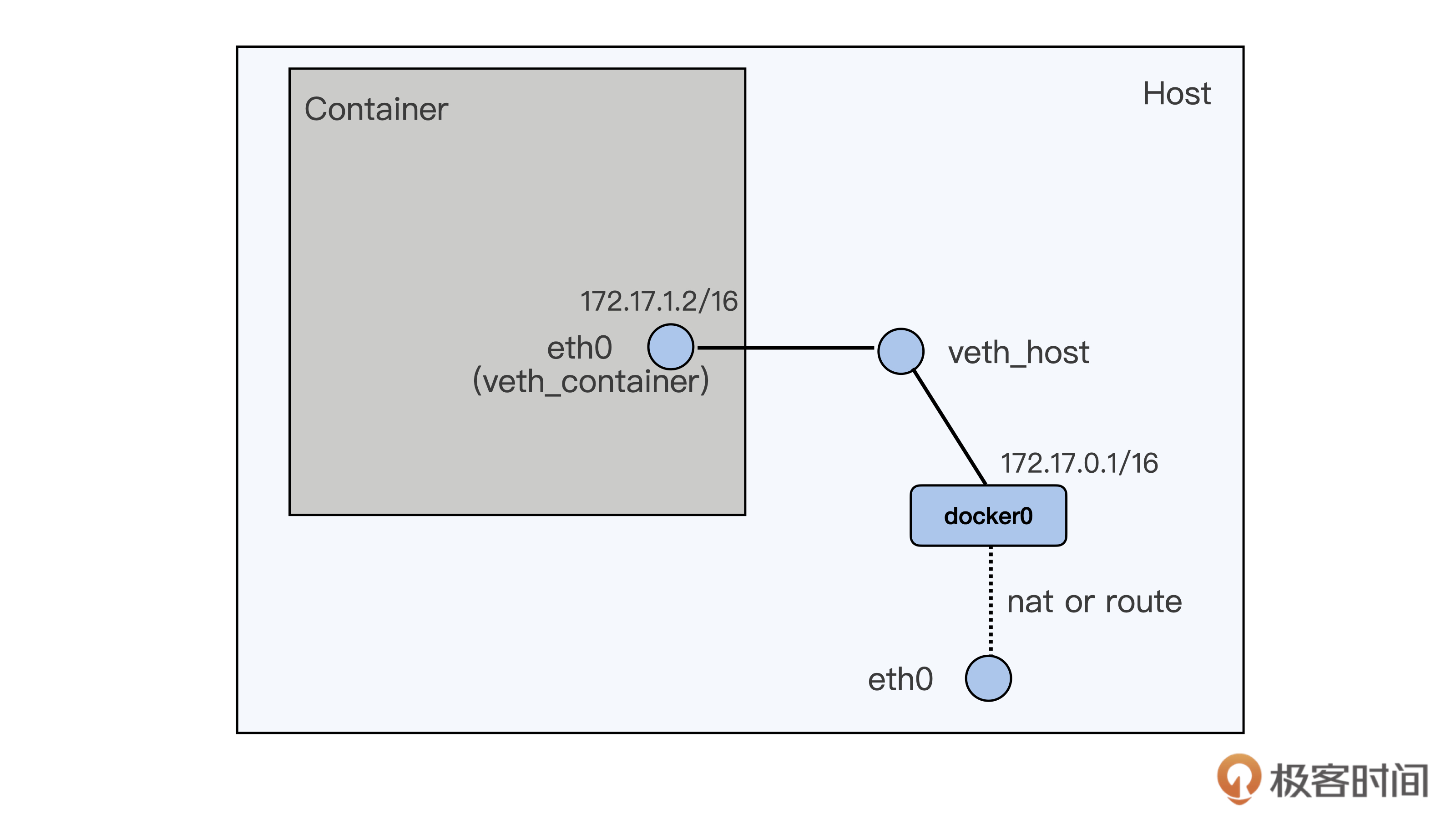
Docker 启动的容器缺省的网络接口就是用的这种,也就是会自动帮你搭建好上述的网络拓扑。但是,下面我们从头开始搭建上述的网络拓扑。主要用到的是 ip netns 这个命令,通过它来对 network namespace 进行操作。
-
首先,我们先启动一个不带网络配置的容器,和我们之前的命令比较,主要是多加上了"--network none"参数。我们可以看到,这样在启动的容器中,Network Namespace 里就只有 loopback 一个网络设备,而没有了 eth0 网络设备了。
# docker run -d --name if-test --network none centos:8.1.1911 sleep 36000 cf3d3105b11512658a025f5b401a09c888ed3495205f31e0a0d78a2036729472 # docker exec -it if-test ip addr 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever -
完成刚才的设置以后,我们可以在这个容器的 Network Namespace 里建立 veth。veth 是一个虚拟的网络设备,一般都是成对创建,而且这对设备是相互连接的。当每个设备在不同的 Network Namespaces 的时候,Namespace 之间就可以用这对 veth 设备来进行网络通讯了。
可以执行一下这个脚本完成 veth 的创建和通信。
pid=$(ps -ef | grep "sleep 36000" | grep -v grep | awk '{print $2}') echo $pid ln -s /proc/$pid/ns/net /var/run/netns/$pid # Create a pair of veth interfaces ip link add name veth_host type veth peer name veth_container # Put one of them in the new net ns ip link set veth_container netns $pid # In the container, setup veth_container ip netns exec $pid ip link set veth_container name eth0 ip netns exec $pid ip addr add 172.17.1.2/16 dev eth0 ip netns exec $pid ip link set eth0 up ip netns exec $pid ip route add default via 172.17.0.1 # In the host, set veth_host up ip link set veth_host up- 首先呢,我们先找到这个容器里运行的进程"sleep 36000"的 pid,通过 "/proc/$pid/ns/net"这个文件得到 Network Namespace 的 ID,这个 Network Namespace ID 既是这个进程的,也同时属于这个容器。
