Kube-Scheduler 的作用是将 Pod 调度到最优的节点上(给 Pod 选择一个最合适的 Node),从而更加合理、更加充分的利用集群的资源
基本调度流程
整个调度的基本流程如下,
-
Pod 被提交到 API Server,存储到 Etcd 中。
-
调度器会 List&Watch Pod,将
PodSpec.NodeName为空的 Pod 添加到 PriorityQueue 中。 -
调度过程:之后会不断循环地从 PriorityQueue 中取出 Pod,按照以下流程给 Pod 选择一个最合适的 Node。
- 过滤(Predicates)阶段:遍历全部节点,过滤掉不满足条件的节点。比如 Pod 设置了资源的 request,那么可用资源比 Pod 需要的资源少的主机就会被过滤掉,又或者容忍策略不满足。这一阶段输出的所有满足要求的节点将作为第二阶段的输入。如果所有的节点都不满足条件,那么 Pod 将会一直处于 Pending 状态,直到有节点满足条件,在这期间调度器会不断的重试。
- 打分(Priorities)阶段:对满足条件的节点进行打分。
- 选择节点:选择打分最高的节点,如果存在相同分数的节点,则随机从其中选择一个节点。
-
绑定(binding)阶段:最后是向 API Server 发起请求,将选出来的节点和 Pod 进行 binding,其实是创建 bind 子资源。API Server 收到请求后会给 Pod 设置 nodeName(涉及写 etcd)。写完之后,API Server 才会返回请求的结果。这个是完整的 binding 阶段。
-
完成之后,调度器会产生相应的 event 资源。
-
Kubelet List&Watch 到 Pod 的 nodeName 为自己的节点名字,在节点上拉起 Pod。
目前调度器均采用插件的方式实现了上述整个调度框架。调度器中的一系列算法(比如过滤算法、打分算法)均由各种插件实现,比如 Predicates、Priorities 阶段分别使用不同的插件来完成。
需要注意:
-
调度过程,也就是上述的“Predicates+Priorities+选择节点”过程是单并发同步运行的,同一时间只有一个 Pod 在进行调度,并没有采用异步多并发的方式。换言之,一个 Pod 调度完之后,下一个 Pod 才能被调度。
主要是考虑如果采用多并发的方式,会无法保证安全,选出的最优节点在并发下可能会被多个 Pod 绑定。比如,一个 goroutine 中被调度的 Pod 刚选好 A 节点,节点的资源情况还没更新,另一个 goroutine 中的 Pod 按照未更新的节点资源情况也选了 A 节点。
-
绑定过程是多并发运行的,同一时间点可并发为多个 Pod 执行绑定。
调度框架
调度框架针对每个阶段都定义了相应的扩展点,用户可以实现扩展点定义的接口来定义自己的调度逻辑(插件),并将插件注册到扩展点上。在调度框架执行调度的时候,遇到相应的扩展点时,将调用用户注册的插件。
如下所示,是整个调度框架中的调度上下文及其中的扩展点,每个扩展点可以注册多个插件。
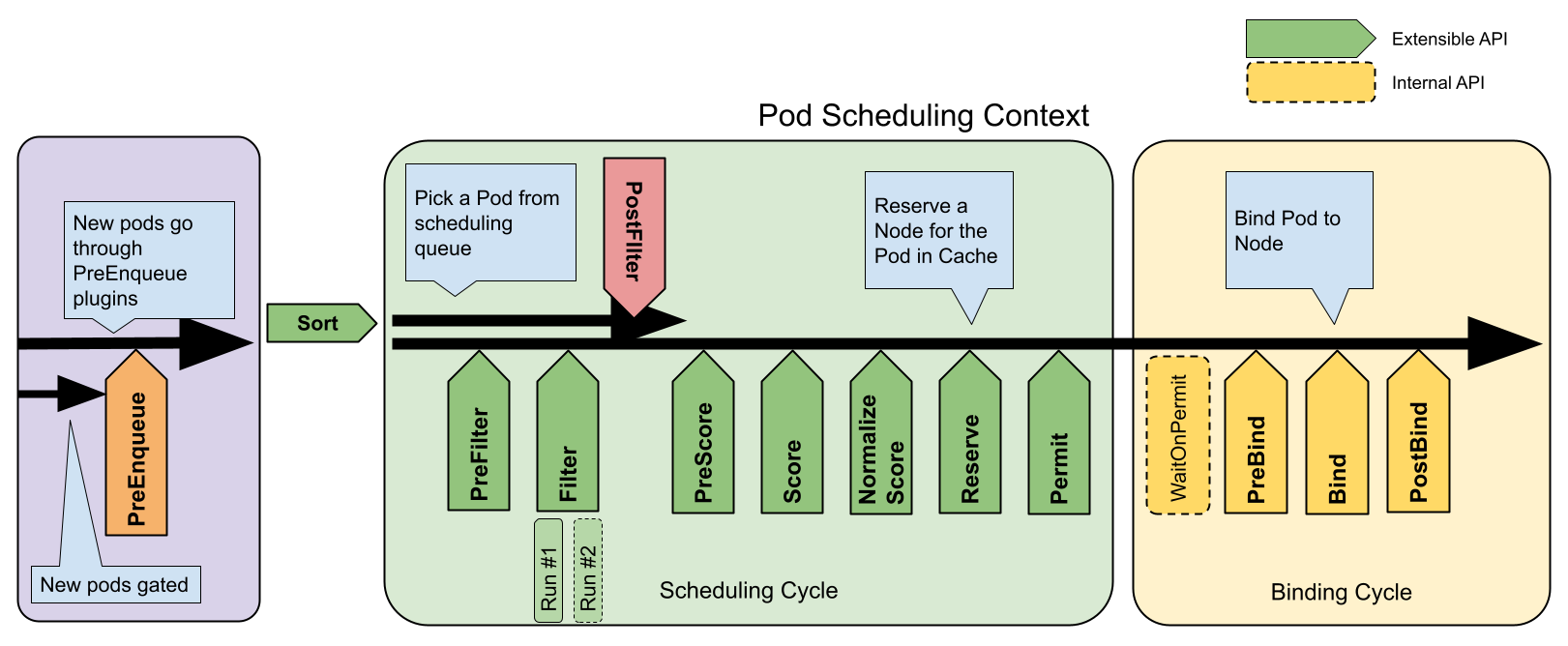
可以看到,上述调度的基本流程其实就是扩展点被依次执行的过程,
- 添加 Pod 到 PriorityQueue 主要对应 Sort 扩展点。
- 过滤阶段主要对应 PreFilter、Filter、PostFilter 扩展点。
- 打分阶段主要对应 PreScore、Score、Normalize Score 扩展点。
- 绑定阶段主要对应 PreBind、Bind、PostBind 扩展点。
接下去简单介绍下几个主要的扩展点,更加详细的扩展点介绍可参考 官方文档-调度框架。
-
Sort:用于对待调度的 Pod 进行优先级排列。
- PriorityQueue 本质上相当于一个堆,堆顶是最先要被调度的 Pod。因此 Sort 扩展点处的插件其实只需要实现一个方法
Less(*QueuedPodInfo, *QueuedPodInfo)即可,该方法用于比较两个 Pod 谁更优先获得调度。 - Sort 同一时间点只能有一个插件生效。
- PriorityQueue 本质上相当于一个堆,堆顶是最先要被调度的 Pod。因此 Sort 扩展点处的插件其实只需要实现一个方法
-
PreFilter:用于对 Pod 的信息进行预处理。如果 PreFilter 返回了 error,则调度过程终止。具体使用,
- 比如通过额外的方式获取到所有带 GPU 的节点,之后的 Filter 阶段只需要在这些节点中处理即可,无需遍历。
- 比如检查 Pod 请求的资源是否超过了任何节点的能力。
-
Filter:用于排除不能运行该 Pod 的节点。
