问题
在了解 Event 资源之前,对 Event 资源的概念仅限于,它是 Kubernetes 中的一种资源,用于记录 Kubernetes 中发生的事件。因为对 Event 资源会有以下这些问题,
- Event 资源什么情况下会被产生?
- Event 资源中包含哪些内容?
- 如何发送 Event 资源?是直接调用 API 创建 Event 资源嘛?如果是这样的话,Event 资源会很多,那么怎么降低这些事件的存储成本呢?
简介
Event 资源是 Kubernetes 集群中记录事件的一种资源类型,它可以记录集群中发生的各种事件信息。系统中的各个组件会将运行时发生的各种事件上报给 APIServer。我们可以通过 kubectl get event 或 kubectl describe pod ${podName} 命令查看集群中发生了哪些事件。
Event 资源通常在以下情况下会被发送:
- 节点状态变化:当节点的状态发生变化时,如节点的加入、离线、故障等,会发送 Event 资源。Event 资源对象中包含了节点的名称、状态变化原因、事件的类型(正常或警告)以及事件发生的时间等信息。
- Pod 创建、更新、删除:当 Pod 对象被创建、更新或删除时,会发送 Event 资源。Event 资源对象中包含了 Pod 创建、更新和删除原因、Pod 所属的命名空间以及事件发生的时间等信息。
- 容器状态变化:如果 Pod 中的容器状态发生变化,比如容器的启动、停止、重启等,会发送 Event 资源。Event 资源对象中包含了容器的名称、容器状态的改变原因、事件的类型以及事件发生的时间等信息。
- API 对象的创建、更新、删除:如果其他类型的 API 对象,如 Service、Deployment 等的创建、更新或删除操作发生,也会发送 Event 资源。Event 资源中包含了对象类型、对象名称、操作原因以及事件发生的时间等信息。
与 Informer 中的 Event 事件区别
Kubernetes Event 资源和 Informer 中的 Event 事件是两个不同的概念。
- Event 资源是用于存储 Kubernetes 集群中发生的事件的一种资源类型,它是一个核心 API 资源,可以通过 Kubernetes API 进行创建、更新和查询。事件资源记录了集群中各种重要事件的详细信息,管理员和开发者可以通过查询事件资源来了解集群的状态和问题。
- Event 事件是 Informer 框架中的一个重要概念。当使用 Informer 对特定资源进行 watch 时,如果该资源发生了变化,Informer 会发送相应的 Event 事件。Event事件包含了该资源的详细信息,如资源的类型、名称、命名空间等,以及事件的类型、原因、描述信息等。
Event 资源的保存
默认情况下,Event 资源在集群中保留的时间是 1 小时(3600秒)。可以通过修改 kube-apiserver 的启动参数 --event-ttl 来调整 Event 资源的保留时间。如下所示为设置 Event 资源的保留时间为 2 小时(7200秒):
kube-apiserver --event-ttl=2h
API 定义
关于 Event 资源详细的定义,可以看 kubernetes 的文档 Event,也可以看源码,API 定义的源码位于 staging/src/k8s.io/api/core/v1/types.go 中。
type Event struct {
metav1.TypeMeta `json:",inline"`
metav1.ObjectMeta `json:"metadata" protobuf:"bytes,1,opt,name=metadata"`
// 该事件关联的对象