- 然后我们在"/var/run/netns/"的目录下建立一个符号链接,指向这个容器的 Network Namespace。完成这步操作之后,在后面的"ip netns"操作里,就可以用 pid 的值作为这个容器的 Network Namesapce 的标识了。
- 接下来呢,我们用 ip link 命令来建立一对 veth 的虚拟设备接口,分别是 veth_container 和 veth_host。从名字就可以看出来,veth_container 这个接口会被放在容器 Network Namespace 里,而 veth_host 会放在宿主机的 Host Network Namespace。
- 之后,用 ip link set veth_container netns $pid 把 veth_container 这个接口放入到容器的 Network Namespace 中。
- 再然后我们要把 veth_container 重新命名为 eth0,因为这时候接口已经在容器的 Network Namesapce 里了,eth0 就不会和宿主机上的 eth0 冲突了。
- 最后对容器内的 eht0,我们还要做基本的网络 IP 和缺省路由配置。因为 veth_host 已经在宿主机的 Host Network Namespace 了,就不需要我们做什么了,这时我们只需要 up 一下这个接口就可以了。
完成这些操作之后,就创建了一对 veth 虚拟设备接口,示意图如下所示。
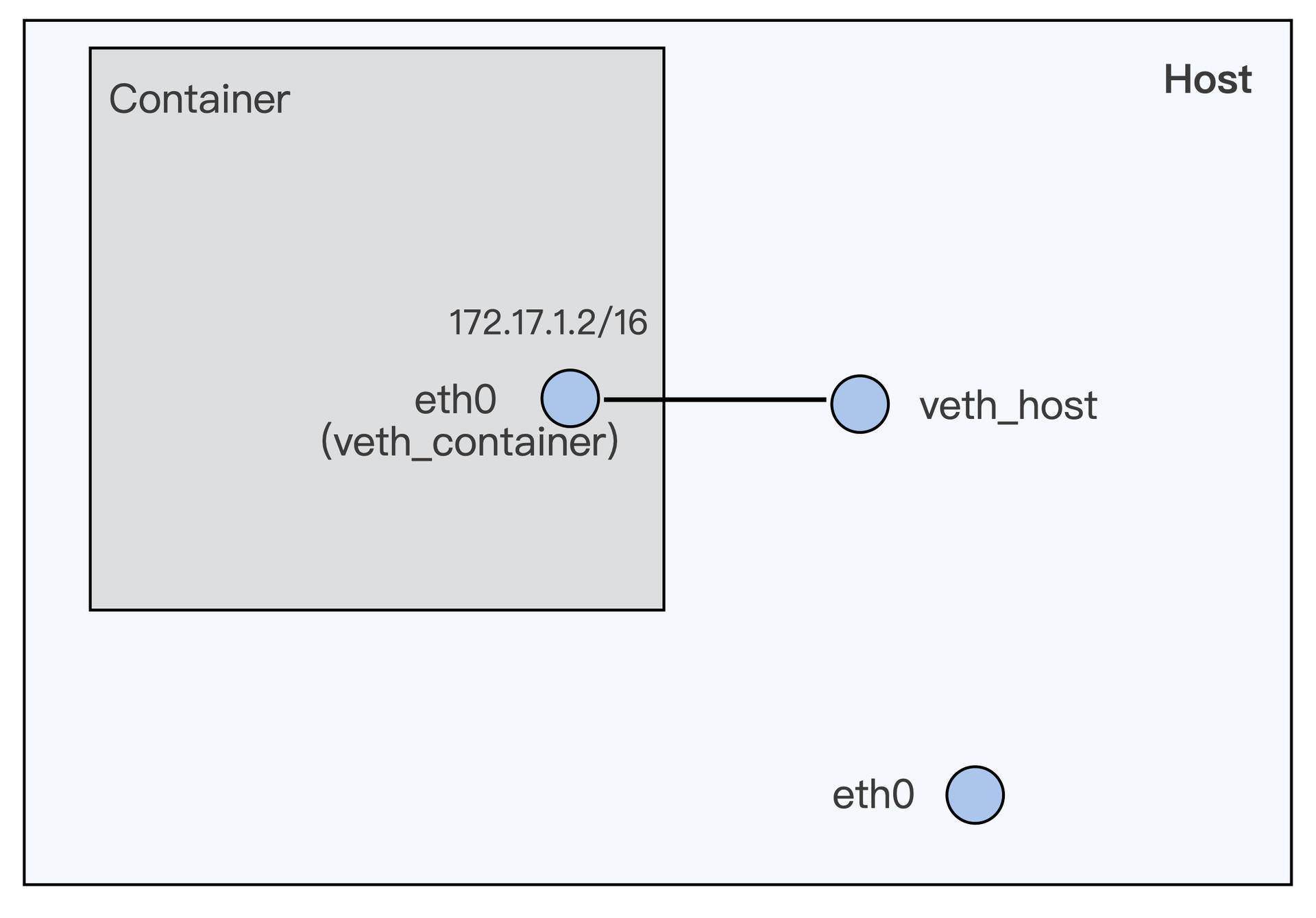
假如 veth_host 上加上一个 IP,172.17.1.1/16,就可以从容器里就可以 ping 通这个 IP 了。这也证明了从容器到宿主机可以利用这对 veth 接口来通讯了。
# ip addr add 172.17.1.1/16 dev veth_host # docker exec -it if-test ping 172.17.1.1 PING 172.17.1.1 (172.17.1.1) 56(84) bytes of data. 64 bytes from 172.17.1.1: icmp_seq=1 ttl=64 time=0.073 ms 64 bytes from 172.17.1.1: icmp_seq=2 ttl=64 time=0.092 ms ^C --- 172.17.1.1 ping statistics --- 