1. Kubernetes 基础
1.1. 历史
2015 年 4 月 Google 发布了 Borg 论文。Borg 系统被誉为 Google 内部最强大的“秘密武器”。因为,相比于 Spanner、BigTable 等相对上层的项目,Borg 是承载 Google 公司整个基础设施的核心依赖。在 Google 公司公开发表的基础设施体系论文中,如图(来自于 Google Omega 论文的第一作者的博士毕业论文)所示。该图描绘了当时 Google 已经公开发表的整个基础设施栈。在这个图中,MapReduce、BigTable 等知名项目位于上层,而 Borg 和它的继任者 Omega 位于整个技术栈的最底层。

由于 Borg 的定位,所以 Borg 最不可能开源。但是我们 Kubernetes 项目可以让我们一睹风采。相比很多基础设施领域先有工程实践、后有方法论的发展路线不同,Kubernetes 项目的理论基础要比工程实践走得靠前得多,这也是正是因为 Kubernetes 借鉴了 Borg 的理论,它从一开始就比较幸运地站上了一个他人难以企及的高度:Kubernetes 这个项目每一个核心特性的提出,几乎都脱胎于 Borg/Omega 系统的设计与经验。除此之外,这些特性在开源社区落地的过程中,又在整个社区的合力之下得到了极大的改进,修复了很多当年遗留在 Borg 体系中的缺陷和问题。Kubernetes 项目向我们体现了一种独有的“先进性”和“完备性”。
1.2. Kubernetes 架构
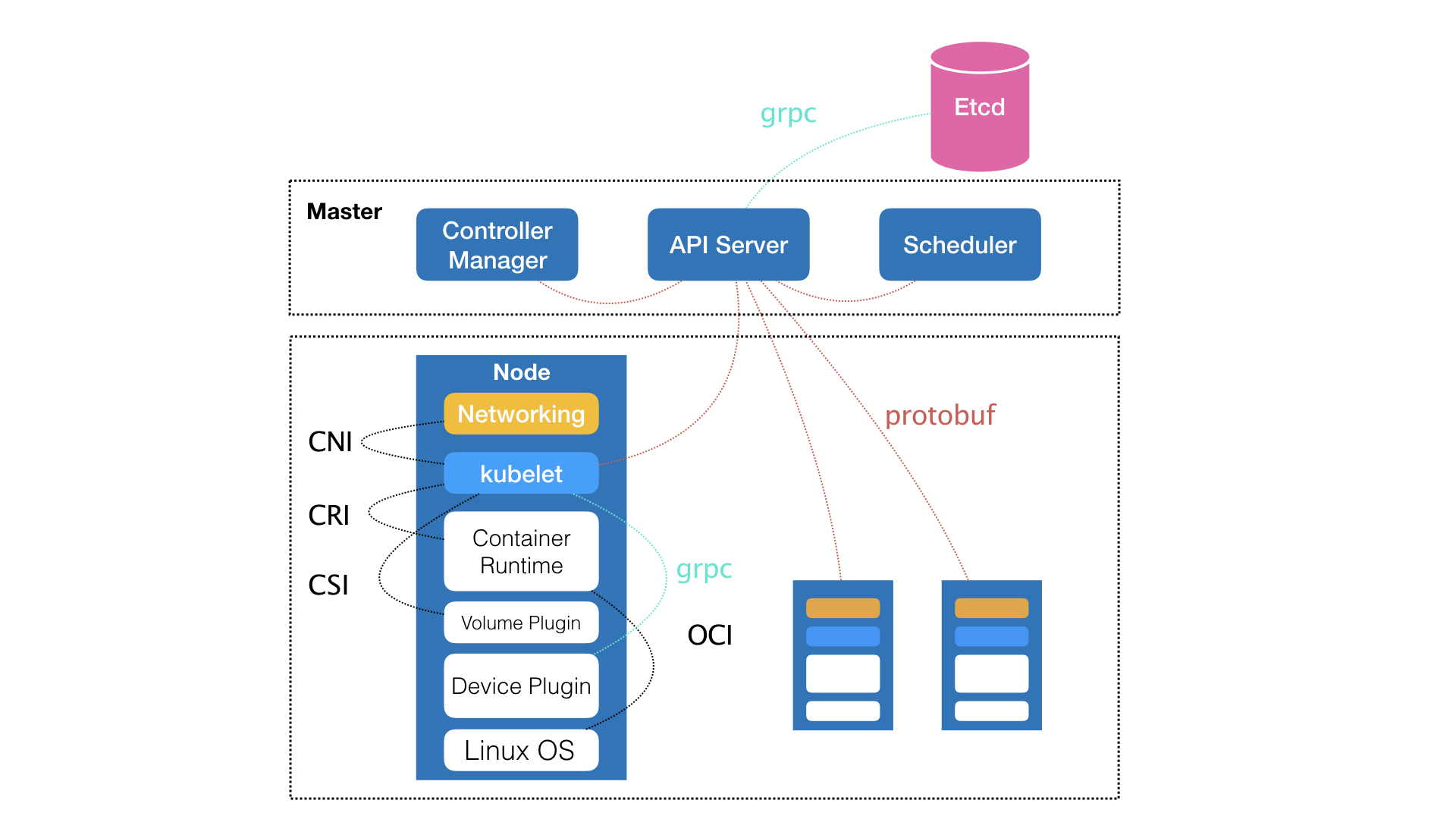
Kubernetes 项目的架构跟它的原型项目 Borg 非常类似,都由 Master 和 Node 两种节点组成,而这两种节点分别对应着控制节点和计算节点。
-
Master 节点也就是控制节点,是整个集群的中枢,是 Stateful 的,负责维持整个 Kubernetes 集群的状态。它由三个独立组件组合而成,分别是:负责 API 服务的 kube-apiserver、负责调度的 kube-scheduler,以及负责容器编排的 kube-controller-manager。整个集群的持久化数据,则由 kube-api-server 处理后保存在 Etcd 中。为了保证职责单一,Master 节点一般不会部署容器。
Borg 对 Kubernetes 的指导体现在 Master 节点上,Borg 和 Kubernetes 的 Master 节点虽然实现细节上可能会不同,但它们出发的高度却是一致的,即:如何编排、管理、调度用户提交的作业。
-
