下面是程序锅在寒假期间根据《现代操作系统原理和实现》做的一个思维导图,完整、详细、清晰的文字版本后头会出,因为自己也想出整一套出来。
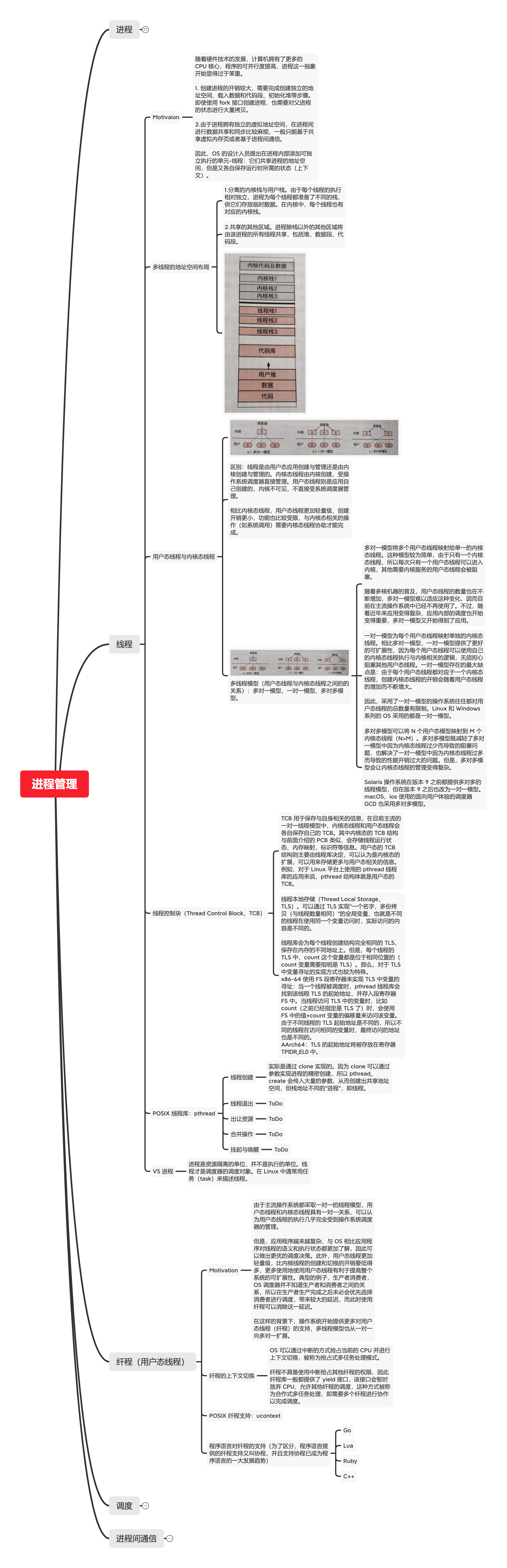
以下内容是由 XMind 根据上述思维导图的内容自动转换而来。
线程
Motivaion
- 随着硬件技术的发展,计算机拥有了更多的 CPU 核心,程序的可并行度提高,进程这一抽象开始显得过于笨重。
- 创建进程的开销较大,需要完成创建独立的地址空间、载入数据和代码段、初始化堆等步骤。即使使用 fork 接口创建进程,也需要对父进程的状态进行大量拷贝。
2.由于进程拥有独立的虚拟地址空间,在进程间进行数据共享和同步比较麻烦,一般只能基于共享虚拟内存页或者基于进程间通信。
因此,OS 的设计人员提出在进程内部添加可独立执行的单元-线程:它们共享进程的地址空间,但是又各自保存运行时所需的状态(上下文)。
多线程的地址空间布局
- 1.分离的内核栈与用户栈。由于每个线程的执行相对独立,进程为每个线程都准备了不同的栈,供它们存放临时数据。在内核中,每个线程也有对应的内核栈。
- 2.共享的其他区域。进程除栈以外的其他区域将由该进程的所有线程共享,包括堆、数据段、代码段。
用户态线程与内核态线程
- 区别:线程是由用户态应用创建与管理还是由内核创建与管理的。内核态线程由内核创建,受操作系统调度器直接管理。用户态线程则是应用自己创建的,内核不可见,不直接受系统调度器管理。
相比内核态线程,用户态线程更加轻量级,创建开销更小,功能也比较受限,与内核态相关的操作(如系统调用)需要内核态线程协助才能完成。
-
多线程模型(用户态线程与内核态线程之间的的关系):多对一模型、一对一模型、多对多模型。
- 多对一模型将多个用户态线程映射给单一的内核态线程。这种模型较为简单,由于只有一个内核态线程,所以每次只有一个用户态线程可以进入内核,其他需要内核服务的用户态线程会被阻塞。
随着多核机器的普及,用户态线程的数量也在不断增加,多对一模型难以适应这种变化,因而目前在主流操作系统中已经不再使用了。不过,随着近年来应用变得复杂,应用内部的调度也开始变得重要,多对一模型又开始得到了应用。
- 一对一模型为每个用户态线程映射单独的内核态线程。相比多对一模型,一对一模型提供了更好的可扩展性,因为每个用户态线程可以使用自己的内核态线程执行与内核相关的逻辑,无须担心阻塞其他用户态线程。一对一模型存在的最大缺点是:由于每个用户态线程都对应于一个内核态线程,创建内核态线程的开销会随着用户态线程的增加而不断增大。
因此,采用了一对一模型的操作系统往往都对用户态线程的总数量有限制。Linux 和 Windows 系列的 OS 采用的都是一对一模型。
- 多对多模型可以将 N 个用户态模型映射到 M 个内核态线程(N>M)。多对多模型既减轻了多对一模型中因为内核态线程过少而导致的阻塞问题,也解决了一对一模型中因为内核态线程过多而导致的性能开销过大的问题。但是,多对多模型会让内核态线程的管理变得复杂。
Solaris 操作系统在版本 9 之前都提供多对多的线程模型,但在版本 9 之后也改为一对一模型。macOS、ios 使用的面向用户体验的调度器 GCD 也采用多对多模型。
线程控制块(Thread Control Block,TCB)
