0. 前言
大家好,我是多选参数的程序锅,一个正在 neng 操作系统、学数据结构和算法以及 Java 的硬核菜鸡。本篇主要介绍了哈希算法相关的内容,包括什么是哈希算法、哈希算法的设计要点以及哈希算法的应用场景。
程序锅整了一个关于算法的 github 仓库:https://github.com/DawnGuoDev/algorithm,该仓库除包含基础的数据结构和算法实现之外,还会有数据结构和算法的知识内容整理、LeetCode 刷题记录(多种解法、Java 实现) 、一些优质书籍整理。
1. 概念
哈希算法在日常生活中经常被听到,比如 MD5、SHA 等。那么什么是哈希算法呢?哈希算法是指将任意长度的二进制值串映射为固定长度的二进制值串。原始数据经过映射之后得到的二进制值串就是哈希值。
2. 设计要点
要想要设计一个哈希算法,需要满足以下几点要求:
- 从哈希值不能反向推导出原始数据(哈希算法更多算是一种单向加密算法)。
- 对输入数据敏感,输入数据只要改变 1 bit,那么最终得到的哈希值也要不同。
- 冲突的概率要小,即对于不同的原始数据,哈希值相同的概率非常小。
- 哈希算法的执行效率要高,针对较长的文本,也能快速计算出哈希值。
下面以 MD5 算法为例来阐述上述这些点,比如我们要对“多选参数”和“程序锅”这两个文本计算 MD5 哈希值,结果如下所示,这两个文本将会得到截然不同的 MD5 哈希值。但是,每个 MD5 哈希值的长度是一样的。并且,对应这样的 MD5 哈希值,我们很难将其解析出原来的内容(晚上虽然有说 MD5 已经可以破解了)。
MD5("多选参数") = 51229F146DCE22156D4A6B3ED657CEB8
MD5("程序锅") = 4382F9DFC3CA7D7BE230A257CEB121B2
当我们使用两个及其相近的文本,比如“多选参数66”和“多选参数666”,这两个文本计算得到的 MD5 哈希值如下所示。这两个文本就一个数字之差,但是哈希值却是截然不同的。
MD5("多选参数66") = 3FFDE0E6B94323D4AE037A07D215FE79
MD5("多选参数666") = 6D8BCF994BA29EDA8BEDD443635A52BE
之后,哈希算法冲突的概率要小。比如 MD5 中,哈希值是 128 位二进制值串,能表示的数据个数是 2128,存在哈希值相同的概率是非常小的。并且哈希值的二进制值串位数越多,冲突的概率会越低。另外需要额外提的一点是不管什么哈希算法,我们能做到的是尽量减少碰撞冲突的概率,理论上是没办法做到完全不冲突的。这是基于组合数学中一个非常基础的理论,鸽巢原理(或者抽屉原理)。这个原理就是说有 10 个鸽巢,如果有 11 个鸽子的话,肯定有一个鸽巢的鸽子数量多于 1 个。基于这个原理,哈希算法理论上是无法做到零冲突的。就算 MD5 能表示的数据个数是 2128 个,它非常大但也是有限的。比如,现在有 2^128+1 个数据,那么肯定存在哈希值相同的情况。
最后,哈希算法要处理的文本可能是各种各样。对于非常长的文本,如果哈希算法的计算需要很长时间,那么是很难应用到实际的软件开发中去的。因此,哈希算法对于任何内容计算的时间都需要尽可能小。比如,MD5 计算哈希值就很快。
3. 应用场景
哈希算法的应用场景非常多,这边列举几个我觉得比较重要的。
3.1. 哈希函数
哈希函数中可以使用哈希算法对 key 值进行散列从而得到不同的哈希值(这个是哈希算法直接得到的固定的一个哈希值),之后再对前面得到的哈希值取模从而确定要存储的散列表位置。哈希算法应用于哈希函数时,需要注意的是散列的平均性和哈希算法的执行效率。
3.2. 唯一标识
哈希算法针对不同的二进制内容生成的二进串是不一样,一般来讲都是一对一的情况。但是,严格意义上来讲是存在冲突的,即两个不一样的二进制内容对应的哈希值却是一样。然而,这种情况是很少见的,因此不严格上来讲是对。
由于上述这点特性,哈希算法可以对数据量比较大的内容做信息摘要,从而可以通过一个很短的二进制编码来表示这个数据的唯一性。
3.3. 数据校验
利用与上述一样的哈希算法特性,不同二进制内容生成的哈希值是不一样。因此,当哈希值是一样时,表示原二进制内容是一样的。
因此,可以用于校验数据的完整性和正确性。
3.4. 安全加密
哈希算法可以将二进制串转换为一串毫无规律的二进制值串,同时是很难通过哈希值反推出原二进制值串的内容。因此,可以用于单向加密。那么单向加密可以怎么用呢?