2 packets transmitted, 2 received, 0% packet loss, time 30ms rtt min/avg/max/mdev = 0.073/0.082/0.092/0.013 ms -
完成上述的 veth 设备创建之后,就可以让数据包从容器的 network namespace 发送到 host network namespace 了。之后就需要考虑,怎么把到达 Host Network Namespace 的数据包从宿主机上的 eth0 发送出去。
这个时候就成了一个普通 Linux 节点上数据包转发的问题了。这里解决问题的方法有很多种,比如说用 nat 来做个转发,或者建立 Overlay 网络发送,也可以通过配置 proxy arp 加路由的方法来实现。Docker 缺省使用的是 bridge + nat 的转发方式。下面就来动手实现一下 bridge+nat 的转发方式。
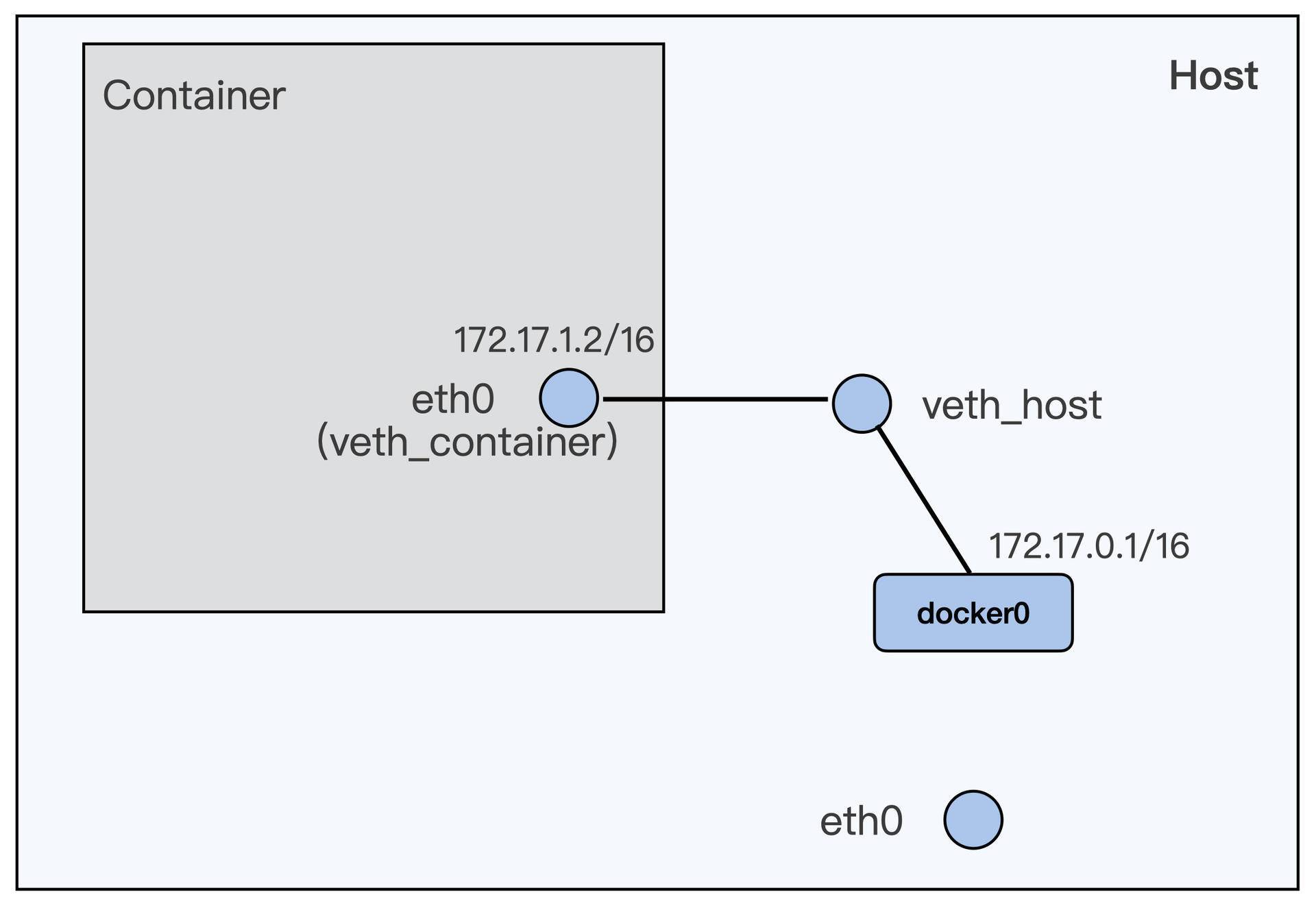
Docker 程序在节点上安装完之后,已经会自动建立了一个 docker0 的 bridge interface。所以我们只需要把第一步中建立的 veth_host 这个设备,接入到 docker0 这个 bridge 上即可。
# ip addr delete 172.17.1.1/16 dev veth_host ip link set veth_host master docker0如果之前你在 veth_host 上设置了 IP 的,就需先运行一下"ip addr delete 172.17.1.1/16 dev veth_host",把 IP 从 veth_host 上删除。
上述完成之后,网络拓扑如下所示。我们可以看到,容器和 docker0 组成了一个子网,docker0 上的 IP 就是这个子网的网关 IP。
-
如果我们要让子网通过宿主机上 eth0 去访问外网的话,那么需要加上 iptables 的规则,也就是下面这条规则。
iptables -P FORWARD ACCEPT同时,还需要将 linux 协议栈里的一个常用参数 ip_forward 设置为 1。ip_forward就是打开Linux类似路由器的功能,允许数据包从一个接口进入,根据路由从另外一个接口出去。
# cat /proc/sys/net/ipv4/ip_forward 0 # echo 1 > /proc/sys/net/ipv4/ip_forward
完成上述的配置之后,我们通过 bridge+nat 的方式,可以从容器中 ping 通外网的 IP 地址了。
# docker exec -it if-test ping 39.106.233.176
PING 39.106.233.176 (39.106.233.176) 56(84) bytes of data.
