Calico 有两种网络通信方式:BGP 和 IPIP。
BGP(Underlay)
BGP 前置知识
BGP 的全称是 Border Gateway Protocol,即:边界网关协议。它是一个 Linux 内核原生就支持的、专门用在大规模数据中心里维护不同的“自治系统”之间路由信息的、无中心的路由协议。

如图所示,有两个自治系统(Autonomous System,简称为 AS):AS 1 和 AS 2。而所谓的一个自治系统,指的是一个组织管辖下的所有 IP 网络和路由器的全体。你可以把它想象成一个小公司里的所有主机和路由器。在正常情况下,自治系统之间不会有任何通信。但是,如果这样两个自治系统里的主机,要通过 IP 地址直接进行通信,我们就需要使用路由器把这两个自治系统连接起来,也就是图中的 Router 1 和 Router 2。这样,
- AS 1 里面的主机 10.10.0.2,要访问 AS 2 里面的主机 172.17.0.3 的话。它发出的 IP 包,就会先到达自治系统 AS 1 上的路由器 Router 1。
- 而在此时,Router 1 的路由表里,有这样一条规则,即:目的地址是 172.17.0.2 包,应该经过 Router 1 的 C 接口,发往网关 Router 2(即:自治系统 AS 2 上的路由器)。
- 所以 IP 包就会到达 Router 2 上,然后经过 Router 2 的路由表,从 B 接口出来到达目的主机 172.17.0.3。
- 同理,如果主机 172.17.0.3 要访问 10.10.0.2 也是类似的。
两个 BGP 路由器(边界网关)的路由维护则是由 BGP 路由协议完成。在使用了 BGP 之后,每个边界网关上都会运行着一个程序,它们会将各自的路由表信息,通过 TCP 传输给其他的边界网关。而其他边界网关上的这个程序,则会对收到的这些数据进行分析,然后将需要的信息添加到自己的路由表里。
实现原理