比如在网站中,为了避免明文带来的不安全,我们可以使用哈希算法对用户密码进行单向加密。当用户登录时输入密码之后,使用哈希算法对这个密码进行哈希计算。之后,再跟数据库中存储的哈希值进行比较,如果一样,则可认为用户输入的密码是正确。
针对,用户输入的密码过于简单来说,比如 0000、123456 这种。黑客可能会通过遍历的方式来进行破解。为此,我们可以引入盐(salt),将其跟用户的密码组合在一起,从而增加密码的复杂度。在使用哈希算法进行散列时,使用的也是组合之后的内容,从而增加被破解的难度。
假如担心被破解,我们可以增加哈希算法的复杂度。但是响应的计算机时间也是越长的。在使用时,要权衡安全性和计算时间来选择哈希算法。
常用的用于单向加密的哈希算法是 MD5(Message-Digest Algorithm,信息摘要算法)和 SHA(Secure Hash Algorithm,安全散列算法)。
当然真正算得上是加密算法的有:DES、AES 等。
3.5. 负载均衡(分布式)
在实现一个会话粘滞(session sticky)的负载均衡时,会用到哈希算法。会话粘滞的意思是,对于同一个客户端,一次会话中的所有请求都会被路由到同一个服务器上。此时,我们可以使用哈希算法,对客户端 IP 地址或者会话 ID 计算哈希值,将取得的哈希值与服务器列表的大小进行取模运算,最终得到的值就是应该被路由到的服务器编号。这样,来自同一个 IP 的所有请求都会被路由到同一台服务器。
维护一张客户端 IP 或者会话 ID 与服务器编号的映射关系表是可以的。每次请求,先在映射表中查找应该路由到的服务器编号,然后再请求编号对应的服务器。但是也有几个弊端,比如客户端很多,映射表可能会很大,比较浪费内存空间;客户端下线、上线,服务器扩容、缩容都会导致映射失效,维护映射表的成本就会很大。
3.6. 数据分片(分布式)
数据分片可以想到 MapReduce 的基本设计思想。当处理的数据量特别大时,一台机器可能无法处理这么多的数据量,因此可以将待处理的数据分发到多台机器上并行处理。提到处理速度。此时,我们可以使用哈希算法对数据进行哈希计算获得哈希值,之后再对哈希值进行取模,根据取模的结果,将数据分发到相应的机器上。这样,相同的数据肯定都在同一台机器上了。此时,如果对“搜索关键字”或者文档进行计算的话,我们不用再担心计数不完整或者错误。并且,每台机器处理完之后,只要将结果简单的合并即可。
3.7. 分布式存储(分布式)
为了提高数据的读取、写入的速度,一般采用缓存的方式。当遇到海量的数据时,我们可以结合分布式的方式来缓存数据。此时,访问的数据是在哪个机器上呢?我们同样可以采用哈希算法并取模的方式。最终得到的值就是应该缓存该数据的机器。
但是随着时间的增长,存储的数据会越老越多。原来的机器数量可能会无法承受与日俱增的数据,我们就需要扩容。但是,扩容不是简单地加个机器而已,更意味着缓存数据将会失效。比如,原先是 10 台机器的,我们是通过与 10 取模来计算的。那么哈希值为 13 这个数据,应该会被存储在编号为 3 的机器上。但是,假如新增了 1 台机器之后,我们是通过与 11 取模来计算的。那么哈希值为 13 这个数据可能会被分配到 2 号这台机器上了。此时,几乎所有的数据都要重新计算。同时,几乎所有的数据都会穿透缓存,直接去请求数据库了。这样可能就会发生雪崩效应,压垮数据库。
为此,引入了另一种方法---一致性哈希算法。一致性哈希算法可以使得在新加入一个机器后,并不需要做大量的数据搬移。一致性哈希算法使用时,同样也是采用了哈希算法和取模结合的方式。首先需要对机器套用哈希算法,在取得哈希值之后进行取模。之后再对数据套用哈希算法,在取得哈希值之后进行取模。比如三台机器取模之后的值分别为 3、6、9。数据取模之后的值刚好为 3、6、9,那么则将其放入对应的机器中。但是,假如取模之后的值为 2、5、8 呢?我们应该将这些 2、5、8 对应的数据存储到其顺时针方向上的第一台机器。比如 2 这个数据存储到顺时针方向上的第一台机器是 3;5 则是 5 号机器;8 则是 9 号机器。如下图所示:
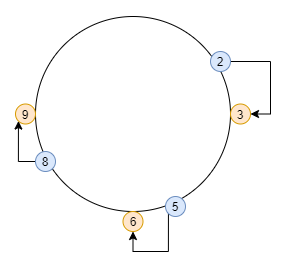
这边讲的不太全面,想要了解一致性哈希算法的话可看这篇博客:http://www.zsythink.net/archives/1182
3.8. 其他
Git commit id
3.9. 总结
唯一标识、数据校验、安全加密更多是简单地使用了哈希算法的特性,比如不同的内容对应的哈希值是不一样的、相同的内容对应的哈希值是一样的、不能通过哈希值反向求得原内容。
哈希函数、负载均衡、数据分片和分布式存储的基本方法都是类似的,都是先通过哈希算法获得哈希值,然后再进行取模运算。相当于在取得的哈希值之上再做进一步运算。
巨人的肩膀
- 极客时间,《数据结构与算法之美》,王争