64 bytes from 39.106.233.176: icmp_seq=1 ttl=77 time=359 ms
64 bytes from 39.106.233.176: icmp_seq=2 ttl=77 time=346 ms
^C
--- 39.106.233.176 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 1ms
rtt min/avg/max/mdev = 345.889/352.482/359.075/6.593 ms
macvlan/ipvlan
除了 veth 之外,容器还可以选择其他的网络配置方式。在 Docker 的文档中提到了 macvlan 的配置方式,和 macvlan 很类似的方式还有 ipvlan。
它们的相同点就是都可以在一个物理的网络接口上再配置几个虚拟的网络接口。在这些虚拟的网络接口上,都可以配置独立的 IP,并且这些 IP 可以属于不同的 Namespace,也都有自己的 L2/L3 的配置方式。而不同点是,对于 macvlan,每个虚拟网络接口都有自己独立的 mac 地址;而 ipvlan 的虚拟网络接口是和物理网络接口共享同一个 mac 地址。
下面以 ipvlan 为例讲解配置的过程,主要是下面这段脚本,
https://github.com/chengyli/training/blob/main/net/latency/create_ipvlan.sh
docker run --init --name lat-test-1 --network none -d registry/latency-test:v1 sleep 36000
pid1=$(docker inspect lat-test-1 | grep -i Pid | head -n 1 | awk '{print $2}' | awk -F "," '{print $1}')
echo $pid1
ln -s /proc/$pid1/ns/net /var/run/netns/$pid1
ip link add link eth0 ipvt1 type ipvlan mode l2
ip link set dev ipvt1 netns $pid1
ip netns exec $pid1 ip link set ipvt1 name eth0
ip netns exec $pid1 ip addr add 172.17.3.2/16 dev eth0
ip netns exec $pid1 ip link set eth0 up
- 先启动一个容器,这里我们用"—network none"的方式来启动,也就是在容器中没有配置任何的网络接口。
- 接着我们在宿主机 eth0 的接口上增加一个 ipvlan 虚拟网络接口 ipvt1,再把它加入到容器的 Network Namespace 里面,重命名为容器内的 eth0,并且配置上 IP。这样我们就配置好了第一个用 ipvlan 网络接口的容器。
我们可以用同样的方式配置第二个容器,这样两个容器可以相互 ping 一下 IP,看看网络是否配置成功了。两个容器配置好之后,就像下面图中描述的一样了。从这张图里,你很容易就能看出 macvlan/ipvlan 与 veth 网络配置有什么不一样。容器的虚拟网络接口,直接连接在了宿主机的物理网络接口上了,形成了一个网络二层的连接。
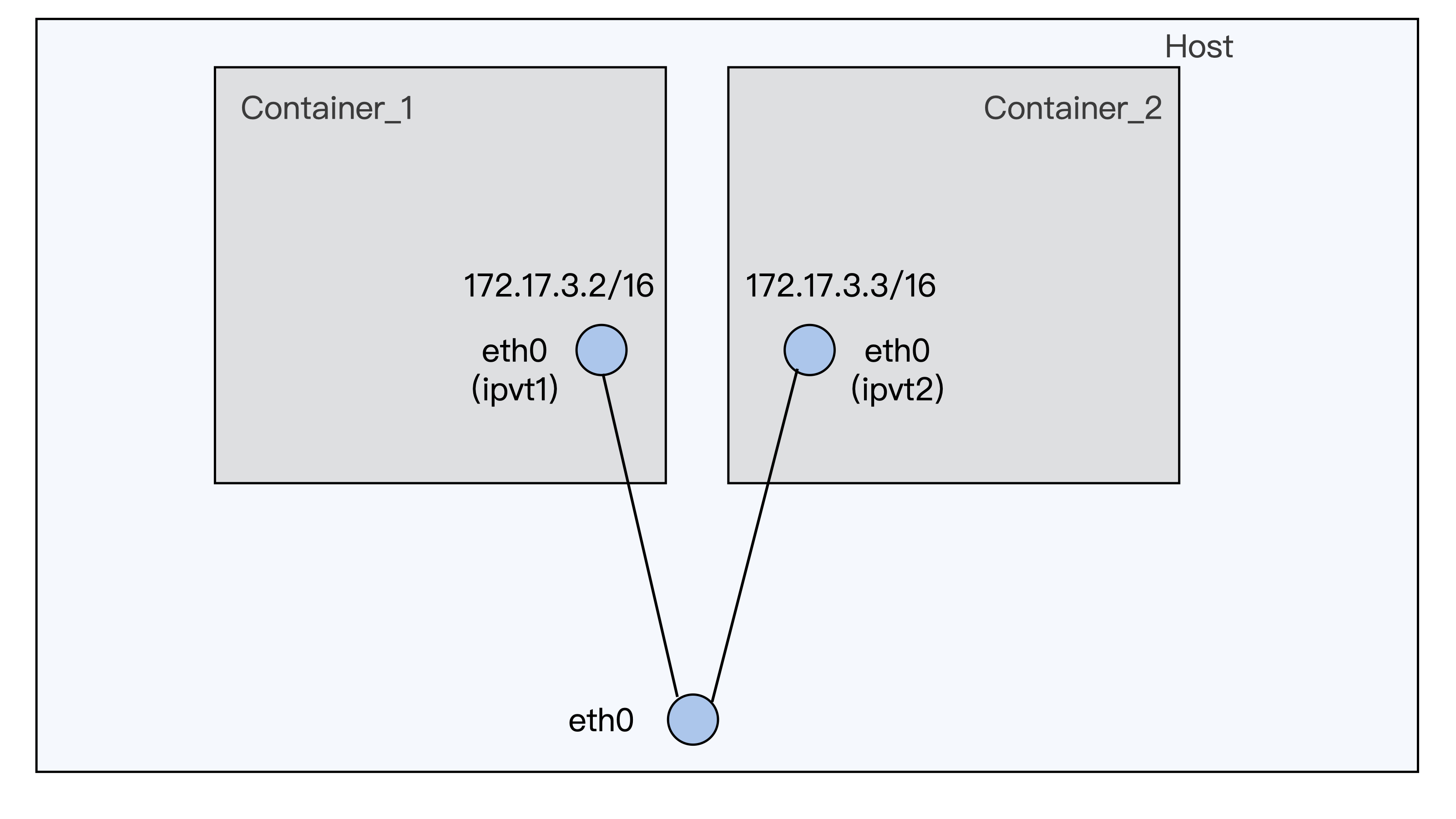
需要注意的是,由于 ipvlan/macvlan 网络接口直接挂载在物理网络接口上,对于需要使用 iptables 规则的容器,比如 Kubernetes 里使用 service 的容器,就不能工作了。个人理解的是,service 其实是在宿主机上配置了一堆规则,但是采用这种方式之后,数据包相当于没经过宿主机上 iptable 的处理,而是直接通过宿主机的 eth0 发出去了,所以 service 无法工作了。可以通过给容器的网络名称空间配置 iptables 规则来实现。
2. 容器网络的问题
2.1. 怎么修改容器里的网络参数
容器中的有些网络参数是从宿主机里那边继承过来的(也就是跟宿主机上是一致的),有些则是容器自己会进行初始化(/proc/sys/net下的参数,在容器中看到的,大多是network namespace下的)。
比如,我们在启动容器之前,先在宿主机上修改了几个参数,如下所示:
# # The default value:
# cat /proc/sys/net/ipv4/tcp_congestion_control
cubic
# cat /proc/sys/net/ipv4/tcp_keepalive_time
7200
# cat /proc/sys/net/ipv4/tcp_keepalive_intvl
75
# cat /proc/sys/net/ipv4/tcp_keepalive_probes
9
# # To update the value:
# echo bbr > /proc/sys/net/ipv4/tcp_congestion_control
# echo 600 > /proc/sys/net/ipv4/tcp_keepalive_time
# echo 10 > /proc/sys/net/ipv4/tcp_keepalive_intvl
# echo 6 > /proc/sys/net/ipv4/tcp_keepalive_probes
#
# # Double check the value after update:
# cat /proc/sys/net/ipv4/tcp_congestion_control
bbr
# cat /proc/sys/net/ipv4/tcp_keepalive_time
600
# cat /proc/sys/net/ipv4/tcp_keepalive_intvl
10
# cat /proc/sys/net/ipv4/tcp_keepalive_probes
6
然后,我们启动一个容器,再来看下容器里这些参数的值。可以看到,,tcp_congestion_control 的值是 bbr,和宿主机 Network Namespace 里的值是一样的,而其他三个 tcp keepalive 相关的值,都不是宿主机 Network Namespace 里设置的值,而是原来系统里的缺省值了。
# docker run -d --name net_para centos:8.1.1911 sleep 3600
deec6082bac7b336fa28d0f87d20e1af21a784e4ef11addfc2b9146a9fa77e95