- 对于每一个节点,调度器将按顺序执行 Filter 插件,如果任何一个 Filter 插件将节点标记为不可选,则剩下的 Filter 插件将不会被执行。
- 调度器可以采用多并发的方式对多个节点同时执行 Filter 插件。
-
PostFilter:如果所有节点都不符合条件,导致 Pod 无法调度,那么就会触发 PostFilter 扩展点。具体使用,
- 比如 PostFilter 扩展点中的插件可以通过抢占的方式让该 Pod 调度成功。
- 比如仅仅打印更详细的信息,解释为什么 Pod 不能被调度。
-
PreScore:为 Score 扩展点的数据做一些预处理操作。具体使用,
- 比如 Score 扩展点中的多个插件都依赖相同的基础数据,但是插件使用的计算方式不一样。那么可以在 PreScore 阶段中预处理和缓存这些基础数据,避免 Score 扩展点中每个插件都需要进行相同的数据计算。
-
Score:用于给所有可选节点评分,调度器将针对每一个节点调用 Score 插件对其进行评分。
-
Normalize Score:将各个 Score 插件输出的分数进行归一化处理,因为不同的 Score 插件可能会根据不同的标准和范围给出评分,这些分数需要被转换为同一范围内。具体使用,
- 比如把每个 Score 插件中对具体某个节点的评分结果和该插件的权重合并起来,作为最终评分结果。
- 比如评分插件可能会产生聚集在某一区域的分数,此时可以调整这些分数的分布,使其更加均匀。
-
Bind:确保 Pod 能够与其分配的节点正式绑定,也就是将 Pod 和节点的绑定请求发送给 API Server,更新 Pod 对象的 nodeName 字段。如果某个 bind 插件处理了该 Pod 与节点的绑定,剩下的 bind 插件将被忽略。Bind 插件除了绑定的作用之外,还可以的作用是,
- 比如在 Pod 被绑定前执行一些自定义的逻辑,对 Pod 进行一些额外的设置。
调度器扩展方式
针对 kube-scheduler 中调度逻辑的扩展有两种方式:
- 调度框架插件方式:这种方式是指实现一个调度框架的插件,该插件需要实现对应扩展点所要求的接口。然后再将实现的插件注册到调度器中即可。
- 外部调用方式:大部分扩展点,都支持调用外部服务。这种方式我们需要实现一个 http 服务,然后再通过配置文件指定该服务的地址等信息即可。
调度框架插件方式
调度框架的插件实现例子,可以参考 Github-Scheduler-Plugin 。下面简单介绍一下,
-
首先该插件需要实现相应扩展点的要求的接口,比如想要在 PreFilter 扩展点使用该插件,那么就使用需要实现 PreFilter 方法。
package plugins const Name = "sample-plugin" type Sample struct { } func (s *Sample) Name() string { return Name } func (s *Sample) PreFilter(ctx context.Context, cycleState *framework.CycleState, pod *v1.Pod) (*framework.PreFilterResult, *framework.Status) { klog.V(3).Infof("prefilter pod: %v", pod.Name) return nil, nil } func New(fpArgs runtime.Object, fh framework.Handle) (framework.Plugin, error) { return &Sample{}, nil } -
之后将该插件注册到调度器中。在 kube-scheduler 的 main 函数中,NewSchedulerCommand 方法的默认传参为空。在这里使用 WithPlugin 函数用来注册插件,此时返回一个 Option 实例,然后将它作为 NewSchedulerCommand 方法的参数传递到调度器中。如下所示,
package main import ( "k8s.io/component-base/cli" "k8s.io/kubernetes/cmd/kube-scheduler/app" "math/rand" "os" "sample-scheduler/pkg/scheduler/framework/plugins" "time" ) func main() { command := app.NewSchedulerCommand( app.WithPlugin(plugins.Name, plugins.New)) code := cli.Run(command) os.Exit(code) } -
