下面是程序锅在寒假期间根据《现代操作系统原理和实现》做的一个思维导图,完整、详细、清晰的文字版本后头会出,因为自己也想出整一套出来。
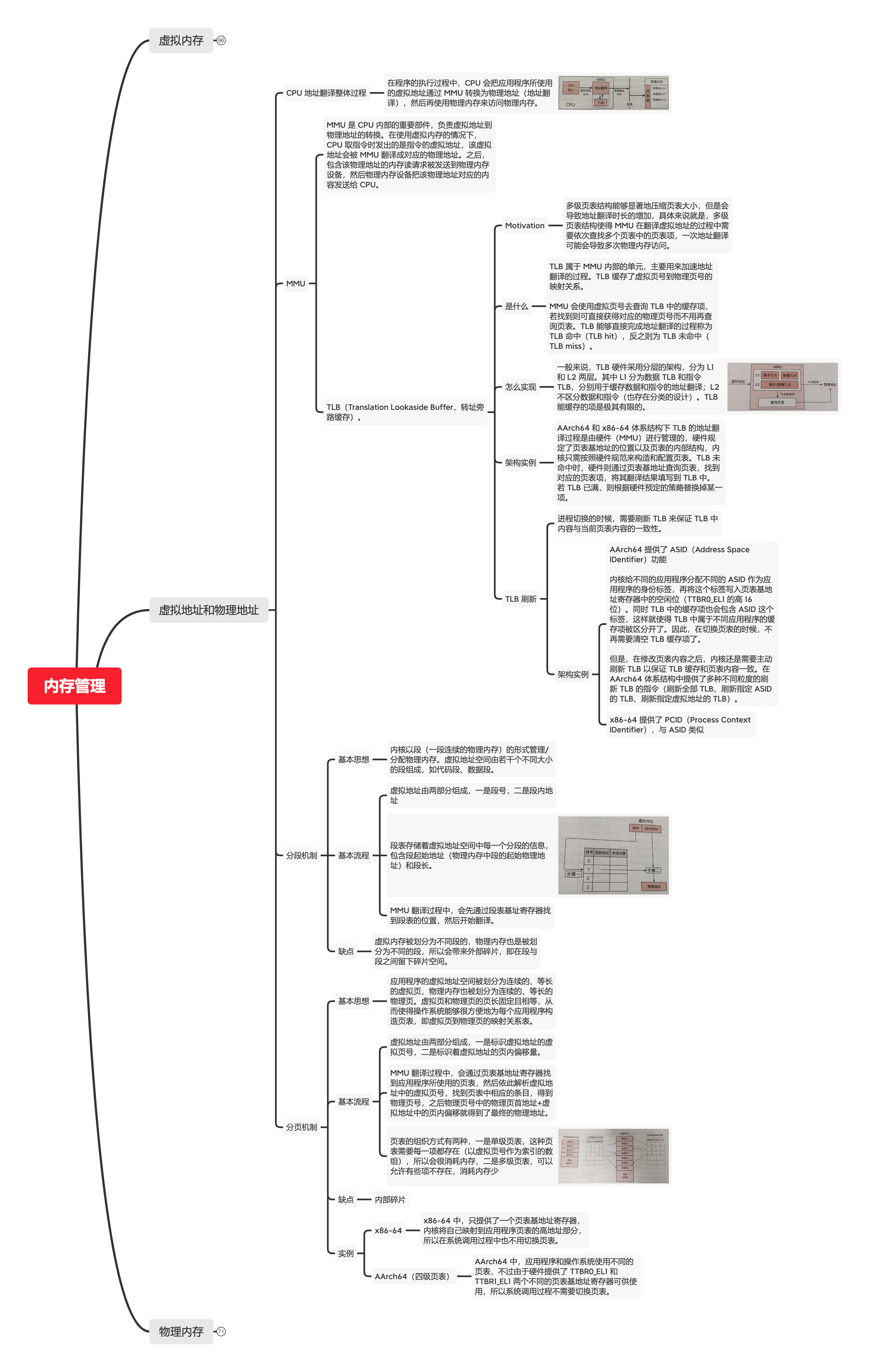
以下内容是由 XMind 根据上述思维导图的内容自动转换而来。
虚拟地址和物理地址
CPU 地址翻译整体过程
- 在程序的执行过程中,CPU 会把应用程序所使用的虚拟地址通过 MMU 转换为物理地址(地址翻译),然后再使用物理内存来访问物理内存。
MMU
-
MMU 是 CPU 内部的重要部件,负责虚拟地址到物理地址的转换。在使用虚拟内存的情况下,CPU 取指令时发出的是指令的虚拟地址,该虚拟地址会被 MMU 翻译成对应的物理地址。之后,包含该物理地址的内存读请求被发送到物理内存设备,然后物理内存设备把该物理地址对应的内容发送给 CPU。
-
TLB(Translation Lookaside Buffer,转址旁路缓存)。
-
Motivation
- 多级页表结构能够显著地压缩页表大小,但是会导致地址翻译时长的增加,具体来说就是,多级页表结构使得 MMU 在翻译虚拟地址的过程中需要依次查找多个页表中的页表项,一次地址翻译可能会导致多次物理内存访问。
-
是什么
- TLB 属于 MMU 内部的单元,主要用来加速地址翻译的过程。TLB 缓存了虚拟页号到物理页号的映射关系。
-
MMU 会使用虚拟页号去查询 TLB 中的缓存项,若找到则可直接获得对应的物理页号而不用再查询页表。TLB 能够直接完成地址翻译的过程称为 TLB 命中(TLB hit),反之则为 TLB 未命中(TLB miss)。
- 怎么实现
- 一般来说,TLB 硬件采用分层的架构,分为 L1 和 L2 两层。其中 L1 分为数据 TLB 和指令 TLB,分别用于缓存数据和指令的地址翻译;L2 不区分数据和指令(也存在分类的设计)。TLB 能缓存的项是极其有限的。
- 架构实例
- AArch64 和 x86-64 体系结构下 TLB 的地址翻译过程是由硬件(MMU)进行管理的,硬件规定了页表基地址的位置以及页表的内部结构,内核只需按照硬件规范来构造和配置页表。TLB 未命中时,硬件则通过页表基地址查询页表,找到对应的页表项,将其翻译结果填写到 TLB 中。若 TLB 已满,则根据硬件预定的策略替换掉某一项。
- TLB 刷新
- 进程切换的时候,需要刷新 TLB 来保证 TLB 中内容与当前页表内容的一致性。
- 架构实例
- AArch64 提供了 ASID(Address Space IDentifier)功能