# docker exec -it net_para bash
[root@deec6082bac7 /]# cat /proc/sys/net/ipv4/tcp_congestion_control
bbr
[root@deec6082bac7 /]# cat /proc/sys/net/ipv4/tcp_keepalive_time
7200
[root@deec6082bac7 /]# cat /proc/sys/net/ipv4/tcp_keepalive_intvl
75
[root@deec6082bac7 /]# cat /proc/sys/net/ipv4/tcp_keepalive_probes
9
这个是因为,在函数tcp_sk_init() (https://github.com/torvalds/linux/blob/v5.4/net/ipv4/tcp_ipv4.c#L2631)里,tcp_keepalive 的三个参数都是重新初始化的,而 tcp_congestion_control 的值是从 Host Namespace 里复制过来的。
那么,在容器里可以修改这些参数吗?针对一个普通容器来说,也就是不是 “privileged” 的那种容器来说,其实是不可以的。因为在这种容器中,出于安全考虑, /proc/sys 是只读 mount,所以是不允许修改 /proc/sys/net 下面的任何参数(这个是由于 mount namespace 限制)。另外很多操作也是不被允许的,比如 mount 一个文件系统。
runC 当初出于安全的考虑,把容器中所有 /proc 和 /sys 相关的目录缺省都做了 read-only mount 的处理。详细的说明你可以去看看这两个 commits:
- Mount /proc and /sys read-only, except in privileged containers(https://github.com/opencontainers/runc/commit/5a6b042e5395660ac8a6e3cc33227ca66df7c835)
- Make /proc writable, but not /proc/sys and /proc/sysrq-trigger(https://github.com/opencontainers/runc/commit/73c607b7ad5cea5c913f96dff17bca668534ad18)
另外,就算可以修改的话,其实也是没有特别大的用处的。因为,进入到容器中准备修改的时候,容器中的应用已经启动了,很多 tcp 链接都已经建立好了,那么即使新改了参数,对已经建立好的链接也不会生效。而重启应用,这在生产环境中通常来说是要避免的。
既然nsenter与docker exec 原理一样,为啥nsenter修改proc/sys/net不会报错无权限呢?docker exec 同时进入了容器的 pid/mnt/net namespace, 那么这个时候修改参数受到了 mnt namespace 的影响,而 nsenter 修改参数的时候,只是进入了容器的net namespace,并没有收到 mnt namespace 的影响。
那么,怎么才能修改容器中的这些参数并起作用呢?很明显,我们应该选择在容器启动时,容器中的应用程序还没启动之前,对这些参数进行修改。runC 在对 /proc/sys 目录做 read-only mount 之前,预留出了修改接口,这些接口就是用来修改容器里 "/proc/sys"下参数的,同样也是 sysctl 的参数。而 Docker 的–sysctl(https://docs.docker.com/engine/reference/commandline/run/#configure-namespaced-kernel-parameters-sysctls-at-runtime)或者 Kubernetes 里的allowed-unsafe-sysctls(https://kubernetes.io/docs/tasks/administer-cluster/sysctl-cluster/)特性也都利用了 runC 的 sysctl 参数修改接口,允许容器在启动时修改容器 Namespace 里的参数。比如,
# 3. docker run -d --name net_para --sysctl net.ipv4.tcp_keepalive_time=600 centos:8.1.1911 sleep 3600
7efed88a44d64400ff5a6d38fdcc73f2a74a7bdc3dbc7161060f2f7d0be170d1
# 4. docker exec net_para cat /proc/sys/net/ipv4/tcp_keepalive_time
600
runc的sysctl validation的代码:https://github.com/opencontainers/runc/blob/ff819c7e9184c13b7c2607fe6c30ae19403a7aff/libcontainer/configs/validate/validator.go#L135
4.1. 容器如何调试网络不通
遇到容器中网络不通的情况,我们先要理解自己的容器以及容器在宿主机上的配置,然后对主要设备上做 tcpdump 可以找到具体找出数据包在哪个环节时发生了中断。比如在采用 veth 网络配置的方式中,假如容器里头 ping 外网的一个 IP ping 不通,那么我们可以在容器中继续 ping 外网的 IP 39.106.233.176,然后在容器的 eth0 (veth_container),容器外的 veth_host,docker0,宿主机的 eth0 这一条数据包的路径上运行 tcpdump。这样就可以查到,到底在哪个设备接口上没有收到 ping 的 icmp 包。然后,结合内核网络配置参数,路由表信息,防火墙规则,定位出根本原因,解决这种网络不通的问题。
比如,假如在上述的配置中,如果我们不将 ip_forward 设置为 1,那么我们会发现 ping 的数据包到不了 eth0。
# 容器的 eth0
$ ip netns exec $pid tcpdump -i eth0 host 39.106.233.176 -nn
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes
00:47:29.934294 IP 172.17.1.2 > 39.106.233.176: ICMP echo request, id 71, seq 1, length 64
00:47:30.934766 IP 172.17.1.2 > 39.106.233.176: ICMP echo request, id 71, seq 2, length 64