Node 节点也就是计算节点,它才是部署的容器真正运行的地方。它上面最核心的是 kubelet 组件(master 节点上也会有 kubelet 组件),Kubelet 主要负责同容器运行时(比如 Docker 项目)打交道,使用了 CRI(Container Runtime Interface)的远程调用接口。这个接口定义了容器运行时的各项核心操作,比如启动一个容器需要的所有参数。这也是为什么 Kubernetes 项目并不关心你使用的是什么容器运行时,只要这个容器运行时能够运行标准的容器镜像,它就可以通过实现 CRI 接入到 Kubernetes 项目当中。
具体的容器运行时,比如 Docker 项目,则一般通过 OCI 这个容器运行时规范同底层的 Linux 操作系统进行交互,即:把 CRI 请求翻译成对 Linux 操作系统的调用,比如调用 Namespace 和 Cgroups 等。
此外,kubelet 还通过 gRPC 协议与 Device Plugin 进行交互,这个插件是 Kubernetes 用来管理 GPU 等宿主机物理设备的主要组件,也是基于 Kubernetes 项目进行机器学习训练、高性能作业支持等工作必须关注的功能。
kubelet 还可以通过 CNI(Container Networking Interface)和 CSI(Container Storage Interface)接口分别调用网络插件和存储插件为容器配置网络和持久化存储。
kubelet 这个名字来自于 Borg 项目中的同源组件 Borglet。只是,Borg 项目中并不支持容器技术,而只是简单地使用了 Linux Cgroups 对进程进行限制。这也就意味着,像 Docker 这样的“容器镜像”在 Borg 中并不存在,自然不需要对容器镜像进行管理,但是 Google 内部却有在使用一个包管理工具,名叫 Midas Package Manager(MPM),它可以部分取代 Docker 镜像的角色。之外,Borglet 组件也不需要考虑如何同 Docker 进行交互,也不需要支持 CRI、CNI、CSI 等诸多容器技术接口。可以说 kubelet 完全就是为了实现 Kubernetes 对容器的管理能力而重新实现的一个组件,与 Borg 之间并没有直接的传承关系。
Kubernetes 项目并没有像同时期的各种“容器云”项目那样,把 Docker 作为整个架构的核心,而仅仅把它作为最底层的一个容器运行时实现。也就相当于把 Docker 仅仅看成一种新的应用打包方式,那么 Borg 过去在大规模作业管理与编排上的经验就可以直接应用到 Kubernetes 项目上。
1.3. API 对象
对于如何编排、管理、调度用户提交的作业,Kubernetes 有着独特的观点,也就是 Borg 这篇论文中提到的:运行在大规模集群中的各种任务之间,实际上存在着各种各样的关系。这些关系的处理,才是作业编排和管理系统最困难的地方。所以,Kubernetes 项目最主要的设计思想是,从更宏观的角度,以统一的方式来定义任务之间的各种关系,并且为将来支持更多种类的关系留有余地。