最后修改调度器配置文件,enable 实现的插件。如下所示,就将 sample-plugin 插件添加到了 PreFilter 扩展点上。
apiVersion: kubescheduler.config.k8s.io/v1 kind: KubeSchedulerConfiguration profiles: - plugins: preFilter: enabled: - name: "sample-plugin"
外部调用方式
外部调用方式,性能较差,这里就不阐述了。
调度器配置
调度器配置,也就是对调度器中插件的启用或者禁用,可以使用 KubeSchedulerConfiguration API 来进行配置。下面举几个例子,详细可参考 官方文档-调度器配置。
KubeSchedulerConfiguration v1beta3 在 v1.26 中已被弃用, 并将在 v1.29 中被移除。
单配置使用
对每个扩展点,你可以禁用默认插件或者是启用自己的插件,插件被调用的顺序如下:
-
默认插件始终被最先调用,然后再按照配置文件中的
enabled顺序逐个调用插件。- 如果某个扩展点没有配置对应的插件,调度框架将使用默认插件。
- 如果某个扩展点配置且激活了插件,则调度框架将先调用默认插件,再调用配置中的插件。
-
要改变默认插件中的插件被调用时的顺序,可以先禁用掉所有默认插件,然后在
enabled列表中按顺序依次激活默认插件。
举几个例子,
-
这里我们禁用掉了 PodTopologySpread 这个默认插件,然后启动了 MyCustomPluginA 和 MyCustomPluginB 两个插件(实现了 Score 扩展点要求的方法),并赋予了相应的权重。那么,在 Score 阶段,插件被调度的顺序相当于,先调用默认插件(除 PodTopologySpread 外),然后再调用 MyCustomPluginA 和 MyCustomPluginB 两个插件。
apiVersion: kubescheduler.config.k8s.io/v1 kind: KubeSchedulerConfiguration profiles: - plugins: score: disabled: - name: PodTopologySpread enabled: - name: MyCustomPluginA weight: 2 - name: MyCustomPluginB weight: 1 -
假设 foo 是默认插件,它实现了 reserve 扩展点要求的方法。bar 是我们自己的实现插件,要想在 foo 插件被调用之前调用 bar 插件。那么,可以先禁用掉 foo 插件,然后 enable 中再依次启用 bar 插件和 foo 插件。
apiVersion: kubescheduler.config.k8s.io/v1 kind: KubeSchedulerConfiguration profiles: - plugins: reserve: enabled: - name: bar - name: foo disabled: - name: foo
多配置使用
可以给同一个 kube-scheduler 实例使用多个配置文件,每个配置文件都会有一个关联的调度器名称,可以配置一组不同的插件。其实相当于给不同的插件配置链分别定义了一个名称,当 Pod.spec.schedulerName 中指定了相应名称的时候,就会使用该名称对应的插件配置。
比如,如果使用下面的配置文件,则 kube-scheduler 将使用两个配置文件:一个表示使用默认插件,另一个禁用所有打分插件。
- 如果 Pod.spec.schedulerName 指定为 no-scoring-scheduler,则采用 no-scoring-scheduler 这个配置文件对应的插件配置情况来运行。
- 如果 Pod.spec.schedulerName 没有指定,kube-apiserver 将会把调度器名设置为 default-scheduler。也就是采用 default-scheduler 这个配置文件对应的插件配置情况来运行。
apiVersion: kubescheduler.config.k8s.io/v1
kind: KubeSchedulerConfiguration
profiles:
- schedulerName: default-scheduler
- schedulerName: no-scoring-scheduler
plugins:
preScore:
disabled:
- name: '*'
score:
disabled:
- name: '*'
如何生效
那么如何让上述的配置文件生效呢?
-