00:47:31.958875 IP 172.17.1.2 > 39.106.233.176: ICMP echo request, id 71, seq 3, length 64
# veth_host
$ tcpdump -i veth_host host 39.106.233.176 -nn
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on veth_host, link-type EN10MB (Ethernet), capture size 262144 bytes
00:48:01.654720 IP 172.17.1.2 > 39.106.233.176: ICMP echo request, id 71, seq 32, length 64
00:48:02.678752 IP 172.17.1.2 > 39.106.233.176: ICMP echo request, id 71, seq 33, length 64
00:48:03.702827 IP 172.17.1.2 > 39.106.233.176: ICMP echo request, id 71, seq 34, length 64
# docker0
$ tcpdump -i docker0 host 39.106.233.176 -nn
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on docker0, link-type EN10MB (Ethernet), capture size 262144 bytes
00:48:20.086841 IP 172.17.1.2 > 39.106.233.176: ICMP echo request, id 71, seq 50, length 64
00:48:21.110765 IP 172.17.1.2 > 39.106.233.176: ICMP echo request, id 71, seq 51, length 64
00:48:22.134839 IP 172.17.1.2 > 39.106.233.176: ICMP echo request, id 71, seq 52, length 64
# host eth0
$ tcpdump -i eth0 host 39.106.233.176 -nn
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes
^C
0 packets captured
0 packets received by filter
0 packets dropped by kernel
4.1.1. 容器网络延时增加
采用 veth 这种网络之后,容器向外发送数据包的路径,相比宿主机上直接向外发送数据包的路径,很明显要多了一次接口层的发送和接收。尽管 veth 是虚拟网络接口,在软件上还是会增加一些开销。如果我们的应用程序对网络性能有很高的要求,特别是之前运行在物理机器上,现在迁移到容器上的,如果网络配置采用 veth 方式,就会出现网络延时增加的现象。

具体原因如下,veth 的虚拟网络接口一般都是成对出现,就像上图里的 veth_container 和 veth_host 一样。在每次网络传输的过程中,数据包都需要通过 veth_container 这个接口向外发送,而且必须保证 veth_host 先接收到这个数据包。虽然 veth 是一个虚拟的网络接口,但是在接收数据包的操作上,这个虚拟接口和真实的网路接口并没有太大的区别。这里除了没有硬件中断的处理,其他操作都差不多,特别是软中断(softirq)的处理部分其实就和真实的网络接口是一样的。
可以阅读 Linux 内核里的 veth 的驱动代码(https://github.com/torvalds/linux/blob/v5.4/drivers/net/veth.c)。veth 发送数据的函数是 veth_xmit(),它里面的主要操作就是找到 veth peer 设备,然后触发 peer 设备去接收数据包。针对上面的例子来说,veth_container 这个接口会调用 veth_xmit() 来发送数据包,而在这个函数中会触发它的 peer 设备 veth_host 去调用 netif_rx() 来接收数据包。而 netif_rx() 是一个网络设备驱动里面标准的接收数据包的函数,netif_rx() 里面会为这个数据包 raise 一个 softirq。虽然 softirq 的执行速度很快,但是相比宿主机里的方式还是多了一层处理,所以还是会带来额外的开销。
static netdev_tx_t veth_xmit(struct sk_buff *skb, struct net_device *dev)
{
…
/* 拿到veth peer设备的net_device */
rcv = rcu_dereference(priv->peer);
…
/* 将数据送到veth peer设备 */
if (likely(veth_forward_skb(rcv, skb, rq, rcv_xdp) == NET_RX_SUCCESS)) {
…
}
static int veth_forward_skb(struct net_device *dev, struct sk_buff *skb,
struct veth_rq *rq, bool xdp)
{
/* 这里最后调用了 netif_rx() */
return __dev_forward_skb(dev, skb) ?: xdp ?
veth_xdp_rx(rq, skb) :
netif_rx(skb);
}
__raise_softirq_irqoff(NET_RX_SOFTIRQ);
另外,除了 softirq 的性能损坏,应该还包括 docker0 网桥的自身处理逻辑(作为 veth_container 的主设备接管其数据包的处理权)以及 docker0 -> eth0 的转发逻辑带来的损耗,但是相比较而言,veth pair softirq的处理带来的开销要更明显一些。
下面使用 netperf 来具体测量下,有两台虚拟机或者物理机,这两台机器同处于一个二层网络中,具体配置如下所示。
- 在第一台机器上启动一个 veth 接口的容器,参考这个脚本的链接(https://github.com/chengyli/training/blob/master/net/latency/start_container.sh)。
- 在第二台机器上,启动一个 netserver。
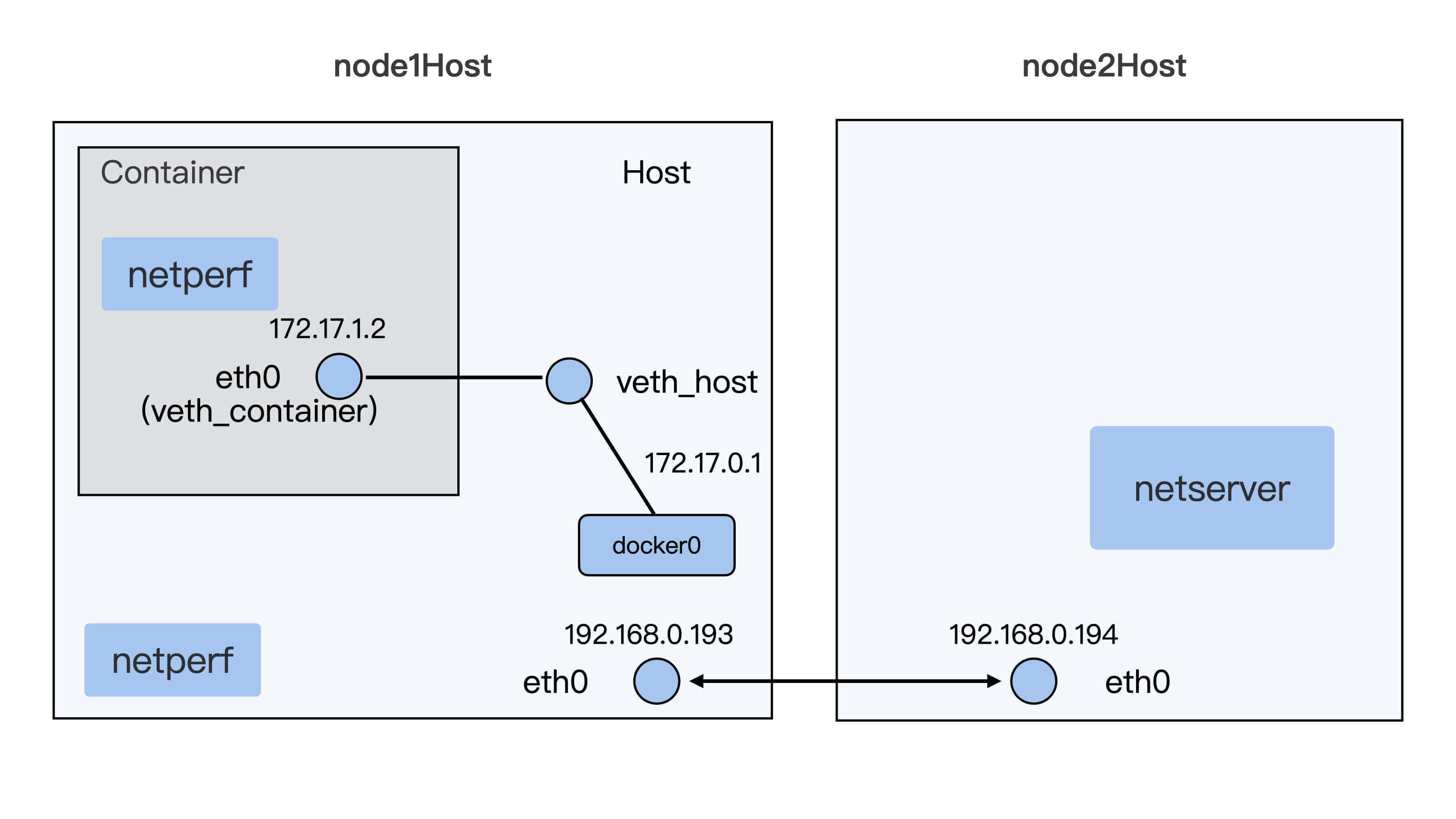