InvolvedObject ObjectReference `json:"involvedObject" protobuf:"bytes,2,opt,name=involvedObject"`
// 关联对象转变为当前状态的原因概述,一般也表示当前对象的状态
Reason string `json:"reason,omitempty" protobuf:"bytes,3,opt,name=reason"`
// 事件的详细描述
Message string `json:"message,omitempty" protobuf:"bytes,4,opt,name=message"`
// 报告此事件的组件
Source EventSource `json:"source,omitempty" protobuf:"bytes,5,opt,name=source"`
// 这一事件首次被记录下来的时间。(服务器接收时间为TypeMeta)
FirstTimestamp metav1.Time `json:"firstTimestamp,omitempty" protobuf:"bytes,6,opt,name=firstTimestamp"`
// 这一事件最近一次发生的记录时间。
LastTimestamp metav1.Time `json:"lastTimestamp,omitempty" protobuf:"bytes,7,opt,name=lastTimestamp"`
// 此事件发生的次数。
Count int32 `json:"count,omitempty" protobuf:"varint,8,opt,name=count"`
// 此事件的类型(Normal, Warning),后面的版本可能会添加新的类型
Type string `json:"type,omitempty" protobuf:"bytes,9,opt,name=type"`
// 这个事件第一次被观察到的时间。
EventTime metav1.MicroTime `json:"eventTime,omitempty" protobuf:"bytes,10,opt,name=eventTime"`
// 关于该事件表示的事件系列的数据,如果它是一个单例事件,则为 nil。
Series *EventSeries `json:"series,omitempty" protobuf:"bytes,11,opt,name=series"`
Action string `json:"action,omitempty" protobuf:"bytes,12,opt,name=action"`
// 用于更复杂操作的可选次要对象。
Related *ObjectReference `json:"related,omitempty" protobuf:"bytes,13,opt,name=related"`
// 触发此事件的控制器的名称,例如。“kubernetes.io/kubelet”。
ReportingController string `json:"reportingComponent" protobuf:"bytes,14,opt,name=reportingComponent"`
// 控制器实例的ID。“kubelet-xyzf”。
ReportingInstance string `json:"reportingInstance" protobuf:"bytes,15,opt,name=reportingInstance"`
}
kubectl get events 示例,

源码分析
下面的源码
Event 事件管理机制主要由三部分组成:
- EventRecorder:事件生成器,组件通过调用它的方法来生成事件。