首先创建类似上述的配置文件。
-
之后在调度器启动的时候使用
--config参数指定配置文件的位置。比如,kube-scheduler --config /path/to/your/scheduler/config.yaml
源码解读
关于源码的解读可参考 源码分析 kubernetes scheduler 核心调度器的实现原理。当然最直接的做法还是直接阅读源码,从 cmd/kube-scheduler/scheduler.go 开始阅读。简单介绍下它的核心代码,
调度核心方法-scheduleOne
Run()方法是调度启动的入口,在这里它会启动一个 goroutine,在 goroutine 中会循环调用核心调度方法scheduleOne()。scheduleOne()方法从优先级队列中获取 Pod 对象,然后调用schedulingCycle()方法为 Pod 选择最优的 node 节点。schedulingCycle()方法会调用SchedulePod()方法,而这个方法其实指向的是schedulePod()方法。在这个方法中,findNodesThatFitPod()方法是 Predicates 阶段,对 Node 节点进行过滤。prioritizeNodes()方法是 Priorities 阶段,对 Node 节点进行打分。- 最后调用
selectHost()方法选择最合适的 Node 节点.
- 如果找到了合适的 Node 节点,则单独启动一个 goroutine,在 goroutine 中调用
bindingCycle()方法来发起 Pod 和 Node 的绑定。
// pkg/scheduler/scheduler.go
func (sched *Scheduler) Run(ctx context.Context) {
logger := klog.FromContext(ctx)
sched.SchedulingQueue.Run(logger)
go wait.UntilWithContext(ctx, sched.scheduleOne, 0)
<-ctx.Done()
sched.SchedulingQueue.Close()
}
func (sched *Scheduler) scheduleOne(ctx context.Context) {
podInfo, err := sched.NextPod()
...
scheduleResult, assumedPodInfo, status := sched.schedulingCycle(schedulingCycleCtx, state, fwk, podInfo, start, podsToActivate)
// bind the pod to its host asynchronously (we can do this b/c of the assumption step above).
go func() {
...
status := sched.bindingCycle(bindingCycleCtx, state, fwk, scheduleResult, assumedPodInfo, start, podsToActivate)
}()
}
func (sched *Scheduler) schedulingCycle(
ctx context.Context,
state *framework.CycleState,
fwk framework.Framework,
podInfo *framework.QueuedPodInfo,
start time.Time,
podsToActivate *framework.PodsToActivate,
) (ScheduleResult, *framework.QueuedPodInfo, *framework.Status) {
pod := podInfo.Pod
scheduleResult, err := sched.SchedulePod(ctx, fwk, state, pod)
...
return scheduleResult, assumedPodInfo, nil
}
func (sched *Scheduler) schedulePod(ctx context.Context, fwk framework.Framework, state *framework.CycleState, pod *v1.Pod) (result ScheduleResult, err error) {
feasibleNodes, diagnosis, err := sched.findNodesThatFitPod(ctx, fwk, state, pod)
...
