1. 基于 inode 的文件系统
下面介绍的所有存储结构是指保存在块存储设备上的。
1.1. inode
inode 是 index node 的缩写,即索引节点,记录了一个文件所对应的所有存储块的块号(即存储的索引)和该文件相关的其他元数据。
1.1.1. 块号的记录
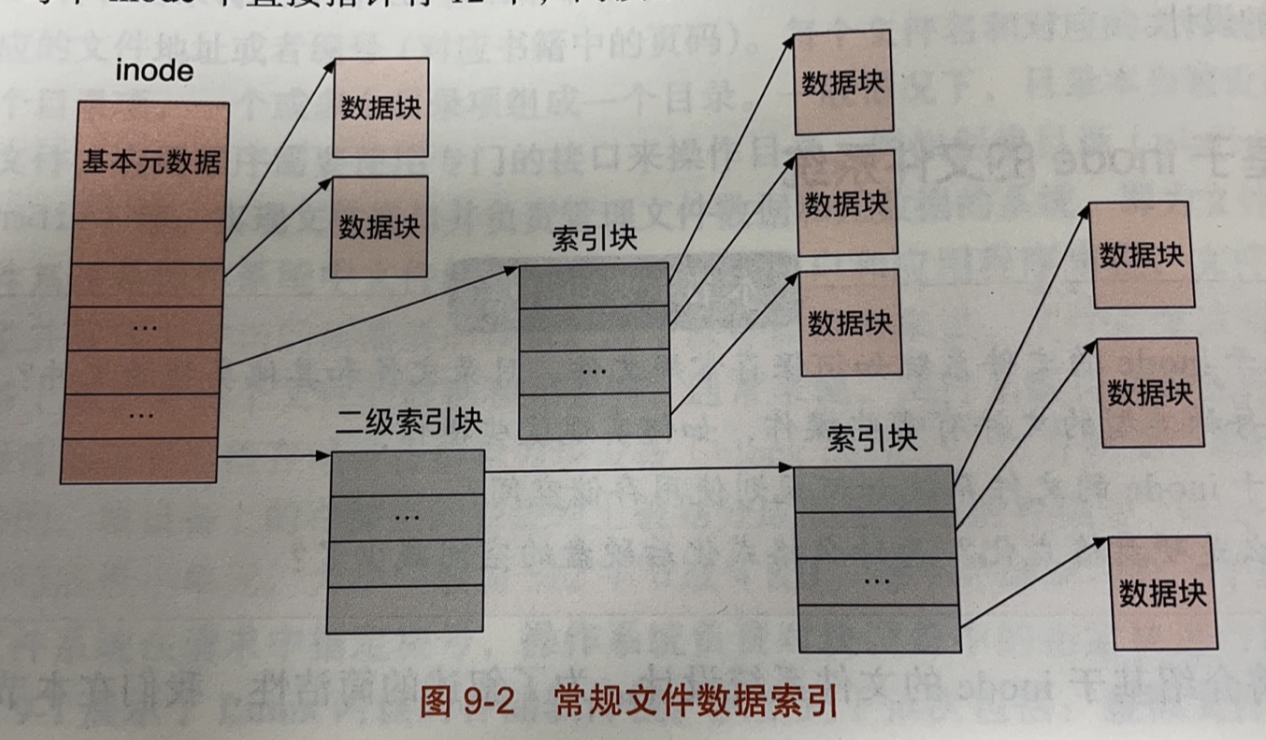
inode 中一般采用分级的方式来组织存储块号,如下图所示。inode 中保存了三种存储指针:
- 第一种指针为直接指针,其直接指向数据块,数据块中保存了文件数据;
- 第二种指针为间接指针,指向一个一级索引块,一级索引块中存放着指向数据块的指针;
- 第三种指针为二级间接指针,指向一个二级索引块,二级索引块中的每个指针均指向一个一级索引块,进而指向多个数据块。
从这种组织方式中可以看出,一个文件系统所支持的最大文件大小受文件数据组织方式的限制(其他因素同样限制着最大文件大小,如 inode 中文件大小这项元数据所占的存储空间,比如这项元数据占了 4 个字节,那么最大文件大小为 $2^{32}$ 字节,即 4GB )。因此,我们可以通过调整 inode 的设计来改变其所能管理的最大文件大小。比如使用更多的二级指针,甚至使用三级指针或者四级指针。
1.1.2. 元数据
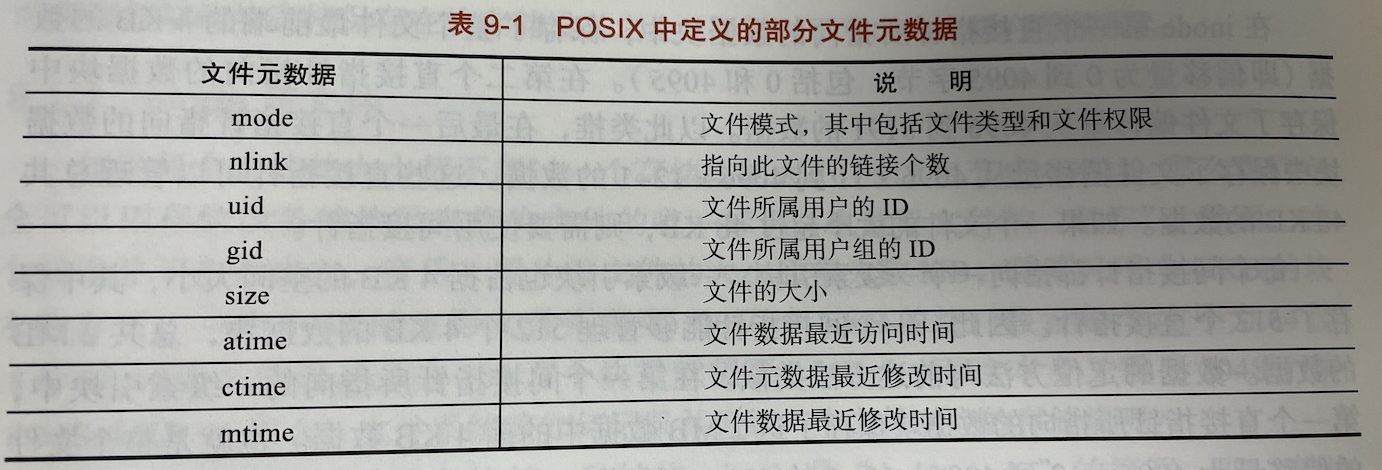
inode 中记录的元数据信息包括文件模式、文件链接数、文件拥有者和用户组、文件大小、文件访问时间等。
1.2. 文件
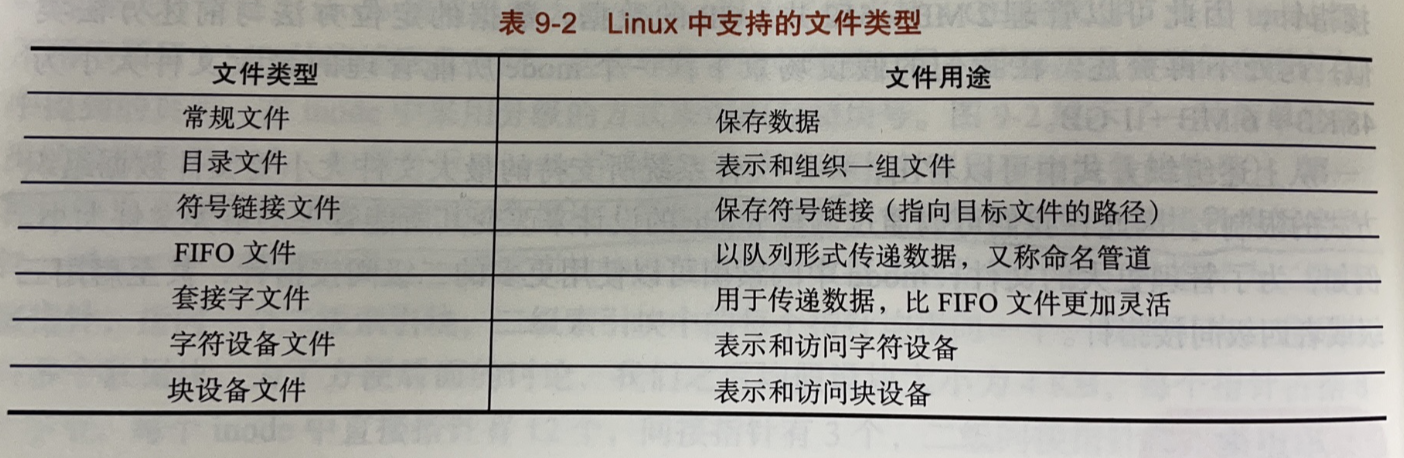
一个文件系统一般会支持多种文件类型,比如常规文件、目录文件和符号链接文件。不同类型的文件保存不同种类的数据,在数据存储格式和使用方法上也会有所区别。
1.2.1. 文件名和目录
1.2.1.1. 文件名