Calico BGP 方式与 Flannel host-gw 方式是类似的。Calico 也通过在宿主机上添加路由来实现通信。Calico 会在每台宿主机上,添加一个如下所示的路由规则。其中”网关的 IP 地址“正是目的容器所在宿主机的 IP 地址。
<目的容器IP地址段> via <网关的IP地址> dev eth0
但与 Flannel host-gw 不同的是:
- Calico 使用 BGP 自动地在整个集群中分发路由信息,而 BGP 这种原生就是为大规模网络环境而实现的协议,其可靠性和可扩展性,远非 Flannel 自己的方案可比。
- Calico 项目不会在宿主机上创建任何网桥设备。
整个 Calico 项目由三个部分组成:
- Calico 的 CNI 插件,负责为容器创建相应的虚拟网络设备,及配置相应的网络栈。
- Felix。它是一个 DaemonSet,负责在宿主机上插入路由规则(即:写入 Linux 内核的 FIB 转发信息库),以及维护 Calico 所需的网络设备等工作。
- BIRD。它就是 BGP 的客户端,专门负责在集群里分发路由规则信息。
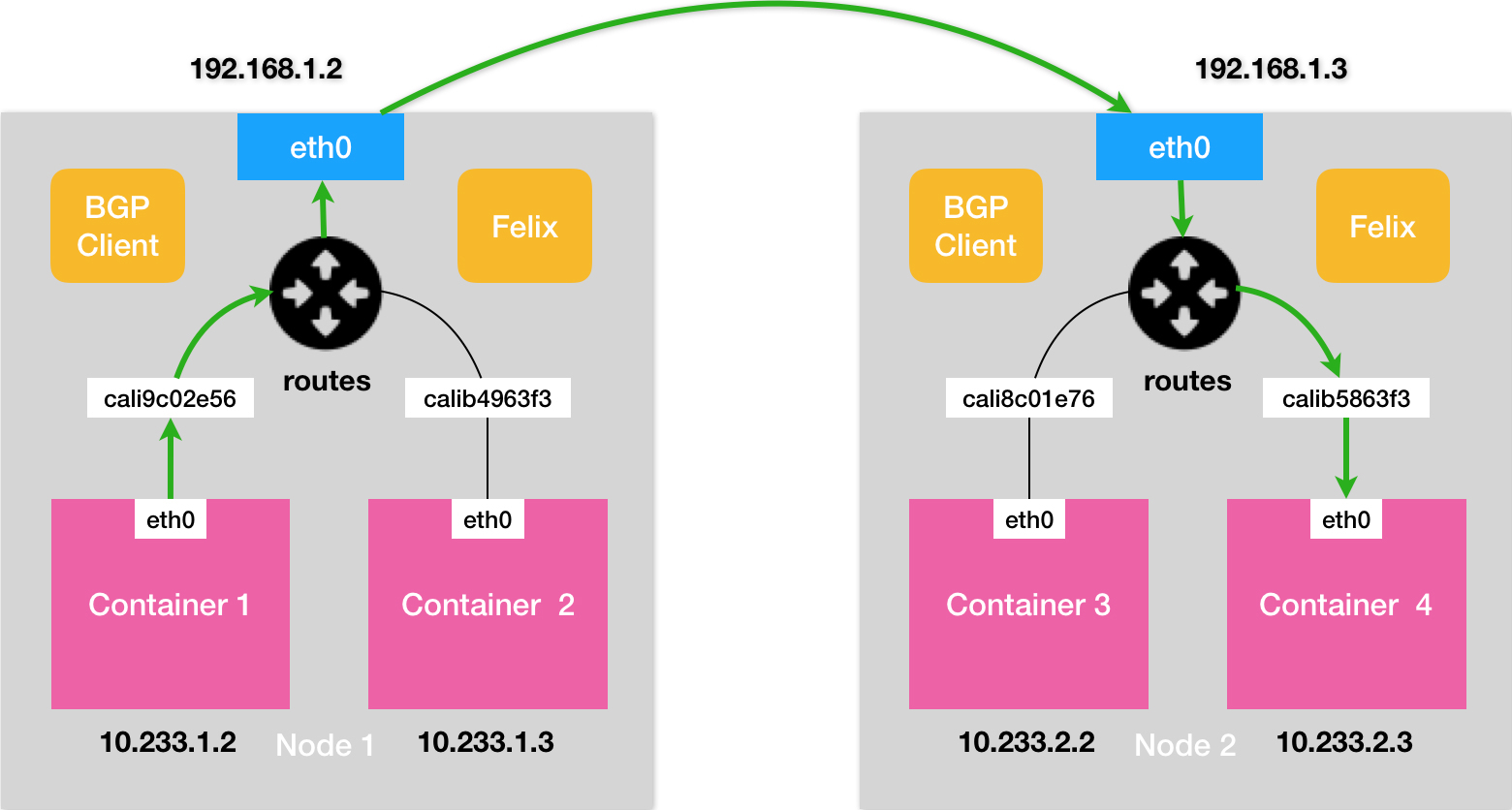
Calico 的工作流程如下所示,
通信流程图:
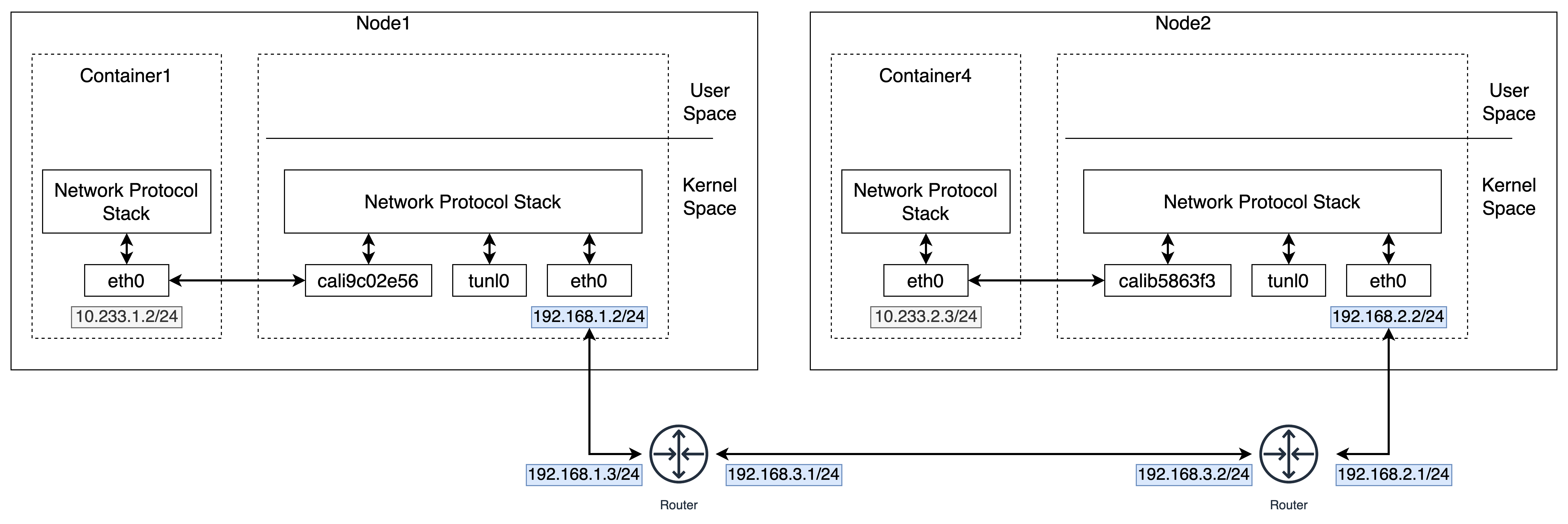
对应网络栈的层次结构图:

-
Calico 的 CNI 插件会为每个容器设置一个 Veth Pair 设备,并把其中的一端直接放置在宿主机上(它的名字以 cali 前缀开头,Calico 没有使用网桥)。
-
Calico 的 CNI 插件为宿主机上为每个容器的 Veth Pair 设备配置一条路由规则,用于接收传入的 IP 包。比如,宿主机 Node 2 上的 Container 4 对应的路由规则,如下所示:发往 10.233.2.3 的 IP 包,应该进入 cali5863f3 设备。