然后呢,我们分别在容器里和宿主机上运行与 netserver 交互的 netperf,并且使用 netperf 的 TCP_RR 测试用例。TCP_RR 是 netperf 里专门用来测试网络延时的,缺省每次运行 10 秒钟。运行以后,我们还要计算平均每秒钟 TCP request/response 的次数,这个次数越高,就说明延时越小。
-
先在第一台机器的宿主机上直接运行 netperf 的 TCP_RR 测试用例 3 轮,得到的值分别是 2504.92,2410.14 和 2422.81,计算一下可以得到三轮 Transactions 平均值是 2446/s。
# ./netperf -H 192.168.0.194 -t TCP_RR MIGRATED TCP REQUEST/RESPONSE TEST from 0.0.0.0 (0.0.0.0) port 0 AF_INET to 192.168.0.194 () port 0 AF_INET : first burst 0 Local /Remote Socket Size Request Resp. Elapsed Trans. Send Recv Size Size Time Rate bytes Bytes bytes bytes secs. per sec 16384 131072 1 1 10.00 2504.92 16384 131072 # ./netperf -H 192.168.0.194 -t TCP_RR MIGRATED TCP REQUEST/RESPONSE TEST from 0.0.0.0 (0.0.0.0) port 0 AF_INET to 192.168.0.194 () port 0 AF_INET : first burst 0 Local /Remote Socket Size Request Resp. Elapsed Trans. Send Recv Size Size Time Rate bytes Bytes bytes bytes secs. per sec 16384 131072 1 1 10.00 2410.14 16384 131072 # ./netperf -H 192.168.0.194 -t TCP_RR MIGRATED TCP REQUEST/RESPONSE TEST from 0.0.0.0 (0.0.0.0) port 0 AF_INET to 192.168.0.194 () port 0 AF_INET : first burst 0 Local /Remote Socket Size Request Resp. Elapsed Trans. Send Recv Size Size Time Rate bytes Bytes bytes bytes secs. per sec 16384 131072 1 1 10.00 2422.81 16384 131072 -
之后,在容器中运行一下 netperf 的 TCP_RR,也一样运行三轮,计算一下这三次的平均值,得到的值是 2141。
上述的测试表明,容器中的 Transactions 下降了大概 12.5%,也就是网络的延时超过了 10%。
针对 veth 带来的额外开销,在网络延时敏感的应用程序中,可以考虑使用 ipvlan/macvlan 的容器网络配置方式来替换缺省的 veth 网络配置。Ipvlan/macvlan 直接在物理网络接口上虚拟出接口,在发送对外数据包的时候可以直接通过物理接口完成,没有节点内部类似 veth 的那种 softirq 的开销。容器使用 ipvlan/maclan 的网络接口,它的网络延时可以非常接近物理网络接口的延时。
这个从 ipvlan 接口的发送代码中可以看到,发送函数会直接找到 ipvlan 虚拟接口对应的物理网络接口,然后通过这个物理接口将数据直接发送出去,没有了内部额外的 softirq 处理开销。比如,在这个例子中,就是会调用 dev_queue_xmit() 通过物理接口将数据直接发送出去。
static int ipvlan_xmit_mode_l2(struct sk_buff *skb, struct net_device *dev)
{
…
if (!ipvlan_is_vepa(ipvlan->port) &&
ether_addr_equal(eth->h_dest, eth->h_source)) {
…
} else if (is_multicast_ether_addr(eth->h_dest)) {
…
}
/*
* 对于普通的对外发送数据,上面的if 和 else if中的条件都不成立,
* 所以会执行到这一步,拿到ipvlan对应的物理网路接口设备,
* 然后直接从这个设备发送数据。
*/
skb->dev = ipvlan->phy_dev;
return dev_queue_xmit(skb);
}
下面这张图是两者网络延时的监控图,图里蓝色的线表示程序运行在 veth 容器中,黄色线表示程序运行在 ipvlan 的容器里,绿色的线代表程序直接运行在物理机上。从这张延时(Latency)图里,我们可以看到,在 veth 容器里程序的网络延时要明显高一些,而程序在 ipvlan 容器里的网络延时已经比较接近物理机上的网络延时了。所以,对于网络延时敏感的应用程序,我们可以考虑使用 ipvlan/macvlan 的容器网络配置方式来替换缺省的 veth 网络配置。

4.1.2. 容器网络中乱序增加
在采用 veth 方式的容器网络模式下,当把应用程序从物理机迁移到容器之后,从网络监控中发现,容器中数据包的重传的数量要比在物理机里高了不少。
我们可以在容器里运行一下 iperf3 命令,向容器外部发送一下数据,从 iperf3 的输出"Retr"列里,我们可以看到有多少重传的数据包。比如下面的例子里,我们可以看到有 162 个重传的数据包。
# iperf3 -c 192.168.147.51
Connecting to host 192.168.147.51, port 5201
[ 5] local 192.168.225.12 port 51700 connected to 192.168.147.51 port 5201
[ ID] Interval Transfer Bitrate Retr Cwnd
[ 5] 0.00-1.00 sec 1001 MBytes 8.40 Gbits/sec 162 192 KBytes
…
- - - - - - - - - - - - - - - - - - - - - - - - -
[ ID] Interval Transfer Bitrate Retr
[ 5] 0.00-10.00 sec 9.85 GBytes 8.46 Gbits/sec 162 sender
[ 5] 0.00-10.04 sec 9.85 GBytes 8.42 Gbits/sec receiver
iperf Done.