文件和 inode 是一一对应的,对于计算机程序来说,通过 inode 号就可以找到对应的文件。但是对于用户来说,使用 inode 号作为文件名进行记忆比较困难。同时使用 inode 号直接表示文件会造成 inode 号与文件存储位置的强耦合,因为在 inode 号和文件 inode 结构的存储位置一一对应的情况下,文件系统在不改变 inode 号情况下无法改变 inode 的存储位置,也无法用一个新的 inode 号指代一个已有的 inode 结构。
为了对用户更加友好,文件系统加入了字符串形式的文件名,从而增加了一层从文件名字符串到 inode 之间的映射。字符串形式的文件名不但方便记忆,也使得文件名和文件具体的存储位置实现了解耦。
inode 文件系统中,文件名并不是文件的元数据,文件名存放在目录中。
1.2.1.2. 目录
目录是一种特殊类型的文件,记录了文件名到 inode 号的映射。目录本身也是文件(用 inode),与常规文件中保存的用户数据不同,目录中保存的是目录项。每个目录项代表一条文件信息,记录了文件的文件名及其对应的 inode 号。因此,可以通过递归的方式来结构化组织文件系统中的文件。同时,目录项是一个接一个地存放在文件的数据块中的,组成一个连续的字符序列,从而可以直接复用常规文件的数据组织方式。
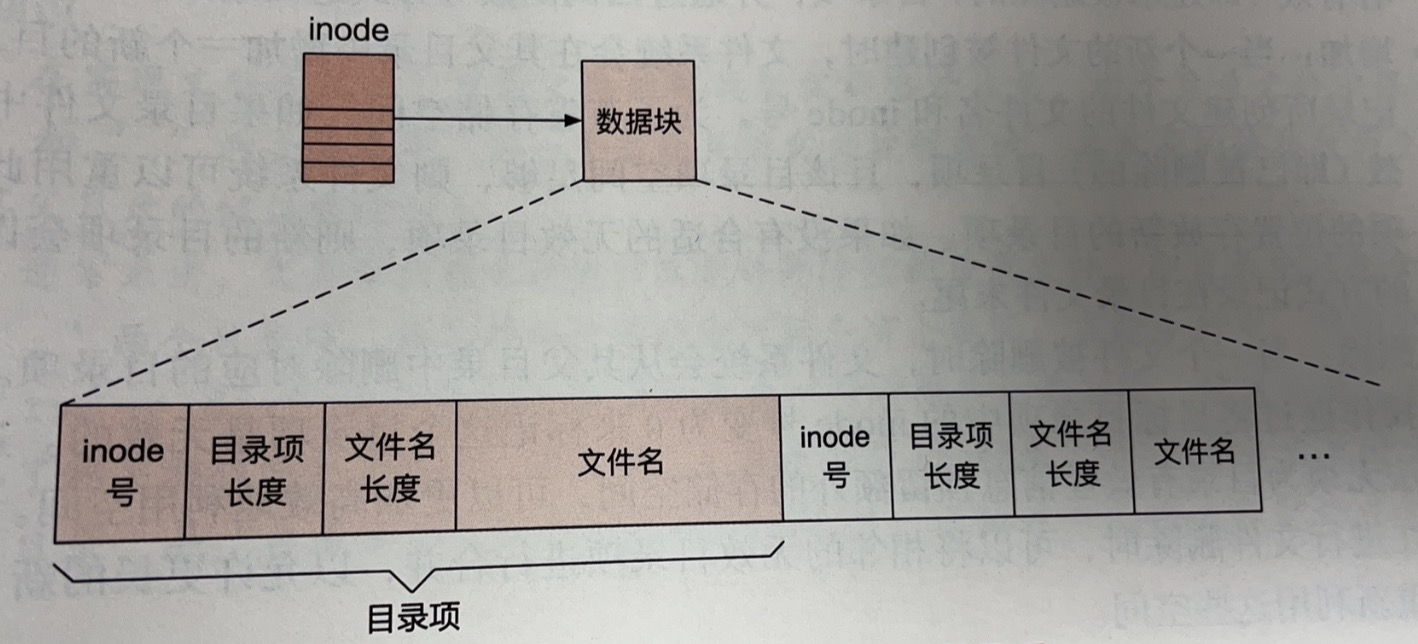
一个目录项内的结构,包括文件名、文件名长度、文件名对应的 inode 号和目录项长度(在一些文件系统中,目录项还会保存目标文件的类型,以避免在进行目录遍历时访问目标 inode)。
- 目录项中的 inode 号用于找到文件名对应的 inode 结构,从而访问文件数据和元数据。
- 目录项长度用于记录整个目录项的长度,主要为了目录项的删除和重用而设计。
- 文件名长度则记录着后面保存的文件名的有效长度。
1.2.1.3. 目录的操作
对目录的操作主要包括查找、遍历、增加和删除目录项。