- EventBroadcaster:事件广播器,负责分发 EventRecorder 产生的事件,会将事件分发给 EventWatcher。
- EventWatcher:定义事件的具体处理方式,比如上报 API Server。
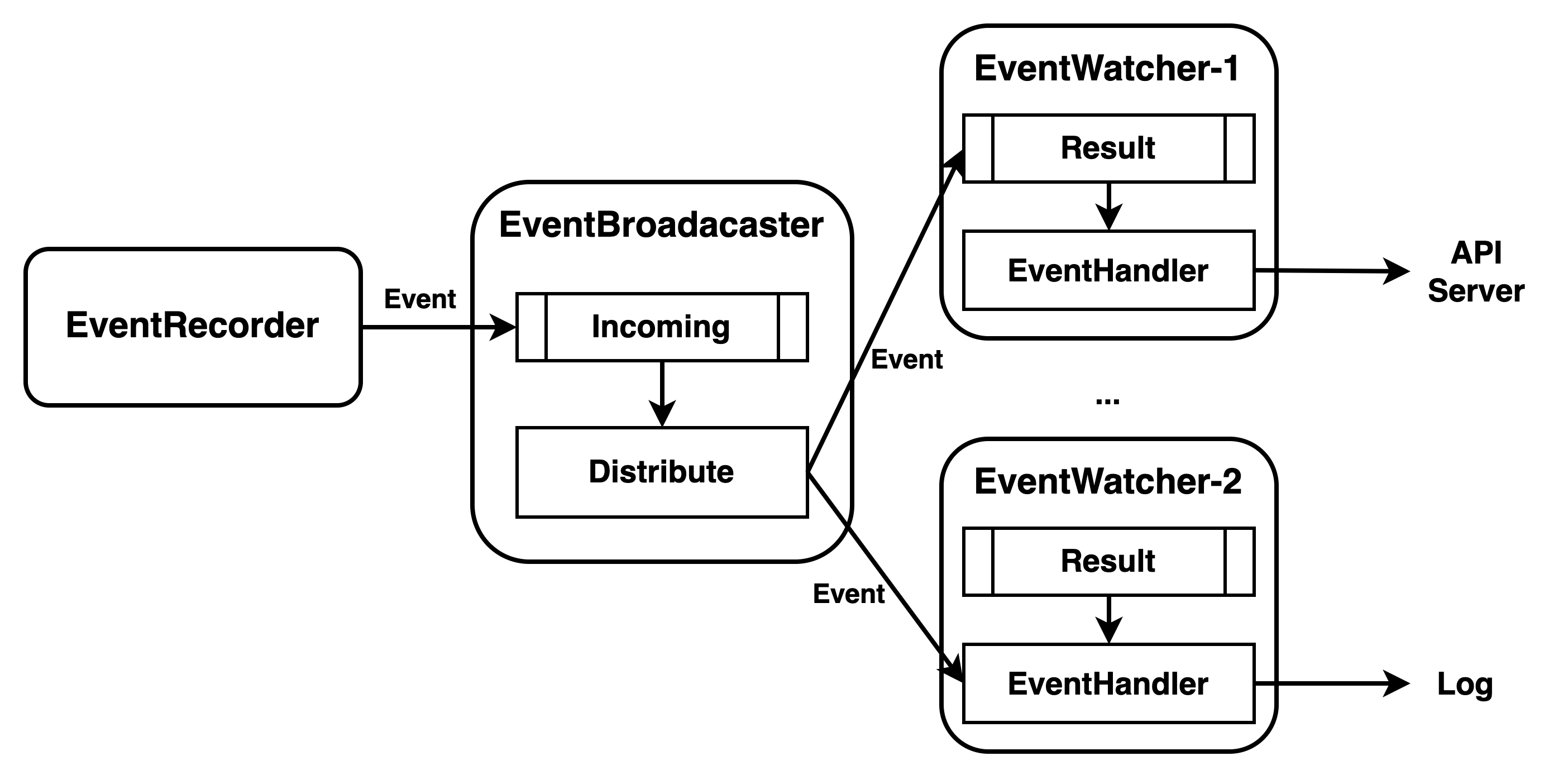
整体流程大概是:
- EventRecorder 产生事件,产生事件其实是发送到 EventBroadcaster 中的 incoming 队列;
- 之后 EventBroadcaster 会将事件分发给多个 EventWatcher;
- 不同 EventWatcher 对事件的处理方式是不一样,有的 EventWathcer 会将事件发送给 APIServer,有的 EventWatcher 则会将事件写入日志。
下面以 kubelet 中的 Event 事件管理为例进行详解。
1. 初始化
- 首先通过
NewBroadcaster创建 EventBroadcaster,也就是上述的事件广播器。 - 之后通过
NewRecorder创建 EventRecorder,也就是上述的事件生成器。 - 最后通过
StartStructuredLogging和StartRecordingToSink创建两个 EventWatcher,前者将事件写入日志,后者将事件发送给 API Server。
从代码角度来看的话,事件广播器这个角色,其实是由 EventBroadcaster 中的 Broadcaster 实现。但是,理解的话,可以抛开这些细节。
// 文件位置:cmd/kubelet/app/server.go
// makeEventRecorder sets up kubeDeps.Recorder if it's nil. It's a no-op otherwise.
func makeEventRecorder(kubeDeps *kubelet.Dependencies, nodeName types.NodeName) {
if kubeDeps.Recorder != nil {
return
}
eventBroadcaster := record.NewBroadcaster()
kubeDeps.Recorder = eventBroadcaster.NewRecorder(legacyscheme.Scheme, v1.EventSource{Component: componentKubelet, Host: string(nodeName)})
eventBroadcaster.StartStructuredLogging(3)
if kubeDeps.EventClient != nil {
klog.V(4).InfoS("Sending events to api server")
eventBroadcaster.StartRecordingToSink(&v1core.EventSinkImpl{Interface: kubeDeps.EventClient.Events("")})
} else {
klog.InfoS("No api server defined - no events will be sent to API server")
}
}
2. 发送事件
发送事件的接口
接口如下所示,不解释啥了。
type EventRecorder interface {
Event(object runtime.Object, eventtype, reason, message string)
// Eventf is just like Event, but with Sprintf for the message field.