priorityList, err := prioritizeNodes(ctx, sched.Extenders, fwk, state, pod, feasibleNodes)
host, _, err := selectHost(priorityList, numberOfHighestScoredNodesToReport)
return ScheduleResult{
SuggestedHost: host,
EvaluatedNodes: len(feasibleNodes) + len(diagnosis.NodeToStatusMap),
FeasibleNodes: len(feasibleNodes),
}, err
}
findNodesThatFitPod 方法
上述提到该方法是 Predicates 阶段,用于对 Node 节点进行过滤。该方法中,
-
首先调用
RunPreFilterPlugins()方法进行 PreFilter。 -
再调用
findNodesThatPassFilters()方法进行 Filter。而在 Filter 的过程中,有几个优化点值得关注,-
一是
sched.numFeasibleNodesToFind()方法。在大集群下 Node 节点会很多,为了避免遍历全量的 Node,这里通过该方法来减少最终要遍历的 Node 数量,也就说只要满足条件的 Node 数量达到 numNodesToFind 之后,就不会再继续遍历剩下的 Node 了。它的计算方式是,-
当集群节点数小于 100 时,则为集群实际节点数,表示集群中的所有节点都参与过滤。
-
当集群节点数大于 100 时,则使用下面的公式计算最终所需节点数。假设当前集群有 500 个 Node 节点,那么最终只需要满足条件的 Node 达到 500 * (50 - 500/125) / 100 = 230 个就会停止遍历。
numAllNodes * (50 - numAllNodes/125) / 100
-
-
二是
fwk.Parallelizer().Until(ctx, numAllNodes, checkNode, metrics.Filter)。这个方法的作用是加快执行效率,它默认启用 16 个 goroutine 并发来对 Node 进行过滤。每个 goroutine 都会对一个 Node 循环遍历插件的 Filter 方法来判断是否要过滤掉。
-
-
最后调用
findNodesThatPassExtenders()方法,这个方法的作用就是调用外部扩展点,也就是上述提到的外部调用方式(调用外部的 HTTP 服务)。
func (sched *Scheduler) findNodesThatFitPod(ctx context.Context, fwk framework.Framework, state *framework.CycleState, pod *v1.Pod) ([]*v1.Node, framework.Diagnosis, error) {
...
preRes, s := fwk.RunPreFilterPlugins(ctx, state, pod)
...
feasibleNodes, err := sched.findNodesThatPassFilters(ctx, fwk, state, pod, diagnosis, nodes)
...
feasibleNodes, err = findNodesThatPassExtenders(ctx, sched.Extenders, pod, feasibleNodes, diagnosis.NodeToStatusMap)
return feasibleNodes, diagnosis, nil
}
func (sched *Scheduler) findNodesThatPassFilters(
ctx context.Context,
fwk framework.Framework,
state *framework.CycleState,
pod *v1.Pod,
diagnosis framework.Diagnosis,
nodes []*framework.NodeInfo) ([]*v1.Node, error) {
numAllNodes := len(nodes)
numNodesToFind := sched.numFeasibleNodesToFind(fwk.PercentageOfNodesToScore(), int32(numAllNodes))
checkNode := func(i int) {
nodeInfo := nodes[(sched.nextStartNodeIndex+i)%numAllNodes]
status := fwk.RunFilterPluginsWithNominatedPods(ctx, state, pod, nodeInfo)
if status.IsSuccess() {
length := atomic.AddInt32(&feasibleNodesLen, 1)
if length > numNodesToFind {
cancel()
atomic.AddInt32(&feasibleNodesLen, -1)
} else {
feasibleNodes[length-1] = nodeInfo.Node()
}
} else {
statusesLock.Lock()
diagnosis.NodeToStatusMap[nodeInfo.Node().Name] = status
diagnosis.UnschedulablePlugins.Insert(status.FailedPlugin())
statusesLock.Unlock()
}
}
...
fwk.Parallelizer().Until(ctx, numAllNodes, checkNode, metrics.Filter)
return feasibleNodes, nil
}
相关链接
-
源码分析 kubernetes scheduler 核心调度器的实现原理:https://github.com/rfyiamcool/notes/blob/main/kubernetes_scheduler_code.md
-
Kubernetes 调度器实现原理:https://mp.weixin.qq.com/s/pRnXeRGw-5YpEDAjk5HF6g
-
官方文档-调度框架:https://kubernetes.io/zh-cn/docs/concepts/scheduling-eviction/scheduling-framework/
-
官方文档-调度器配置:https://kubernetes.io/zh-cn/docs/reference/scheduling/config/#multiple-profiles
-
Github-Scheduler-Plugin:https://github.com/kubernetes-sigs/scheduler-plugins

