1. 栈
1.1. 栈的概念
栈是一种操作受限的线性表,只能在一端插入和删除数据,遵守后进者先出,先进者后出的规则。
相比数组和链表,栈带来的只有限制,使用数组或者链表都能完成栈的操作,为什么还需要栈呢?因为有些场景下的数据集合只涉及在一端插入和删除数据,并且满足后进先出、先进后出的特性时,使用数组和链表的话则暴露了太多的操作接口,操作上确实灵活了许多,但是由于接口多了,会导致不可控,也会比较容易出错,而使用栈这种带限制的数据结构会更加符合场景的需求,同时也遵守了一定的最小权限原则,所以需要栈。同时在这种场景下记得优先选择“栈”这种数据结构。最后需要记住一点,特定的数据结构是对特定的场景的抽象。
1.1.1. 栈的实现和操作
栈的实现也分两种:顺序栈(用数组实现)和链式栈(用链表实现)。无论是哪种栈,都主要包含两个操作,入栈和出栈,入栈是指在栈顶插入一个数据,出栈是从栈顶删除一个数据。
无论是哪种栈,存储数据都需要一个大小为 n 的数组。在入栈和出栈的过程中,只需要一两个临时变量的存储空间,所以空间复杂度是 O(1)。入栈和出栈的时间复杂度都是 O(1)。
实现的时候指针可以指向栈顶元素的后一个位置。
这边存储数据需要一个大小为 n 的数组,并不是说空间复杂度就是 O(n)。因为,这 n 个空间是必须的,无法省掉。所以说空间复杂度的时候,是指除了原本的数据存储空间外,算法运行还需要额外的存储空间。在这里理解为入栈或出栈等操作也是算法,这些算法带来的空间复杂度。
1.2. 应用场景
-
函数调用栈
操作系统会为每个进程分配一个独立的内存空间,这块内存被组织成“栈”这种结构,用来存储函数调用时的局部变量。每进入一个函数,就会依次将函数中的局部变量压入栈中,然后组成一个栈帧;当函数执行完之后,返回时,再依次把局部变量弹出。
int main() { int a = 1; int ret = 0; int res = 0; ret = add(3, 5); res = a + ret; printf("%d", res); reuturn 0; } int add(int x, int y) { int sum = 0; sum = x + y; return sum; }下面这张图是执行到 add() 函数时,函数调用栈的情况
