1. 计算机常见的性能指标
1.1. 处理机字长
处理机运算器中一次能够完成二进制数运算的位数,如32位、64位。
1.2. 响应时间(执行时间)
用户发出请求或者指令,到系统产生响应之间的时间,用时间单位来度量。可以理解为计算机“跑得更快”,相当于执行一个程序,到底需要花多少时间。一般响应时间的倒数定义为性能:性能 = 1/ 响应时间,响应时间越短,性能的数值越大。
1.3. 吞吐率:
表征一台计算机在某一时间间隔内能够处理的信息量。可以理解为让计算机“搬得更多”,相当于在一定的时间范围内,到底能处理多少数据或者执行多少程序指令。
1.4. 主频/时钟周期
-
CPU的工作节拍受主时钟控制,主时钟不断产生固定频率的时钟,主时钟的频率叫做CPU的主频。度量单位为MHz、GHz。
假如主频为2.8GHz,那么就可以认为一秒内,可以执行的简单指令的数量是2.8G;
超频的意思就是频率太高了,比如我们把买回来的CPU内部的时钟给调快了,那么频率自然上去了,但是散热的压力也越来越大。
-
主频的倒数称为CPU的时钟周期,度量单位是微秒、纳秒。
CPU内部有一个晶体振荡器(Oscillator Crystal),简称晶振,CPU的时钟周期也可以说是晶振一次的时间。
1.5. CPU执行时间
表示CPU执行一般程序所占用的CPU时间,CPU执行时间=CPU时钟周期数*CPU时钟周期。
1.6. CPI
表示每条指令周期数,即执行一条指令所需的平均时钟周期数。CPI = 执行某段程序所需的CPU时钟周期数/程序所包含的指令条数。
2. 性能相关
2.1. 为什么不能用运行时间来衡量一个程序的性能呢?
记录程序运行结束的时间减去程序开始的时间,叫做Wall clock time或者Elapsed Time,直接拿这种时间来评判一个程序的性能是不妥的。因为在计算机中可能同时运行着多个程序,CPU实际上在不停的切换,而上述计算的时间会把CPU处理其他进程的时间算进去。所以最准确的方式是采用CPU执行时间(CPU执行时间=CPU时钟周期数\*CPU时钟周期)。
2.2. 如何提升一个程序的性能呢?
根据 CPU执行时间=CPU时钟周期数*CPU时钟周期这条公式,由于CPU时钟周期数 = 指令数*CPI。最终CPU执行时间=指令数*CPI*CPU时钟周期,那么想要提升性能可以从三方面角度考虑:
- 从CPU时钟周期下手,这取决于计算机硬件,比如换个好点的CPU;
- 从指令数下手,代表我们的程序有多少指令,然而这方面要看编译器,同样的代码,编译成计算机指令的时候,就有各种不同的表示方式;
- 从CPI下手,现代的CPU通过流水线技术,让一条指令需要的CPU Cycle尽可能的少;
2.3. 主频的提升
1978年Intel发布的8086CPU开始,计算机的主频从5Hz开始不断提升,1980年代中期的80386可以跑到40MHz,1989 年的 486 能够跑到 100MHz,直到 2000 年的奔腾 4 处理器,主频已经到达了 1.4GHz,最终到2019年,intel i9 CPU,主频到了5GHz。比较1978年到2000年,这20年主频翻了300倍,而2000年到2019年,主频只翻了3倍,也就意味着提升性能不能光靠主频了。
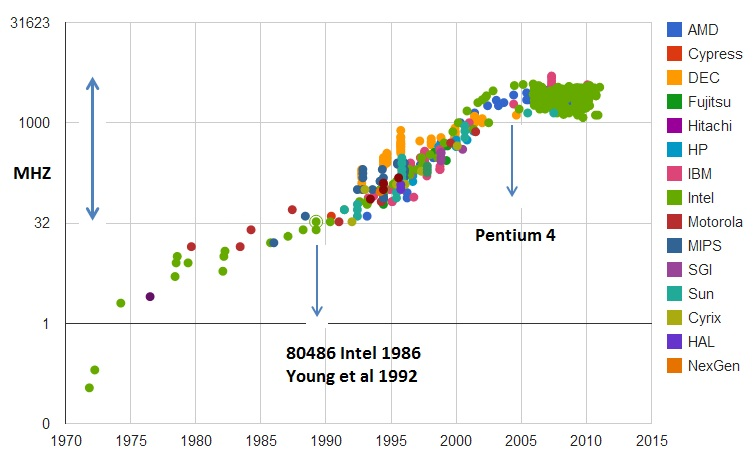
为什么主频的提升受到了限制呢?主要是功耗的问题。CPU,一般都被叫作超大规模集成电路(Very-Large-Scale Integration,VLSI)。这些电路,实际上都是一个个晶体管组合而成的。CPU 在计算,其实就是让晶体管里面的“开关”不断地去“打开”和“关闭”,来组合完成各种运算和功能。想要计算得快,
- 一方面,我们要在 CPU 里,同样的面积里面,多放一些晶体管,也就是增加密度,比如我们可以把晶体管制作的小一点,也就是提升“制程”,假设把晶体管从28nm缩小到7nm,那么晶体管的数量就可以提升上去,密度也上去了。那么为什么不增加CPU的面积呢?因为增大面积之后,电信号传输的时间会变长,运算速度就慢了;
- 另一方面,我们要让晶体管“打开”和“关闭”得更快一点,也就是提升主频。
而这两者的增加,都会增加功耗,带来耗电和散热的问题,而一旦散热来不及那么就会导致崩溃。所以为了散热会在 CPU 上面抹硅脂、装风扇,乃至用上水冷或者其他更好的散热设备,但是外界设备所能提供的帮助也是有限的。因此在有限的CPU面积里,能够放下的晶体管数量和晶体管的“开关”频率也都是有限的。一个 CPU 的功率,可以用这样一个公式来表示:
功耗 ~= 1/2 ×负载电容×电压的平方×开关频率×晶体管数量
从公式中可以看到功耗是跟电压是成平方关系的,所以当功耗增加之后,CPU散热跟不上的时候,会降电压。这也正是为什么我们从5MHz到5GHz提升了1000倍,但是功耗只增长了40倍。笔记本考虑到续航问题,所以一般采用的都是低电压。
一个 3.8GHz 的奔腾 4 处理器,满载功率是 130 瓦,而 iPhone X 使用 ARM 架构的 CPU,功率则只有 4.5 瓦左右。
2.4. 并行优化,理解阿姆达尔的定律
在过去的20年里,CPU性能的提升已经很大了,通过提升主频比较难去实现性能的提升(很多人预测摩尔定律将会失效),所以推出了多核CPU(Core Duo),通过增加CPU数量来提高性能。这是一种最常见的提升性能的方式,通过并行来提高性能。比如一个程序包含了四段计算程序,最后需要把四段计算的结果加起来,但是假如让一个CPU来运算,那么需要依次执行完四段计算程序,以后最后结果的相加,但是假如让4个CPU来,那么只需要一次加上最后结果合并的时间。但是在运用并行解决的时候需要注意以下几点:
-
需要进行的计算本身可以分解成几个可以并行的任务,各自运行不会影响最后的结果;
-
需要能够分解好问题,并确保几个人的结果能够汇总到一块;
-
在“汇总“这个阶段,是没有办法并行进行的,得按照顺序一步一步来
上述几点也就引出了另一个经验定律,阿姆达尔定律。这个定律可以用以下这个式子来表示:
优化后的执行时间 = 受优化影响的执行时间 / 加速倍数 + 不受影响的执行时间
比如上述提到的,假设4段计算程序总的时间为100ns,最后相加的操作只需要20ns。那么当四段计算程序分到4个CPU上分别进行计算的时候,最终优化之后的时间变成了100/4 +20 = 45ns了。

2.5. 主频和并行之外的解决之道
上面提到的提升主频和并行的方法都会遇到瓶颈,所以通过“堆硬件”的方式已经无法满足对性能的需求了。那么可以考虑以下几个原则性的性能提升方法:
-
加速大概率事件。比如整个深度学习整个计算过程中,99%都是向量或者矩阵运算,于是使用GPU替代了CPU,大幅度提升了深度学习的模型训练过程。
-
通过流水线来提高性能。我们把CPU指令执行的过程进行拆分,细化运行。这也是现代CPU在主频没有办法提升的情况下,性能还能提升的主要原因。
-
通过预测提高性能。通过预先预测下一步要干嘛,而不是等上一步的执行结果。典型的例子就是在一个循环访问数组的时候,凭经验,你会猜到下一步会访问数组的下一项。后面要讲的“分支和冒险”、“局部性原理”这些 CPU 和存储系统设计方法,其实都是在利用我们对于未来的“预测”,提前进行相应的操作,来提升我们的程序性能。
3. 题外话
3.1. SPEC(Standard Performance Evaluation Corporation)
SPEC (标准性能评估)提供了一系列基准(benchmark)测试程序,是测试系统总体性能的Benchmark。由于不同的程序测试出的处理器性能的结果值不同,所以采用一个公用的测试程序是很重要的。这些程序丰富多彩,有编译器、解释器、视频压缩、人工智能国际象棋等等,涵盖了方方面面的应用场景。可以通过数十个不同的计算程序,对 CPU 的性能给出一个最终评分。
All SPEC CPU2017 Results Published by SPEC
3.2. Linux的Time命令
time命令可以帮我们统计出,同样的Wall Clock Time下,程序实际在CPU上花的时间是多少。
$ time seq 1000000 | wc -l
1000000
real 0m0.072s
user 0m0.000s
sys 0m0.035s
real是指real time,也就是Wall Clock Time;user是指user time,在用户态模式下运行指令的时间;
sys是指sys time,也就是在内核态模式下运行的时间。程序实际话费的CPU执行时间(CPU Time),就是user time+sys time。
3.3. 摩尔定律
摩尔定律是指集成电路上可容纳的晶体管数目,约每隔两年便会增加一倍,这是由Intel创始人之一戈登·摩尔提出的。而经常被引用的18个月,是由英特尔首席执行官大卫·豪斯提出来的,是说18个月会将芯片的性能提高一倍(即更多的晶体管使其更快),是一种以倍数增长的观测。现代个人计算机、因特网、智能手机等技术改善和创新都离不开摩尔定律的延续。
本文参考
1.计算机组成原理(第五版).白中英,戴志涛等
2.极客时间专栏.深入浅出计算机组成原理