10.233.2.3 dev cali5863f3 scope link由于需要在宿主机上配置类似上述的路由,Calico 项目在宿主机上设置的路由规则,要比 Flannel 项目多得多。其实,Flannel host-gw 模式使用 CNI 网桥的主要原因,是为了跟 VXLAN 模式保持一致。否则,Flannel 需要维护两套 CNI 插件。
-
BIRD 组件(BGP Client 组件)使用 BGP 协议传输路由信息,如下所示
[BGP消息] 我是宿主机192.168.1.3 10.233.2.0/24网段的容器都在我这里 这些容器的下一跳地址是我 -
Calico 的 Felix 进程通过上述的路由信息,在宿主机上维护相应的路由规则。比如,在 Node1 主机上会被创建如下的路由规则,
10.233.2.0/24 via 192.168.1.3 dev eth0 -
基于上述的配置。
- 容器发出的 IP 包就会经过 Veth Pair 设备出现在宿主机上,
- 然后宿主机网络栈就会根据路由规则的“下一跳” IP 地址,把它们转发给正确的网关,也就是 Node2 的 eth0。
- 由于 Node2 上给每个容器的 Veth Pair 设备都配置了相应的路由,因此 IP 包最终会发给 Container 4。
注意:与 Flannel host-gw 模式最主要的限制类似,Calico BGP 也要求集群宿主机之间是二层连通的。假设 Node1 和 Node2 处于不同子网,它们对应的 IP 地址分别是 192.168.1.2 和 192.168.2.2。此时,Calico 在 Node 1 上添加的路由规则如下所示。
10.233.2.0/16 via 192.168.2.2 eth0
那么,当 Node1 上的 container1 要访问 Node2 上的 container4 时,要发送的数据包会来到 Node1 宿主机网络。Node1 的宿主机会通过 eth0 将这个数据包直接发送给下一跳 192.168.2.2,但是 Node2 和 Node1 压根不在一个子网里,无法通过二层网络把数据包发送给 Node2。