Eventf(object runtime.Object, eventtype, reason, messageFmt string, args ...interface{})
// AnnotatedEventf is just like eventf, but with annotations attached
AnnotatedEventf(object runtime.Object, annotations map[string]string, eventtype, reason, messageFmt string, args ...interface{})
}
发送事件的过程
在创建 Recorder 的时候,会将 EventBroadcaster 传给 Recorder 中,代码中的 e.Broadcaster。
// eventBroadcasterImpl 是 EventBroadcaster 的具体实现
func (e *eventBroadcasterImpl) NewRecorder(scheme *runtime.Scheme, source v1.EventSource) EventRecorder {
return &recorderImpl{scheme, source, e.Broadcaster, clock.RealClock{}}
}
当我们使用 recorder.Event 或者 recorder.Eventf 发送事件的时候,核心代码如下所示。可以看到,产生的事件最终是发送到了 EventBroadcaster 中的 incoming 队列。
func (recorder *recorderImpl) Event(object runtime.Object, eventtype, reason, message string) {
recorder.generateEvent(object, nil, eventtype, reason, message)
}
func (recorder *recorderImpl) generateEvent(object runtime.Object, annotations map[string]string, eventtype, reason, message string) {
...
event := recorder.makeEvent(ref, annotations, eventtype, reason, message)
event.Source = recorder.source
...
sent, err := recorder.ActionOrDrop(watch.Added, event)
if err != nil {
klog.Errorf("unable to record event: %v (will not retry!)", err)
return
}
...
}
func (m *Broadcaster) ActionOrDrop(action EventType, obj runtime.Object) (bool, error) {
...
select {
case m.incoming <- Event{action, obj}:
return true, nil
default:
return false, nil
}
}
3. 分发事件
- 在初始化 EventBroadcaster 的时候,会异步启动一个循环
m.loop。在这个循环中,会不断调用m.distribute方法,在这个方法中会遍历m.watchers,不断向watcher中的 result channel 发送事件。
// Creates a new event broadcaster.
func NewBroadcaster() EventBroadcaster {
return newEventBroadcaster(watch.NewLongQueueBroadcaster(maxQueuedEvents, watch.DropIfChannelFull), defaultSleepDuration)
}
func NewLongQueueBroadcaster(queueLength int, fullChannelBehavior FullChannelBehavior) *Broadcaster {
m := &Broadcaster{
watchers: map[int64]*broadcasterWatcher{},
incoming: make(chan Event, queueLength),
stopped: make(chan struct{}),
watchQueueLength: queueLength,
fullChannelBehavior: fullChannelBehavior,
}
m.distributing.Add(1)
go m.loop()
return m
}
func (m *Broadcaster) loop() {
for event := range m.incoming {
...
m.distribute(event)
}
m.closeAll()
m.distributing.Done()
}
func (m *Broadcaster) distribute(event Event) {
if m.fullChannelBehavior == DropIfChannelFull {
for _, w := range m.watchers {
select {
case w.result <- event:
case <-w.stopped:
default: // Don't block if the event can't be queued.
}
}
} else {
for _, w := range m.watchers {
select {
case w.result <- event:
case <-w.stopped:
}
}
}
}
- 那么 kubelet 是怎么往
m.watchers中添加 Watcher 的呢?在StartStructuredLogging和StartRecordingToSink的时候,会创建 Watcher,并把 Watcher 添加到m.watchers中。
func (e *eventBroadcasterImpl) StartRecordingToSink(sink EventSink) watch.Interface {
eventCorrelator := NewEventCorrelatorWithOptions(e.options)
return e.StartEventWatcher(
func(event *v1.Event) {
...
})
}
func (e *eventBroadcasterImpl) StartEventWatcher(eventHandler func(*v1.Event)) watch.Interface {
watcher, err := e.Watch()
if err != nil {
klog.Errorf("Unable start event watcher: '%v' (will not retry!)", err)
}
...
return watcher
}
func (m *Broadcaster) Watch() (Interface, error) {
var w *broadcasterWatcher
m.blockQueue(func() {
id := m.nextWatcher
m.nextWatcher++
w = &broadcasterWatcher{
result: make(chan Event, m.watchQueueLength),
stopped: make(chan struct{}),
id: id,
m: m,
}
m.watchers[id] = w
})
if w == nil {
return nil, fmt.Errorf("broadcaster already stopped")
}
return w, nil
}
4. 处理事件
- 上述已经提到
m.loop会不断向watcher中的 result channel 发送事件
func (m *Broadcaster) distribute(event Event) {
if m.fullChannelBehavior == DropIfChannelFull {
for _, w := range m.watchers {
select {
case w.result <- event:
case <-w.stopped:
default: // Don't block if the event can't be queued.