内核给不同的应用程序分配不同的 ASID 作为应用程序的身份标签,再将这个标签写入页表基地址寄存器中的空闲位(TTBR0_EL1 的高 16 位)。同时 TLB 中的缓存项也会包含 ASID 这个标签,这样就使得 TLB 中属于不同应用程序的缓存项被区分开了。因此,在切换页表的时候,不再需要清空 TLB 缓存项了。
但是,在修改页表内容之后,内核还是需要主动刷新 TLB 以保证 TLB 缓存和页表内容一致。在 AArch64 体系结构中提供了多种不同粒度的刷新 TLB 的指令(刷新全部 TLB、刷新指定 ASID 的 TLB、刷新指定虚拟地址的 TLB)。
- x86-64 提供了 PCID(Process Context IDentifier),与 ASID 类似
分段机制
-
基本思想
- 内核以段(一段连续的物理内存)的形式管理/分配物理内存。虚拟地址空间由若干个不同大小的段组成,如代码段、数据段。
-
基本流程
- 虚拟地址由两部分组成,一是段号,二是段内地址
- 段表存储着虚拟地址空间中每一个分段的信息,包含段起始地址(物理内存中段的起始物理地址)和段长。
- MMU 翻译过程中,会先通过段表基址寄存器找到段表的位置,然后开始翻译。
-
缺点
- 虚拟内存被划分为不同段的,物理内存也是被划分为不同的段,所以会带来外部碎片,即在段与段之间留下碎片空间。
分页机制
-
基本思想
- 应用程序的虚拟地址空间被划分为连续的、等长的虚拟页,物理内存也被划分为连续的、等长的物理页。虚拟页和物理页的页长固定且相等,从而使得操作系统能够很方便地为每个应用程序构造页表,即虚拟页到物理页的映射关系表。
-
基本流程
- 虚拟地址由两部分组成,一是标识虚拟地址的虚拟页号,二是标识着虚拟地址的页内偏移量。
- MMU 翻译过程中,会通过页表基地址寄存器找到应用程序所使用的页表,然后依此解析虚拟地址中的虚拟页号,找到页表中相应的条目,得到物理页号,之后物理页号中的物理页首地址+虚拟地址中的页内偏移就得到了最终的物理地址。
- 页表的组织方式有两种,一是单级页表,这种页表需要每一项都存在(以虚拟页号作为索引的数组),所以会很消耗内存,二是多级页表,可以允许有些项不存在,消耗内存少
-
缺点
- 内部碎片
-
实例
-
x86-64
- x86-64 中,只提供了一个页表基地址寄存器,内核将自己映射到应用程序页表的高地址部分,所以在系统调用过程中也不用切换页表。
-
AArch64(四级页表)
- AArch64 中,应用程序和操作系统使用不同的页表,不过由于硬件提供了 TTBR0_EL1 和 TTBR1_EL1 两个不同的页表基地址寄存器可供使用,所以系统调用过程不需要切换页表。
-