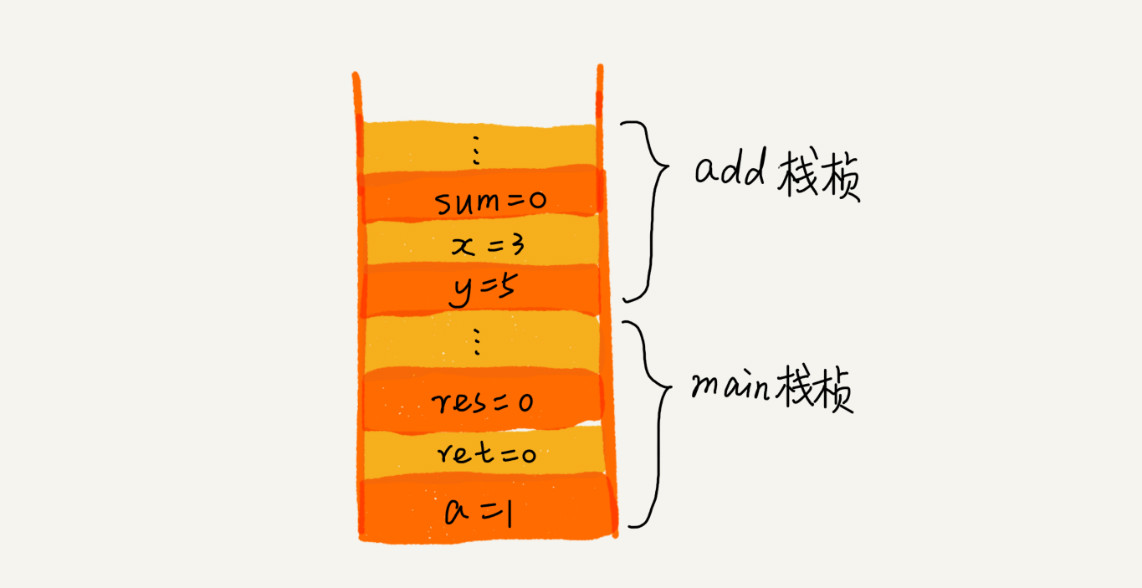
-
表达式求值中的应用
编译器利用两个栈来实现表达式求值。一个栈用来保存操作数,另一个栈用来保存运算符。从左到右遍历表达式,遇到数字就压入操作数栈,遇到运算符就先与运算符栈的栈顶元素进行比较,如果比运算符栈顶元素的优先级高则压入栈;如果比运算符栈顶元素的优先级低或者相同则从运算符中取出栈顶元素,从操作数栈的栈中取 2 个操作数,然后进行运算,之后把结果再压入操作数栈。之后继续拿要压入的运算符和运算符栈进行比较,以此类推。
下面举个例子,比如要对 “3 + 5 * 8 - 6” 这个表达式进行求值,那么整个过程如下所示(结合上述的过程来理解)
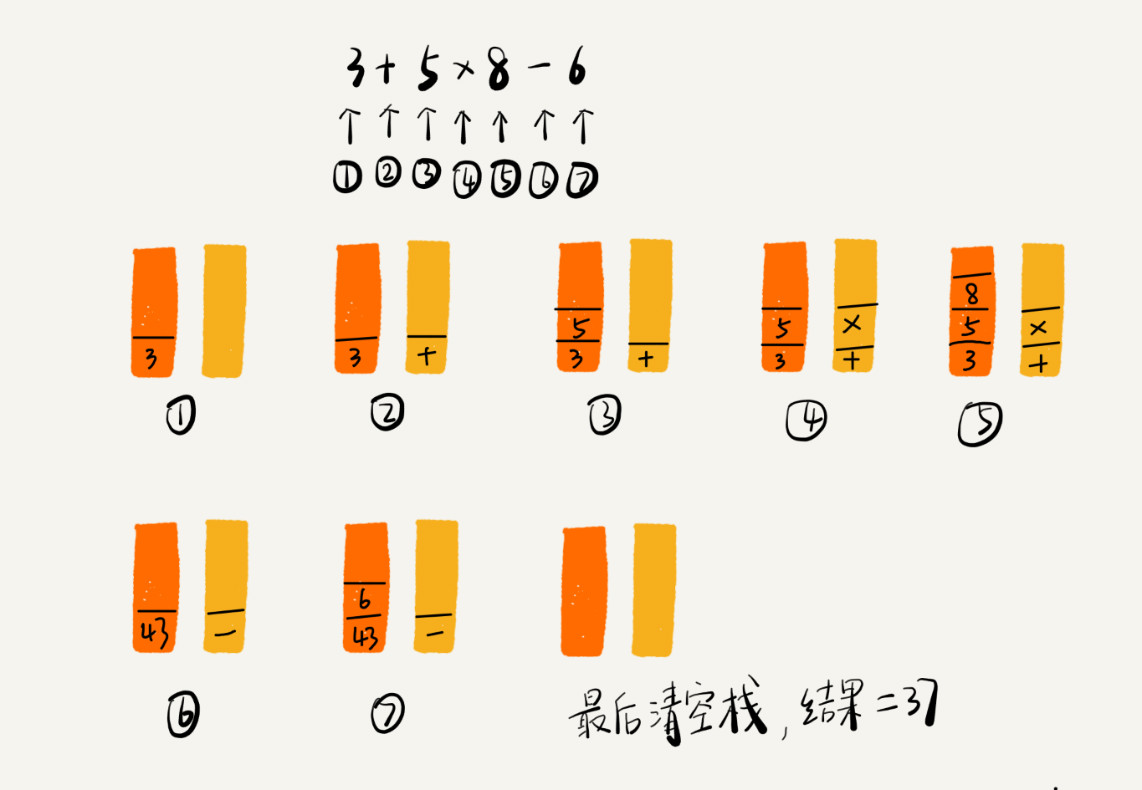
-
栈在括号匹配中的应用
借助栈来检查表达式中的括号是否匹配,比如
{[]()[{}]}是合法的格式,而{[}()]是不合法的格式。主要方法是从左到右依次遍历字符串,当扫描到左括号时,则将其压入栈中;当扫描到右括号时,从栈顶取出一个左括号。如果能够匹配,比如(和)就是匹配的,那么则继续扫描剩下的字符串,如果存在不能匹配的情况或者栈中没有数据的话,则说明是非法合格式。当所有的括号都扫描完成之后,此时栈也为空,那么说明字符串中的括号都匹配,否则栈中还有左括号的话,说明是非法格式。 -
浏览器的前进后退
浏览器中假如依次访问了 a-b-c ,点击浏览器的回退按钮可以查看之前浏览过的页面 a 和 b。当退到 a 页面之后,点击前进按钮还可以访问 b 和 c 页面。但是如果后退到 b 页面,此时进入了新的 d 页面,那么 c 页面再也不能访问到了。这个功能怎么实现呢?
可以借助两个栈来实现,在前进的时候依次把浏览的页面压入 x 栈;当点击回退的时候,再依次从 x 栈中取出,放入到 y 栈。当再次前进的,依次从栈 y 中取出数据,放入 x 栈。当 x 栈中没有内容之后,表示没有页面可以后退了;当 y 栈中没有数据之后,点击前进按钮将不会有页面了。当回退到某个页面之后又重新点击新的页面之后, y 栈会被清空。
-
为什么要用“栈”来保存临时变量呢?