- 查找:在目录中查找某个文件时,将从目录文件中存放的第一个目录项开始,依次比较目录项中存放的文件名。当目录项中的文件名和查找的文件名相同时,根据该目录项保存的 inode 号找到文件的 inode,从而在 inode 上进行各种操作。
- 遍历:遍历操作和查找操作类似,文件系统依次检查目录文件中保存的所有有效目录项,并通过回调函数等方式返回结果。
- 增加:当一个新的文件被创建时,文件系统会在其父目录中增加一个新的目录项,记录所创建文件的文件名和 inode 号。为了节省存储空间,如果目录文件中有无效(即已被删除的)目录项,且该目录项空间足够,则文件系统可以重用此目录项的位置存放新的目录项。如果没有合适的无效目录项,则新的目录项会以追加的方式记录在目录文件末尾。
- 删除:当一个文件被删除时,文件系统会从其父目录中删除对应的目录项。删除操作通过将目标目录项中的 inode 号变为 0 来标记这个目录项是无效的。这种方式无须为目录有效性信息预留额外的存储空间,可以更加高效地利用空间。同时,在进行文件删除时,可以将相邻的无效目录项进行合并,以允许更长的新目录项重新利用这些空间。
每个目录文件中有两个特殊的目录项,其中保存的文件名分别为
.和..,对应的 inode 号分别为该目录本身和其父目录。在访问时,这两个目录项与其他目录项没有不同。但这两个目录项是由文件系统进行管理,与目录文件一同被创建和删除。对根目录来说,.和..对应的 inode 号均为根目录自身。
1.2.2. 硬链接与符号链接
1.2.2.1. 硬链接
由于文件名并不是文件的元数据,因此一个文件可以对应多个文件名,即一个 inode 对应多个文件名。同时也表示多个目录项可以指向同一个 inode,即同一个文件。
在 linux 中,可通过 ln file link 为文件 file 创建另一个名字 link,这里的 link 就是 file 的硬链接(hard link)。当用户创建一个新的硬链接时,文件系统并不会创建一个新的 inode,而是先找到目标文件(file)的 inode,然后在目录路径(link)的父目录中增加一个指向该此 inode 的新目录项。