}
}
} else {
for _, w := range m.watchers {
select {
case w.result <- event:
case <-w.stopped:
}
}
}
}
-
那么 Watcher 是如何处理这些事件的呢?可以猜想的大致流程就是不断从
w.result中读取事件,然后调用相应的方法进行处理。实际上确实也是这么个过程。在
StartStructuredLogging和StartRecordingToSink的时候,除创建 Watcher,并将 Watcher 添加到m.watchers中之外,还会异步运行一个 goroutine。在这个 goroutine 中,不断从w.result中读取事件,然后使用传入eventHandler函数进行处理。
func (e *eventBroadcasterImpl) StartRecordingToSink(sink EventSink) watch.Interface {
eventCorrelator := NewEventCorrelatorWithOptions(e.options)
return e.StartEventWatcher(
func(event *v1.Event) {
e.recordToSink(sink, event, eventCorrelator)
})
}
func (e *eventBroadcasterImpl) StartEventWatcher(eventHandler func(*v1.Event)) watch.Interface {
watcher, err := e.Watch()
if err != nil {
klog.Errorf("Unable start event watcher: '%v' (will not retry!)", err)
}
go func() {
defer utilruntime.HandleCrash()
for watchEvent := range watcher.ResultChan() {
event, ok := watchEvent.Object.(*v1.Event)
if !ok {
// This is all local, so there's no reason this should
// ever happen.
continue
}
eventHandler(event)
}
}()
return watcher
}
func (mw *broadcasterWatcher) ResultChan() <-chan Event {
return mw.result
}
下面重点介绍 StartRecordingToSink 创建的 Watcher 使用的 eventHandler,也就是 recordToSink 函数。
recordToSink
recordToSink 的作用是往 API Server 中发送事件。考虑到 API Server、Etcd 的压力,recordToSink 会先对事件进行预处理,避免产生的事件过多。
- 其中
EventCorrelate方法是对事件预处理,比如对事件进行聚合、计数、过滤等。我们重点分析这个函数。 recordEvent是将事件发送给 API Server。如果发送失败会重试,每次重试都有一定时间间隔。默认重试次数是 12 次,默认重试间隔是 10 秒钟。
func (e *eventBroadcasterImpl) recordToSink(sink EventSink, event *v1.Event, eventCorrelator *EventCorrelator) {
...
eventCopy := *event
event = &eventCopy
result, err := eventCorrelator.EventCorrelate(event)
...
for {
if recordEvent(sink, result.Event, result.Patch, result.Event.Count > 1, eventCorrelator) {
break
}
...
}
在 EventCorrelate 方法中主要通过三个方法对事件进行预处理:
EventAggregate方法是对相似事件做聚合,将相似事件作为同一个事件;eventObserve方法是对事件进行计数,建立在聚合的基础之上,表示相应事件发生的次数;filterFunc方法是对事件做过滤。
func (c *EventCorrelator) EventCorrelate(newEvent *v1.Event) (*EventCorrelateResult, error) {
if newEvent == nil {
return nil, fmt.Errorf("event is nil")
}
aggregateEvent, ckey := c.aggregator.EventAggregate(newEvent)
observedEvent, patch, err := c.logger.eventObserve(aggregateEvent, ckey)
if c.filterFunc(observedEvent) {
return &EventCorrelateResult{Skip: true}, nil
}
return &EventCorrelateResult{Event: observedEvent, Patch: patch}, err
}
针对 EventAggregate 方法来说,代码如下所示,整体上的逻辑是:
-
EventAggregator 有一个 cache。cache 的 key 是 event 中 Source、InvolvedObject(不包含 FieldPath)、Type、Reason、ReportingController、ReportingInstance 等信息拼接而成的字符串。cache 的 value 是 event message 组成的 set 集合。(PS:可以理解成 Kubernetes 将 Source、InvolvedObject、Type、Reason、ReportingController、ReportingInstance 等信息均相同的 Event 作为相似的 Event)
-
如果 cache 中相同 key 的不同 message 的数量大于等于最大数量(默认最大数量是 10)的话,也就是 value 中 message 的数量大于等于最大数量的话,则考虑对相似的事件进行聚合。
这个时候会 copy 当前事件,并在当前事件的 message 前面加上
(combined from similar events):的内容。最终,该方法返回的是更改后的事件和 cache 中对应的 key,这个 key 可以理解为聚合后的 key。
-
如果 cache 中相同 key 的不同 message 的数量小于最大数量的话,则不考虑对相似的事件进行聚合。
因此,会直接返回当前事件和由 event 中 Source、InvolvedObject(包含 FieldPath)、Type、Reason、Message 等信息组成的 key,这个 key 相当于是当前事件的标识符。
func (e *EventAggregator) EventAggregate(newEvent *v1.Event) (*v1.Event, string) {
now := metav1.NewTime(e.clock.Now())
var record aggregateRecord
// eventKey is the full cache key for this event
eventKey := getEventKey(newEvent)
// aggregateKey is for the aggregate event, if one is needed.