- TCB 用于保存与自身相关的信息,在目前主流的一对一线程模型中,内核态线程和用户态线程会各自保存自己的 TCB。其中内核态的 TCB 结构与前面介绍的 PCB 类似,会存储线程运行状态、内存映射,标识符等信息。用户态的 TCB 结构则主要由线程库决定,可以认为是内核态的扩展,可以用来存储更多与用户态相关的信息。例如,对于 Linux 平台上使用的 pthread 线程库的应用来说,pthread 结构体就是用户态的 TCB。
- 线程本地存储(Thread Local Storage,TLS)。可以通过 TLS 实现“一个名字,多份拷贝(与线程数量相同)”的全局变量,也就是不同的线程在使用同一个变量访问时,实际访问的内容是不同的。
线程库会为每个线程创建结构完全相同的 TLS,保存在内存的不同地址上。但是,每个线程的 TLS 中,count 这个变量都是位于相同位置的(count 变量需要指明是 TLS)。那么,对于 TLS 中变量寻址的实现方式也较为特殊。
x86-64 使用 FS 段寄存器来实现 TLS 中变量的寻址:当一个线程被调度时,pthread 线程库会找到该线程 TLS 的起始地址,并存入段寄存器 FS 中。当线程访问 TLS 中的变量时,比如 count(之前已经指定是 TLS 了)时,会使用 FS 中的值+count 变量的偏移量来访问该变量。由于不同线程的 TLS 起始地址是不同的,所以不同的线程在访问相同的变量时,最终访问的地址也是不同的。
AArch64:TLS 的起始地址将被存放在寄存器 TPIDR_EL0 中。
POSIX 线程库:pthread
-
线程创建
- 实际是通过 clone 实现的。因为 clone 可以通过参数实现进程的精密创建,所以 pthread_create 会传入大量的参数,从而创建出共享地址空间,但栈地址不同的“进程”,即线程。
-
线程退出
- ToDo
-
出让资源
- ToDo
-
合并操作
- ToDo
-
挂起与唤醒
- ToDo
VS 进程
- 进程是资源隔离的单位,并不是执行的单位。线程才是调度器的调度对象。在 Linux 中通常用任务(task)来描述线程。
纤程(用户态线程)
Motivation
- 由于主流操作系统都采取一对一的线程模型,用户态线程和内核态线程具有一对一关系,可以认为用户态线程的执行几乎完全受到操作系统调度器的管理。
但是,应用程序越来越复杂,与 OS 相比应用程序对线程的语义和执行状态都更加了解,因此可以做出更优的调度决策。此外,用户态线程更加轻量级,比内核线程的创建和切换的开销要低得多,更多使用地使用用户态线程有利于提高整个系统的可扩展性。典型的例子,生产者消费者,OS 调度器并不知道生产者和消费者之间的关系,所以在生产者生产完成之后未必会优先选择消费者进行调度,带来较大的延迟,而此时使用纤程可以消除这一延迟。
在这样的背景下,操作系统开始提供更多对用户态线程(纤程)的支持,多线程模型也从一对一向多对一扩展。
纤程的上下文切换
- OS 可以通过中断的方式抢占当前的 CPU 并进行上下文切换,被称为抢占式多任务处理模式。
纤程不具备使用中断抢占其他纤程的权限,因此纤程库一般都提供了 yield 接口,该接口会暂时放弃 CPU,允许其他纤程的调度,这种方式被称为合作式多任务处理,即需要多个纤程进行协作以完成调度。
POSIX 纤程支持:ucontext
程序语言对纤程的支持(为了区分,程序语言提供的纤程支持又叫协程,并且支持协程已成为程序语言的一大发展趋势)
- Go
- Lua
- Ruby
- C++