如果将上述的 192.168.2.2 改为中间路由器的 IP 地址,然后中间的路由器配置了相应的路由规则可以将该数据包发送给 Node2,那么最终也可以在三层互通的基础之上实现通过 BGP 模式实现互通。只是这个时候要求中间的路由器也加入到整个 BGP 网络中,详细下文介绍。
BGP Peer 通信模式选择
在 Calico 项目中,Calico 将集群中的所有节点,都当作是边界路由器来处理,它们一起组成了一个全连通的网络,互相之间通过 BGP 协议交换路由规则(这些节点也称为 BGP Peer)。Calico 支持两种模式维护网络中的路由规则,
- Calico 默认使用 Node-to-Node Mesh 模式。这种模式下,每台宿主机上的 BGP Client 都需要跟其他所有节点的 BGP Client 进行通信来交换路由信息。但是,随着节点数量 N 的增加,连接的数量会以 N² 的规模快速增长,给集群本身的网络带来巨大的压力。因此,Node-to-Node Mesh 模式一般推荐用在少于 100 个节点的集群里。在更大规模的集群中,推荐使用 Route Reflector 模式。
- Route Reflector 模式中,Calico 会指定一个或者几个专门的节点,来负责跟其他所有节点建立 BGP 连接,并学习到全局的路由规则。而其他节点,只需要跟这几个专门的节点交换路由信息,就可以获得整个集群的路由规则了。这些专门的节点,就是 Route Reflector 节点。它们通过扮演“中间代理”的角色,把 BGP 连接的规模控制在 N 的数量级上。
三层互通时,使用 BGP 模式
上述对于节点之间是三层互通,而非二层互通的情况,除了使用下文介绍的 IPIP 模式之外,Calico 项目如果能够让宿主机之间的路由设备(也就是网关),也通过 BGP 协议“学习”到 Calico 网络里的路由规则,那么从容器发出的 IP 包,其实也可以到达目的容器。