aggregateKey, localKey := e.keyFunc(newEvent) // keyFunc 实际上是 EventAggregatorByReasonFunc 函数
...
value, found := e.cache.Get(aggregateKey)
if found {
record = value.(aggregateRecord)
}
maxInterval := time.Duration(e.maxIntervalInSeconds) * time.Second
interval := now.Time.Sub(record.lastTimestamp.Time)
if interval > maxInterval {
record = aggregateRecord{localKeys: sets.NewString()}
}
record.localKeys.Insert(localKey)
record.lastTimestamp = now
e.cache.Add(aggregateKey, record)
if uint(record.localKeys.Len()) < e.maxEvents {
return newEvent, eventKey
}
eventCopy := &v1.Event{
ObjectMeta: metav1.ObjectMeta{
Name: fmt.Sprintf("%v.%x", newEvent.InvolvedObject.Name, now.UnixNano()),
Namespace: newEvent.Namespace,
},
Count: 1,
FirstTimestamp: now,
InvolvedObject: newEvent.InvolvedObject,
LastTimestamp: now,
Message: e.messageFunc(newEvent), // meesageFunc 实际上是 EventAggregatorByReasonMessageFunc
Type: newEvent.Type,
Reason: newEvent.Reason,
Source: newEvent.Source,
}
return eventCopy, aggregateKey
}
func getEventKey(event *v1.Event) string {
return strings.Join([]string{
event.Source.Component,
event.Source.Host,
event.InvolvedObject.Kind,
event.InvolvedObject.Namespace,
event.InvolvedObject.Name,
event.InvolvedObject.FieldPath,
string(event.InvolvedObject.UID),
event.InvolvedObject.APIVersion,
event.Type,
event.Reason,
event.Message,
},
"")
}
func EventAggregatorByReasonFunc(event *v1.Event) (string, string) {
return strings.Join([]string{
event.Source.Component,
event.Source.Host,
event.InvolvedObject.Kind,
event.InvolvedObject.Namespace,
event.InvolvedObject.Name,
string(event.InvolvedObject.UID),
event.InvolvedObject.APIVersion,
event.Type,
event.Reason,
event.ReportingController,
event.ReportingInstance,
},
""), event.Message
}
func EventAggregatorByReasonMessageFunc(event *v1.Event) string {
return "(combined from similar events): " + event.Message
}
针对 eventObserve 方法来说,代码如下所示,整体上的逻辑是:
eventLogger有一个 cache。cache 的 key 是EventAggregate方法返回的,有两种情况:一种是表示聚合后的 key,一种是具有事件标识性的 key。cache 的 value 是eventLogstruct记录了事件发生的次数、事件第一次发生的时间、事件的名字、事件的 ResourceVersion 等相关信息,后三者的信息由第一条事件提供。eventObserve方法使用 key 从 cache 中拿到相应的 value,根据 value 的内容更新传入的 event 内容,其中重要的更新是将 count 数量加一,其他信息则更新为该 key 对应的第一条事件的内容。- 同时,更新 value 中的内容,并将更新后的 value 写回 cache。
- 最红,返回更新后的 event 和相应的 patch。
上述的流程,总结下:
-
Event 资源中的 Source、InvolvedObject(不包含 FieldPath)、Type、Reason、ReportingController、ReportingInstance 等信息作为 Kubernetes 中 Event 事件聚合的判断依据。如果两个事件的上述信息相同则表示是相似的事件(FieldPath、Message 可能不一样),则可以进行聚合。
这里可以看到事件聚合判断的依据,是很好理解的,主要就是看发出事件的组件、事件的类型、事件的原因、事件涉及的对象是不是同一个。FieldPath 表示某个对象的一部分,比如对于 Pod 来说,如果是某个 Container 发出的事件的话,FieldPath 则可能是
spec.containers[2]。这里不包含 FieldPath,个人理解是考虑整体对象,不考虑对象中某一部分的情况。 -
如果相似事件中 Message 不同的数量较多,考虑到相似事件较多会对 API Server、Etcd 造成压力,才会进行聚合,并且对聚合后的事件进行计数。如果 Message 不同的数量较少,则不考虑聚合,相当于每个事件会单独计数。
func (e *eventLogger) eventObserve(newEvent *v1.Event, key string) (*v1.Event, []byte, error) {
var (
patch []byte
err error
)
eventCopy := *newEvent
event := &eventCopy
...