从文件系统的角度来看,file 和 link 没有任何区别。换句话说,一个硬链接一旦创建成功,其与原来的文件是同等地位的。对其中任意一个硬链接的读写操作或者元数据修改,都会影响到指向同一个 inode 的其他硬链接。
考虑到硬链接的存在,一个 inode 可能会被多个目录项所指向。为了准确地记录何时能够将 inode 及其索引的数据从文件系统中删除,文件系统在 inode 中记录了一个链接数,表示有多少个目录项指向这个 inode。当一个目录项被加入目录文件中时,该目录项对应的 inode 的链接数会增加 1;每当一个目录项被删除时,该目录项对应的 inode 的链接数会减少 1。当 inode 的链接数为 0 时,inode 及其索引的结构可以被销毁,相应的存储空间可以被释放。
1.2.2.2. 符号链接
符号链接(symbolic link)又称为软链接(soft link),是一种特殊的文件类型(有 inode)。在 Linux 中,可以通过 ln -s file slink 来为 file 创建名为 slink 的软链接。
与常规文件保存数据、目录文件保存目录项不同,符号链接文件中保存的是一个字符串,表示一个文件路径。这个文件路径所对应的文件为目标文件。由于路径的长度一般不会过长,符号链接文件的一个简单实现是将路径目标文件字符串直接保存在 inode 中,占据原本用于保存数据块指针的空间。
符号链接除了创建、删除和更新元数据之外,符号链接本身只支持读取操作。读取操作的过程:找到符号链接文件的 inode,并返回其中保存的路径即可。如果需要修改符号链接文件中的内容,一般需要删除原符号链接文件,再使用新的路径创建一个名字相同的符号链接文件。