网络中发生了数据包的重传,
- 有可能是数据包在网络中丢了,
- 也有可能是数据包乱序导致的。
我们可以使用 tcpdump 去抓包,但是对于大流量的网络来说,用 tcpdump 抓包瞬间就会有几个 GB 的数据。这样做的话,带来的额外系统开销比较大,特别是在生产环境中这个方法也不太好用。另外,我们还可以 netstat 命令来查看协议栈中的丢包和重传的情况。比如说,在运行上面的 iperf3 命令前后,我们都在容器的 Network Namespace 里运行一下 netstat 看看重传的情况。
我们会发现,一共发生了 162 次(604-442)快速重传(fast retransmits),这个数值和 iperf3 中的 Retr 列里的数值是一样的。
-bash-4.2# nsenter -t 51598 -n netstat -s | grep retran
454 segments retransmited
442 fast retransmits
-bash-4.2# nsenter -t 51598 -n netstat -s | grep retran
616 segments retransmited
604 fast retransmits
那么,有大量的 "fast retransmits" 意味着存在大量的乱序包。我们可以使用 netstat 查看"reordering",这个时候就可以看到大量的 SACK 发现的乱序包。
-bash-4.2# nsenter -t 51598 -n netstat -s | grep reordering
Detected reordering 501067 times using SACK
其实,在云平台的这种网络环境里,网络包乱序 +SACK 之后,产生的数据包重传的量要远远高于网络丢包引起的重传。
那么为什么会这样呢?
前面提到,在使用 veth 接口从容器向外发送数据包时,会触发 peer veth 设备去接收数据包,这个接收的过程就是一个网络的 softirq 的处理过程。在触发 softirq 之前,veth 接口会模拟硬件接收数据的过程,通过 enqueue_to_backlog() 函数把数据包放到某个 CPU 对应的数据包队列里(softnet_data)(个人理解这里是 peer veth 设备的接受队列)。
static int netif_rx_internal(struct sk_buff *skb)
{
int ret;
net_timestamp_check(netdev_tstamp_prequeue, skb);
trace_netif_rx(skb);
#ifdef CONFIG_RPS
if (static_branch_unlikely(&rps_needed)) {
struct rps_dev_flow voidflow, *rflow = &voidflow;
int cpu;
preempt_disable();
rcu_read_lock();
cpu = get_rps_cpu(skb->dev, skb, &rflow);
if (cpu < 0)
cpu = smp_processor_id();
ret = enqueue_to_backlog(skb, cpu, &rflow->last_qtail);
rcu_read_unlock();
preempt_enable();
} else
#endif
{
unsigned int qtail;
ret = enqueue_to_backlog(skb, get_cpu(), &qtail);
put_cpu();
}
return ret;
}
从上面的代码,我们可以看到,在缺省的状况下(也就是没有 RPS 的情况下),enqueue_to_backlog() 把数据包放到了“当前运行的 CPU”(get_cpu())对应的数据队列中。如果是从容器里通过 veth 对外发送数据包,那么这个“当前运行的 CPU”就是容器中发送数据的进程所在的 CPU。
对于多核的系统,这个发送数据的进程可以在多个 CPU 上切换运行。进程在不同的 CPU 上把数据放入队列并且 raise softirq 之后,因为每个 CPU 上处理 softirq 是个异步操作,所以两个 CPU network softirq handler 处理这个进程的数据包时,处理的先后顺序并不能保证。比如,会可能先接受到 seq3,然后再接收到 seq2。而针对这种情况,SACK 可能会引起 Seq 2 的立刻重传。因此,veth 对的这种发送数据方式增加了容器向外发送数据出现乱序的几率。

针对这种情况该怎么处理呢?
对于 veth 接口的这种发包方式,有办法减少一下乱序的几率吗?其实,我们在上面 netif_rx_internal() 那段代码中,有一段在"#ifdef CONFIG_RPS"中的代码。我们看到这段代码中在调用 enqueue_to_backlog() 的时候,传入的 CPU 并不是当前运行的 CPU,而是通过 get_rps_cpu() 得到的 CPU。那么,只要对应的 veth 接口上打开了 RPS 的配置以后,那么对于同一个数据流,就可以始终选择同一个 CPU 了,从而减少乱序的出现。
打开 RPS 的方法挺简单的,只要去 /sys 目录下,在网络接口设备接收队列中修改队列里的 rps_cpus 的值,这样就可以了。rps_cpus 是一个 16 进制的数,每个 bit 代表一个 CPU。假如,在一个 12CPU 的节点上,想让 host 上的 veth 接口在所有的 12 个 CPU 上,都可以通过 RPS 重新分配数据包。那么就可以执行下面这段命令。
# cat /sys/devices/virtual/net/veth57703b6/queues/rx-0/rps_cpus
000
# echo fff > /sys/devices/virtual/net/veth57703b6/queues/rx-0/rps_cpus
# cat /sys/devices/virtual/net/veth57703b6/queues/rx-0/rps_cpus
fff
另外,TCP 的乱序包,并不一定都会产生数据包的重传。想要减少网络数据包的重传,我们还可以考虑协议栈中其他参数的设置,比如 /proc/sys/net/ipv4/tcp_reordering。
这里有点问题,因为正常的网络收包过程中应该会产生一次硬中断和一次软中断,那么到了 skb 阶段的话,应该已经是软中断的部分了,而这里为什么还会产生一个软中断?
个人理解这里会产生软中断是因为可能在正常的数据收包发包的过程是只产生一次硬中断和一次软中断,而对于这种情况下,在软中断的处理过程中还会产生一次软中断。
巨人的肩膀
- 极客时间.《容器实战》