以下文中 IPIP 模式中的网络通信图为例,
在 Node 1 上,添加如下所示的一条路由规则:
10.233.2.0/24 via 192.168.1.1 eth0
Router 1 上(192.168.1.1),添加如下所示的一条路由规则,其中 router1 和 router2 通信的 IP 地址分别为 192.168.3.1、192.168.3.2。
10.233.2.0/24 via 192.168.3.2 eth0
Router2 上(192.168.2.1),添加如下所示的一条路由规则,
10.233.2.0/24 via 192.168.2.2 eth0
那么 Container 1 发出的 IP 包,就可以转发到 node2 上。
在 Kubernetes 被广泛使用的公有云场景里,上述的方式却完全不可行。主要原因在于公有云环境下,宿主机之间的网关,肯定不会允许用户进行干预和设置。当然在大多数公有云环境下,宿主机(公有云提供的虚拟机)本身往往就是二层连通的,所以这个需求也不强烈。
而在私有部署的环境下,宿主机属于不同子网(VLAN)是常见的部署状态,并且由于私有部署环境中的中间路由器可以设置。因此,这时候想办法将宿主机网关也加入到 BGP Mesh 里来避免使用 IPIP,就成了一个非常迫切的需求。在 Calico 项目中,有两种方式将宿主机中间的路由器(宿主机网关),设置成 BGP Peer:
- 第一种方案。所有宿主机都跟宿主机网关建立 BGP Peer 关系。这种方案下,Node 1 和 Node 2 就需要主动跟宿主机网关 Router 1 和 Router 2 建立 BGP 连接。从而将类似于 10.233.2.0/24 这样的路由信息同步到网关上去。需要注意的是,这种方式下,Calico 要求宿主机网关必须支持一种叫作 Dynamic Neighbors 的 BGP 配置方式。这是因为,在常规的路由器(网关) BGP 配置里,运维人员必须明确给出所有 BGP Peer 的 IP 地址。