比如,那些非常频繁交互和访问的应用或者直接通过本地文件进行交互的应用往往会直接被部署在同一台机器上,通过 locahost 通信或者通过磁盘目录交换文件,所以在 Kubernetes 项目中,这些容器则会被划分到一个“Pod”中,Pod 里的容器共享同一个 Network Namespace、同一组数据卷,从而达到高效率交换信息的目的。
Pod 是 Kubernetes 项目中运行容器的最小单位,源于 Google Borg 论文中一个名叫 Alloc 的设计。一个 Pod 具备一个集群 IP 且端口共享。Pod 里面可以运行一个或多个容器,但是最佳做法还是一个 Pod 里面运行一个容器,因为一个 Pod 里面运行多个容器,容器会竞争 Pod 的资源,也会影响 Pod 的启动速度,而只运行一个容器,可以方便我们快速定位问题,监控指标也比较明确。
再比如,Web 应用与数据库之间的访问关系,它们往往不部署在同一台机器上,因为这样即使 Web 应用所在的机器宕机了,那么数据库也完全不受影响。但是,Web 服务所在的 Pod 又该如何找到数据库所在的 Pod 呢(对于一个 Pod 来说,它的 IP 地址不是固定),对此 Kubernetes 项目则提供了一种 “Service” 的服务。Kubernetes 项目的做法是给 Pod 绑定一个 Service 服务,而 Service 服务声明的 IP 地址等信息是“终生不变”的。这个时候,对于 Web 应用来说只需要关心数据库 Pod 的 Service 信息即可。而 Service 后端真正的 Pod 的 IP 地址、端口等信息的自动更新、维护,则是 Kubernetes 项目的职责。
Service 服务的主要作用,就是作为 Pod 的代理入口,从而代替 Pod 对外暴露一个固定的网络地址。另外,Kubernetes 集群中会有自己的私有网络,集群内部可以互相访问。假如想要从外部访问 Kubernetes 集群提供的服务,也可通过 Service 将服务暴露出来。
如果现在两个 Pod 之间有“访问关系”,还需要在发起时加上授权信息,比如 Web 应用对数据库访问时需要 Credential(数据库的用户名和密码)信息。此时,Kubernetes 提供了 Secret 对象,这个对象其实是一个保存在 Etcd 里的键值对数据。那么,当你指定的 Pod 启动时,Kubernetes 会自动把存在 Etcd 里的 Secert 里的数据以 Volume 的方式挂载到容器里,这样 Web 应用就可以访问数据库了。
除了应用与应用之间的关系外,“如何容器化这个应用”是第二个重要因素。为此,Kubernetes 基于 Pod 的基础上定义了新的对象,比如 Job 用来描述一次性运行的 Pod(比如大数据任务);再比如 DaemonSet,用来描述每个宿主机上必须运行一个副本的守护进程服务;再比如 CronJob,则用于描述定时任务。