// Check if there is an existing event we should update
lastObservation := e.lastEventObservationFromCache(key)
// If we found a result, prepare a patch
if lastObservation.count > 0 {
// update the event based on the last observation so patch will work as desired
event.Name = lastObservation.name
event.ResourceVersion = lastObservation.resourceVersion
event.FirstTimestamp = lastObservation.firstTimestamp
event.Count = int32(lastObservation.count) + 1
eventCopy2 := *event
eventCopy2.Count = 0
eventCopy2.LastTimestamp = metav1.NewTime(time.Unix(0, 0))
eventCopy2.Message = ""
newData, _ := json.Marshal(event)
oldData, _ := json.Marshal(eventCopy2)
patch, err = strategicpatch.CreateTwoWayMergePatch(oldData, newData, event)
}
// record our new observation
e.cache.Add(
key,
eventLog{
count: uint(event.Count),
firstTimestamp: event.FirstTimestamp,
name: event.Name,
resourceVersion: event.ResourceVersion,
},
)
return event, patch, err
}
filterFunc 方法其实是 EventSourceObjectSpamFilter.Filter。该方法是根据限速的情况判断是否要对事件进行过滤:如果不超过限速,则不过滤该事件;反之则过滤该事件。
EventSourceObjectSpamFilter也有一个 cache,cache 的 key 由 Source、InvolvedObject 等信息组成的。cache 的 value 是spamRecordstruct,struct 里面只有一个限速器。- 因此,限速主要针对同一个 Source、同一个对象的相关事件的发送进行限速。
func (f *EventSourceObjectSpamFilter) Filter(event *v1.Event) bool {
var record spamRecord
eventKey := f.spamKeyFunc(event) // getSpamKey 函数
f.Lock()
defer f.Unlock()
value, found := f.cache.Get(eventKey)
if found {
record = value.(spamRecord)
}
if record.rateLimiter == nil {
record.rateLimiter = flowcontrol.NewTokenBucketPassiveRateLimiterWithClock(f.qps, f.burst, f.clock)
}
// ensure we have available rate
filter := !record.rateLimiter.TryAccept()
// update the cache
f.cache.Add(eventKey, record)
return filter
}
func getSpamKey(event *v1.Event) string {
return strings.Join([]string{
event.Source.Component,
event.Source.Host,
event.InvolvedObject.Kind,
event.InvolvedObject.Namespace,
event.InvolvedObject.Name,
string(event.InvolvedObject.UID),
event.InvolvedObject.APIVersion,
},
"")
}
EventAggregate、eventObserve和filterFunc方法中用到的 cache,使用的都是 LRU 数据结构。下次会对这个数据结构进行解析。
回答问题
回到本文最初的几个问题上:
-
Event 资源什么情况下会被产生?请看 简介
-
Event 资源中包含哪些内容?请看 [API 定义](#API 定义)
-
如何发送 Event 资源?是直接调用 API 创建 Event 资源嘛?如果是这样的话,Event 资源会很多,那么怎么降低这些事件的存储成本呢
请看 源码分析。Kubernetes 组件创建 Event 资源的过程,并不是直接调用 API 创建 Event 资源,它会经过聚合、过滤之后,才真正地创建 Event 资源。