符号链接文件本身的操作和实现并不复杂,但是其对路径解析的过程会产生较大影响。在不考虑符号链接的情况下,整个路径解析比较简单与直接:只需要在每一层目录中,查找路径里的下一个文件,直到整个路径都解析完毕即可。然而,在支持符号链接的情况下,每解析完路径中的一部分,文件系统都需要判断当前得到的文件是否为符号链接,如果是符号链接,要先跟随符号链接中的路径找到目标文件,然后继续在这个基础之上解析原路径的剩余部分。
1.2.2.3. 符号链接和硬链接的区别
- 两者均允许应用程序使用一个新的路径访问已有文件,但两者的原理不同。当访问符号链接时,文件系统读取符号链接中保存的路径,并继续进行解析,最终找到目标文件。而访问硬链接的时候,其直接通过硬链接的目录项访问到目标文件的 inode。
- 符号链接有自己的 inode 结构,有自己的权限、时间等元数据,删除符号链接不会影响目标文件。硬链接不会增加 inode,其与目标文件共享同一个 inode 结构,两者是等价的,没有主次之分,删除其中的任意一个,还可以通过未删除的另一个路径对文件数据进行访问。
- 符号链接与硬链接对目标文件的要求有所差别。在一个符号链接中,用户可以随意存放目标路径,即使这个目标路径不存在。因为只有进行路径解析时,符号链接中的路径才会真正被使用。而对于硬链接,其目标路径在创建硬链接时就会被用于查找 inode,因此无法创建一个指向不存在的文件的硬链接。同时,硬链接还要求目标文件不能为目录。
- 由于对目标文件的要求不同,符号链接不受文件系统边界的限制,即在一个文件系统中,可以创建一个指向其他文件系统的符号链接;而硬链接的目标文件只能与被链接的目标文件处于同一个文件系统中,也就是说硬链接及其目标文件需要在同一个文件系统中。
1.3. 存储布局
为了高效地管理这些文件数据和元数据,文件系统通常将存储空间划分成不同区域,分别用于不同功能。下图展示了一个简单的文件系统存储布局,其中一个存储设备可以被划分为超级块、块分配信息、inode 分配信息、inode 表和文件数据块等区域。