考虑到 Kubernetes 集群可能会有成百上千个宿主机,而且还会动态地添加和删除节点,这时候再手动管理路由器(网关)的 BGP 配置就非常麻烦了。而 Dynamic Neighbors 则允许你给路由器(网关)配置一个网段,然后路由器(网关)就会自动跟该网段里的主机建立起 BGP Peer 关系。
- 第二种方案(推荐)。使用一个或多个独立组件负责搜集整个集群里的所有路由信息,然后通过 BGP 协议同步给网关。在大规模集群中,Calico 本身就推荐使用 Route Reflector 节点的方式进行组网。所以,这里负责跟宿主机网关进行沟通的独立组件,直接由 Route Reflector 兼任即可。更重要的是,这种情况下网关的 BGP Peer 个数是有限并且固定的。所以我们就可以直接把这些独立组件配置成路由器的 BGP Peer,而无需 Dynamic Neighbors 的支持。当然,这些独立组件的工作原理也很简单:它们只需要 WATCH Etcd 里的宿主机和对应网段的变化信息,然后把这些信息通过 BGP 协议分发给网关即可。
IPIP(Overlay)
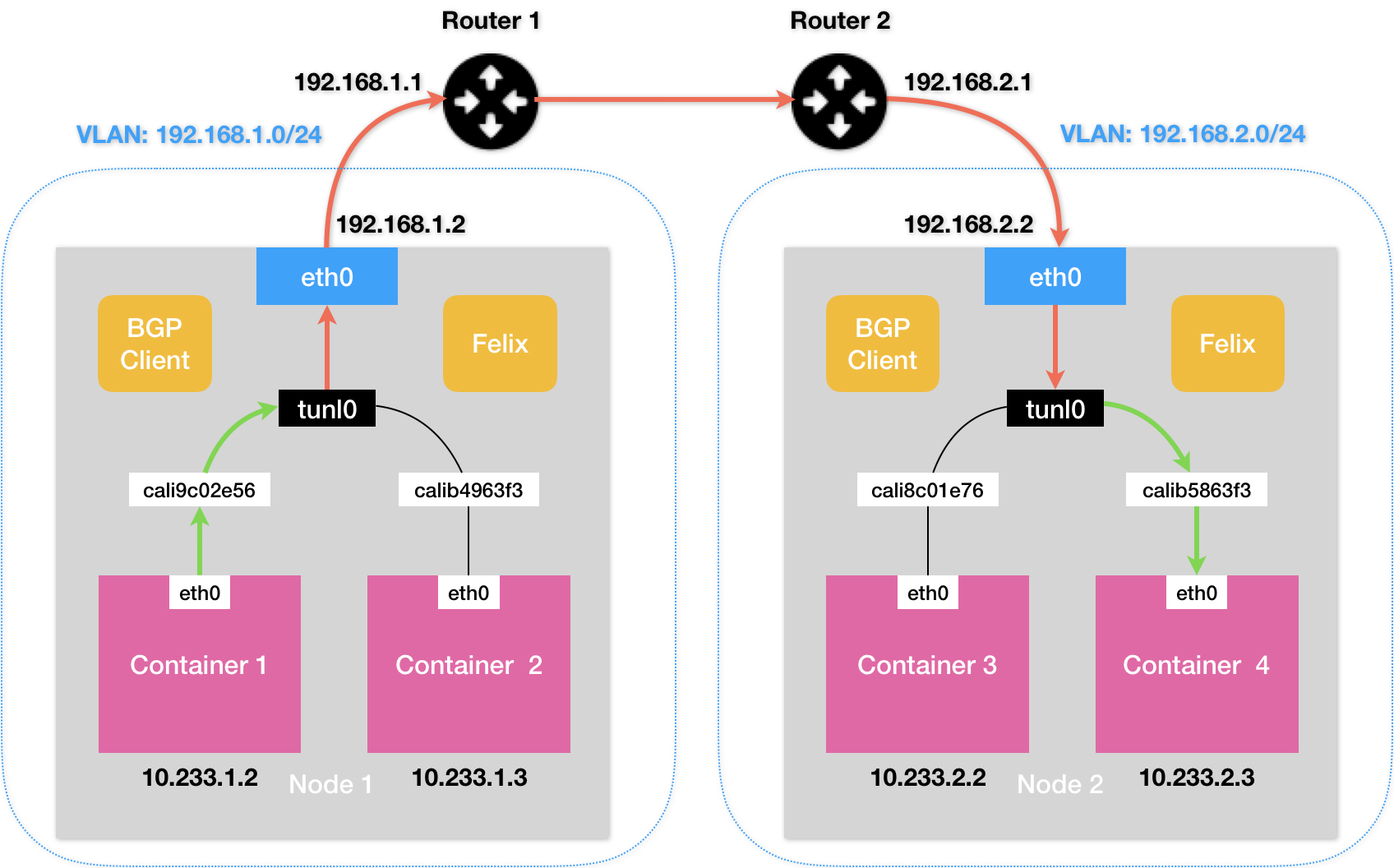
Calico 的 IPIP 模式可以解除 Calico 对宿主机要满足二层互通的限制。IPIP 模式的工作原理如下所示,
通信流程图:
对应网络栈的层次结构图:
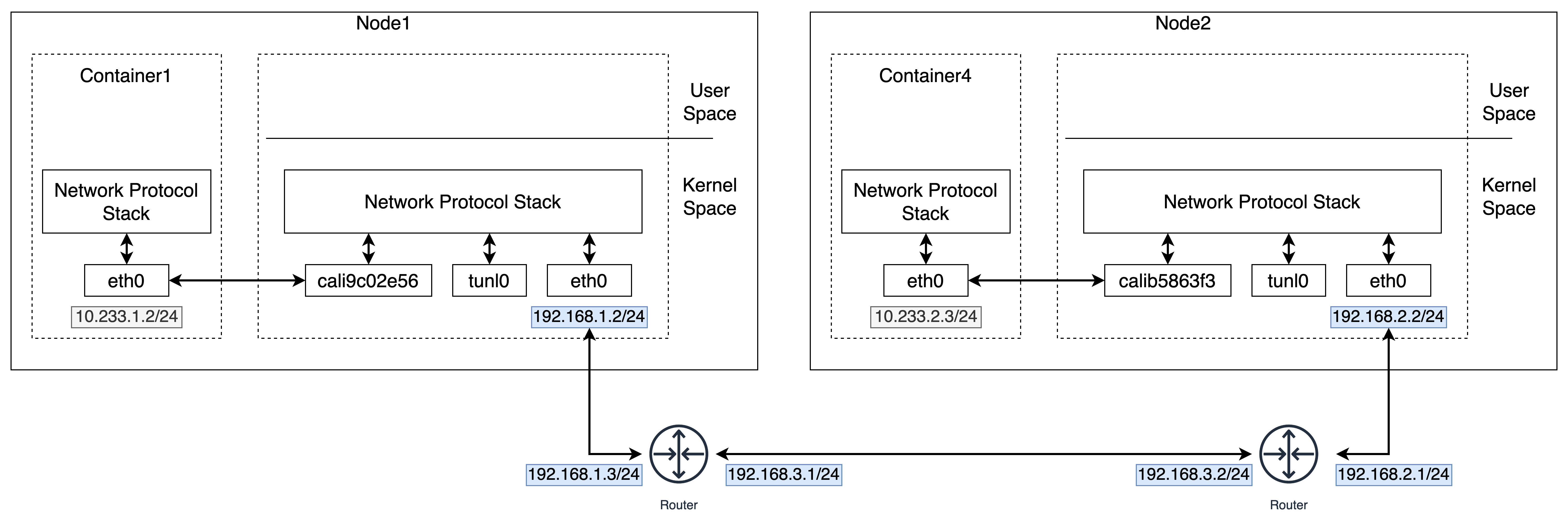
-
Felix 进程在 Node1 上添加如下的路由规则,与 BGP 模式有些不同。它表示要发送给 10.233.2.0/24 网段的 IP 包,需要通过 tunl0 设备(IP 隧道设备),并且“下一跳”是 192.168.2.2。
10.233.2.0/24 via 192.168.2.2 tunl0tunl0 类似于 Flannel 中的 VTEP,它会对数据包进行封装处理,包上额外的一层。