综上来说,Kubernetes 推崇的方法是:
- 首先,通过一个“编排对象”,比如 Pod、Job、CronJob 来描述你试图管理的应用;
- 之后,再为它对应一些“服务对象”,比如 Service、Secret、Horizontal Pod Autoscaler(自动水平扩展器)。这些对象,会负责具体的平台级功能。
这种使用方法,就是所谓的“声明式 API”。这种 API 对应的“编排对象”和“服务对象”,都是 Kubernetes 项目中的 API 对象。
1.4. 如何启动 Kubernetes 任务
我们要如何通过 Kubernetes 来启动容器化任务呢?比如,现在我们制作好了一个 Nginx 容器镜像,希望 Kubernetes 帮我们启动这个镜像,并且要求平台帮我运行两个完全相同的 Nginx 副本,以负载均衡的方式共同对外提供服务。那么只需要编写一个如下所示的 YAML 文件即可(比如 nginx-deployment.yaml)
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
在上述的 YAML 文件中,我们定义了一个 Deployment 对象,它的主体部分(spec.template)是一个使用 Nginx 镜像的 Pod,而这个 Pod 的副本数是 2(replicas=2)。之后,使用如下的命令,两个完全相同的 Nginx 容器副本就被启动了。
kubectl create -f nginx-deployment.yaml
1.5. kubectl
在如何启动任务的时候用到了 kubectl ,那么 kubectl 和 Kubernetes 的架构图,如图所示:
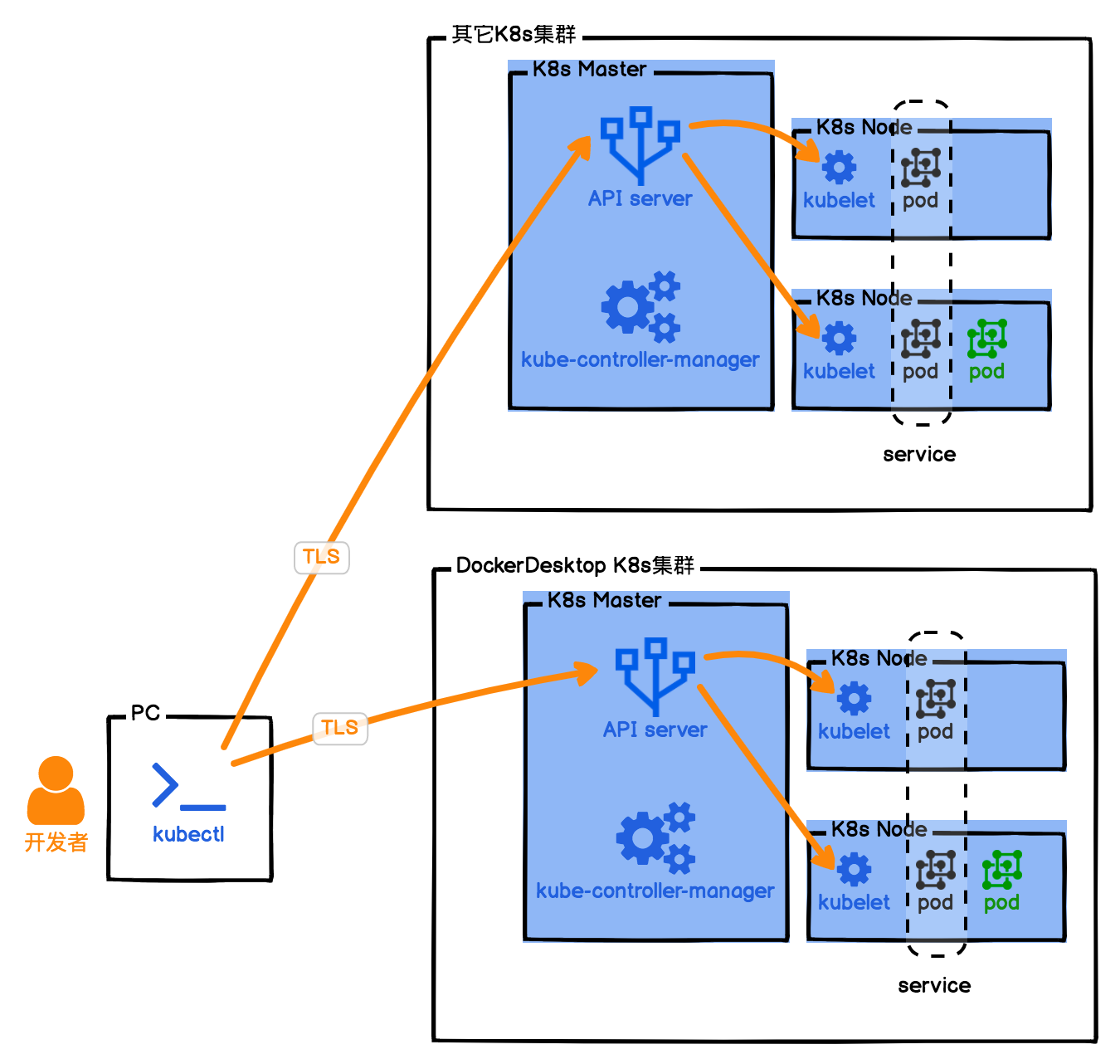
kubectl 是 K8s 的命令行操作工具,通过它可以控制 K8s 集群,可以在一台电脑上同时控制多个 K8s 集群。只是在控制集群的时候,需要指定当前操作的上下文。
1.6. 总结
Yarn、Mesos 以及 Swarm 所擅长的是如何把一个容器,按照某种规则,放置到某个最佳节点上运行起来,这种更多被称之为“调度”。而 Kubernetes 所擅长的是按照用户的意愿和整个系统的规则,完全自动化地处理好容器之间的各种关系。这种功能,也就是我们经常听到的一个概念:编排。所以说,Kubernetes 的本质是为用户提供一个具有普遍意义的容器编排工具。但是 Kubernetes 不仅限于一个工具,它真正的价值是提供了一套基于容器构建分布式系统的基础依赖。
巨人的肩膀
- 极客时间.《深入剖析Kubernetes》.张磊.“从容器到容器云:谈谈Kubernetes的本质”
- 极客时间.《Serverless入门课》.蒲松洋.“搭建私有Serverless(一):K8s和云原生CNCF”