当在一个存储设备上创建一个新的文件系统时(即格式化操作时),文件系统格式化工具会根据文件系统的存储布局和存储设备的容量,计算每个区域的大小,并初始化区域中的元数据。
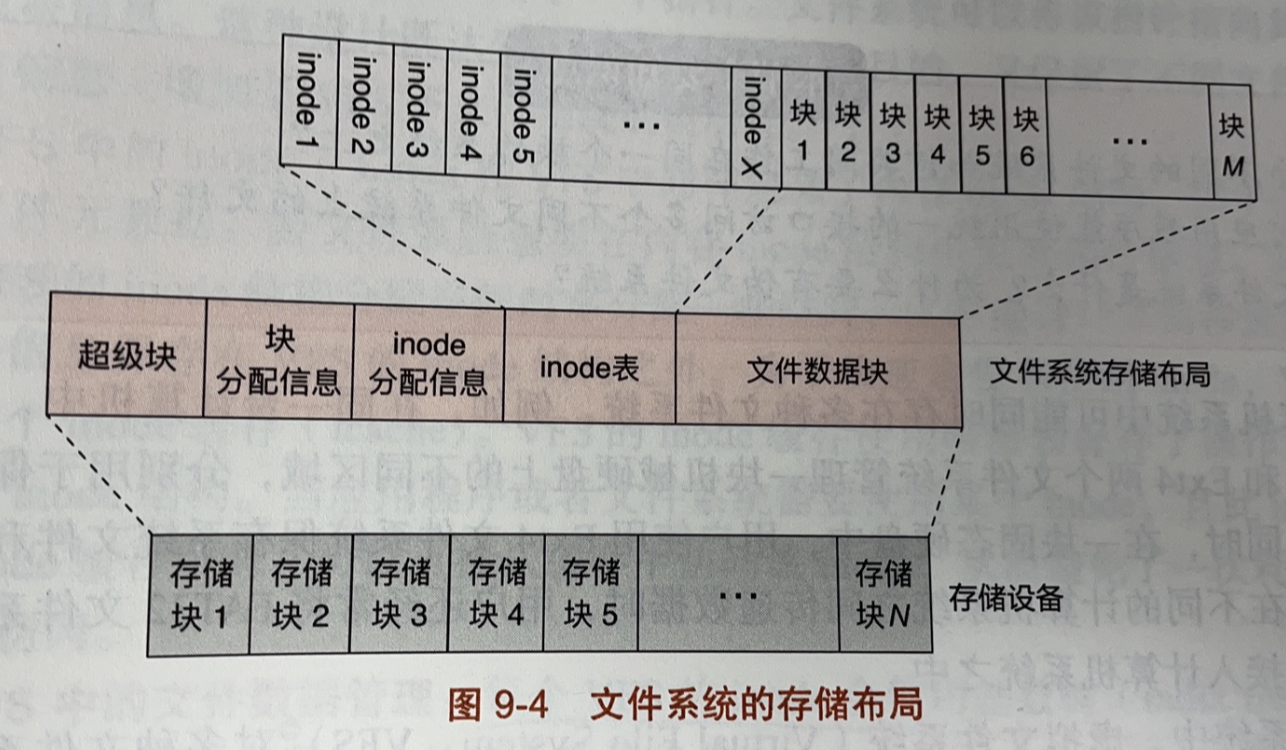
下面对每个区域进行介绍:
- 超级块(super block)是一个文件系统存储布局中必不可少的结构。超级块中记录了整个文件系统的全局元数据。比如
- 魔法数字(magic number),不同的文件系统通常会使用不同的魔法数字,通过读取魔法数字,操作系统可以得知存储设备上文件系统的类型和存储布局;
- 文件系统的版本;
- 文件系统所管理空间的大小;
- 最后一次挂载时间;
- 一些统计信息,包括文件系统能支持的最大 inode 数量、当前空闲可用的 inode 数量、当前空闲可用的 inode 数量、能支持的最大的块数量、当前空闲可用的块数量。
- 块分配信息,使用位图的格式标记文件数据块区域中各个块的使用情况。块分配信息区域中的每个比特位对应文件数据块区域的一个块。若此比特位为 1,则表示对应的数据块已经被分配和使用;若为 0,则表示对应的数据块空闲。
- inode 分配信息与块分配信息类似,区别在于 inode 分配信息记录的是 inode 表中每个 inode 的使用情况。
- inode 表以数组的形式保存了整个文件系统中所有的 inode 结构。文件系统通常使用 inode 号作为此表的索引。因此,文件系统中对 inode 的引用只需要使用 inode 号即可,无须保存 inode 结构在存储设备中的偏移量。此外,由于 inode 表的大小在文件系统创建时就已经固定,因此文件系统能保存的最大文件数量也受此限制。
- 文件数据块区域,用于保存文件的数据。理论上来说,只有文件数据块区域被用来存放应用程序的数据,因此在一个存储设备上创建一个新的文件系统后,文件系统显示的可用大小往往比存储设备的总容量小。
1.4. 巨人的肩膀
- 《现代操作系统原理与实现》-陈海波,夏虞斌