-
数据包进入 tunl0 设备之后,会被 Linux 内核的 IPIP 驱动接管。IPIP 驱动会将这个 IP 包直接封装在一个宿主机网络的 IP 包中。其中新的 IP 包的目的地址,是原 IP 包的下一跳地址,也就是 Node 2 的 IP 地址:192.168.2.2。而原 IP 包本身,则会被直接封装成新 IP 包的 Payload,新的 IP 包的 IP Header 中的 Protocol 被设置为 IPIP。
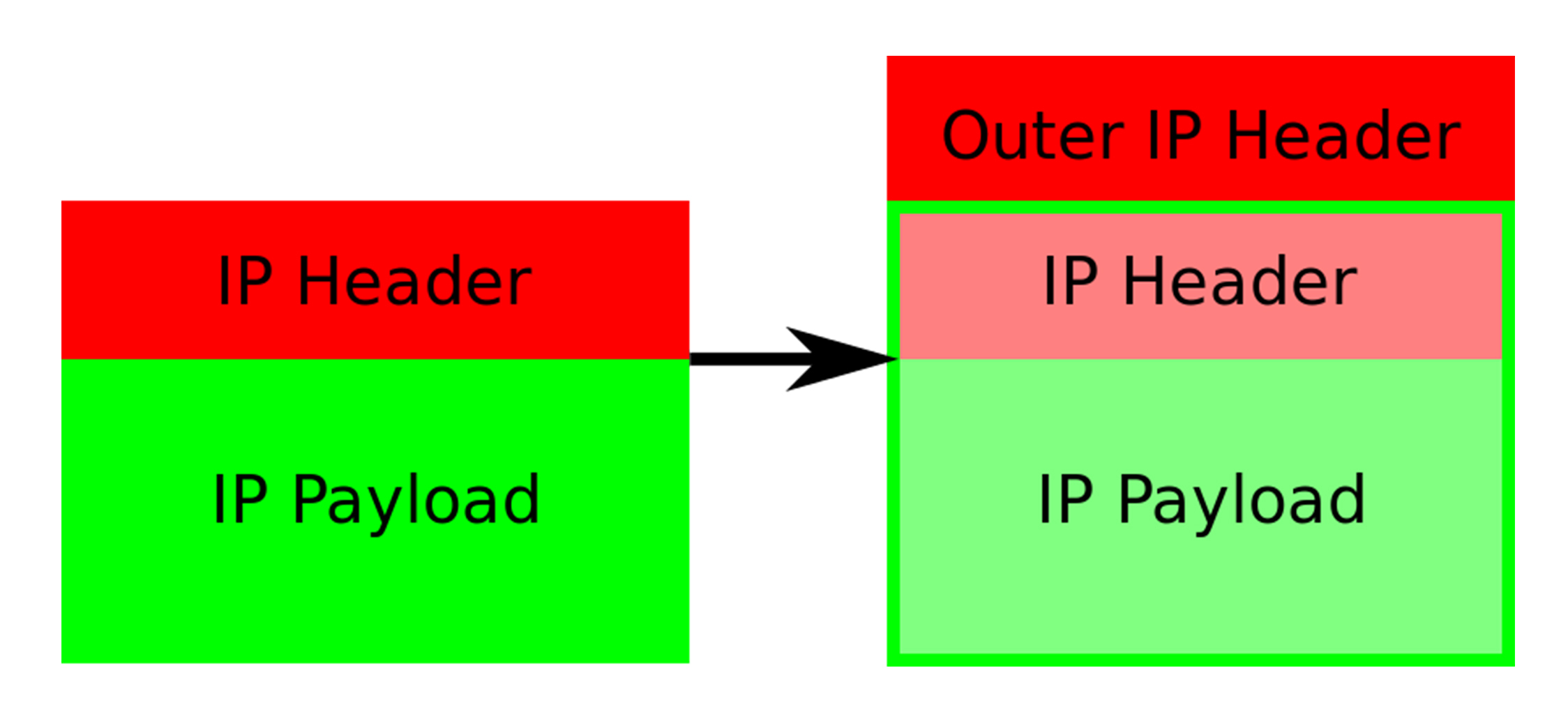
-
之后上述封装好的 IP 包会经过宿主机网络的路由选择,也就是根据新 IP 包的目的地址 192.168.2.2 来选择相应的路由。由于宿主机之间已经使用路由器配置了三层转发,也就是设置了宿主机之间的“下一跳”。所以这个 IP 包在离开 node1 之后,就可以经过路由器,最终“跳”到 node2 上。
-
node2 的网络内核栈会发现该 IP 包是 IPIP 协议的 IP 包(通过 IP Header 中的 Protocol)。然后使用 IPIP 驱动进行解包,拿到原始的 IP 包。而原始 IP 包再经过路由规则和 Veth Pair 设备到达目的容器内部。
注意:由于 IPIP 模式有额外的封包和解包工作,因此在实际测试中,Calico IPIP 模式与 Flannel VXLAN 模式的性能大致相当。因此,在实际使用 Calico 时,如非硬性需求,建议将所有宿主机节点放在一个子网里,避免使用 IPIP。
相关链接
- 极客时间.张磊.《深入剖析Kubernetes》
- K8s 高性能网络组件详解:Calico 的 IPIP 网络模式:https://mp.weixin.qq.com/s/JppA8NaGGLbGnzB5VbD08w
- IPIP协议实例分析:https://mp.weixin.qq.com/s/ngGDQhgukvaPDnDs7EOtNg