当然,也不一定要用栈来保存临时变量。从调用函数进入被调用函数,主要变化的是作用域。只要保证每进入一个函数,都是一个新的作用域就好。然而实现这个栈是非常方便的。进入被调用函数的时候,分配一段栈空间给这个函数,在函数结束的时候,将栈顶复位,正好回到调用函数的作用内。所以说使用栈,主要是因为函数调用符合后进先出的特性。
-
JVM 内存管理中的堆栈和数据结构中的堆栈有啥区别呢?
个人觉得内存管理中的堆栈更多是对一块内存区域(虚拟内存)的划分,比如这个内存区是堆区,这个内存区是栈区。而数据结构中的堆栈更多是一种抽象的数据存储结构。在 jvm 中 堆区主要用来存储 java 对象(new 出来的),而指向该对象的引用存储在栈区,除此之外栈区还保存方法的形参、局部变量、返回值等。
1.3. 栈的总结
其实栈的最主要思想是先进后出,这个思想隐约在括号匹配中略有体现,因为最左边的括号可作为最开始的括号,而它要匹配正确的括号的话,是在最右边相当于最后。所以这种最先和最后跟栈的思想有点类似。因为可以考虑使用栈。以上是个人理解,所以当有个场景也是这样最先和最后的情况存在的话,可以考虑使用栈看一下。
巨人的肩膀
- 极客时间-《数据结构与算法》-王争老师
2. 队列
2.1. 队列的概念
队列和栈类似都是操作受限的线性表结构,只是队列遵守的是先进先出的,并且只能在队尾进,队头出。
2.1.1. 基本操作
入队(enqueue()):将一个数据放到队列尾部;
出队(dequeue()):从队列头部取一个数据;
2.1.2. 各种队列实现
相比栈来说,队列需要两个指针,一个是 head 指针指向队头,另一个是 tail 指针,指向队尾。另外队列使用数组实现的话叫做顺序队列,用链表实现的话叫做链式队列。下面介绍几种常见队列:
-
顺序队列
在使用数组实现的队列的时候,可能会存在队列假满的情况,也就说尾指针指到了数组最后,但是实际数组还是有空间存的。针对这种问题来说,一种方式是数组搬运:在入队的时候,发现队尾指到了数组尾部,那么则判断 head 指针是否是在数组第一个位置,如果不是,则整体往前移动,如果是那说明整个空间都是满的。
-
链式队列
基于链表的实现,也需要两个指针,一个 head 指针,一个 tail 指针,分别指向链表头和链表尾部。
-
循环队列
用数组来实现队列的时候,在 tail==n 时,会有一定的数据搬移。**为了避免数据搬移,可以将数组整成逻辑上的环状。**当 tail 到达数组之后,再入队的话,则将数据放到数组开始的地方。
循环队列中最关键的是确定好队空和队满的判断条件,在队列中少放一个数据的前提下,也就是 tail 指向的位置不存放数据的话,那么队空的判断条件还是 head == tail,而队满的条件变成了 (tail + 1)% n == head。
2.2. 应用场景
-
阻塞队列
阻塞队列其实就是在队列基础上增加阻塞操作。比如在队列为空时,从队头取数据会被阻塞,直到队列中有了数据才能返回;如果队列已满,那么插入数据的操作会被阻塞,直到队列中有空闲位置后再插入数据,然后返回(Hint:其实这个定义的就是一个“消费者-生产者”模式)。
-
并发队列
在前面阻塞队列的基础之上。假如有多个线程同时操作队列,比如多个消费者从队列中取数据,多个生产者将数据放入队列中。此时,如果多个线程能很好地互斥访问队列,也就是线程安全的话,那么则是并发队列。
实现并发队列最简单的方式是在入队、出队等操作上加锁。另一种方法是在基于数组的循环队列中使用CAS原子操作,可以实现高效的并发队列。CAS的使用也算是无锁的方式,在入队前,获取 tail 位置,入队时比较 tail 是否发生改变,如果否则允许入队。反之,入队失败;出队类似。
-
应用在大部分有限资源池中,用于排队请求,当资源池里没有空闲资源时,接下来的请求都可以放入“队列”这种数据结构中。这种情况下,队列的大小是很讲究的,如果队列太大,那么会导致请求太多,后面入队的请求响应不及时;队列太小,导致无法充分利用资源。
-
消息队列
-
Linux 内核源码的 kfifo 的实现
-
FIFO 调度算法
2.3. 队列的总结
数据结构是对应用场景的抽象,在学栈、队列的时候体会到的。比如一个应用场景中事情是后面才开始的,但是先运行结束的,那么这个就有点先进后出的味道。
巨人的肩膀
- 极客时间-《数据结构与算法》-王争老师

