Google 的 QUIC 协议通过基于 UDP 自定义的类似 TCP 的连接、重试、多路复用、流量控制技术,进一步提升性能。
-
机制一:自定义连接机制
一条 TCP 连接是由四元组标识的,分别是源 IP、源端口、目的 IP、目的端口。一旦一个元素发生变化时,就需要断开重连,重新连接。在移动互联情况下,当手机信号不稳定或者在 WIFI 和 移动网络切换时,都会导致重连,从而进行再次的三次握手,导致一定的时延。这在 TCP 是没有办法的,但是基于 UDP,就可以在 QUIC 自己的逻辑里面维护连接的机制,不再以四元组标识,而是以一个 64 位的随机数作为 ID 来标识,而且 UDP 是无连接的,所以当 IP 或者端口变化的时候,只要 ID 不变,就不需要重新建立连接。
-
机制二:自定义重传机制
前面我们讲过,TCP 为了保证可靠性,通过使用序号和应答机制,来解决顺序问题和丢包问题。任何一个序号的包发过去,都要在一定的时间内得到应答,否则一旦超时,就会重发这个序号的包。那怎么样才算超时呢?还记得我们提过的自适应重传算法吗?这个超时是通过采样往返时间 RTT 不断调整的。
其实,在 TCP 里面超时的采样存在不准确的问题。例如,发送一个包,序号为 100,发现没有返回,于是再发送一个 100,过一阵返回一个 ACK101。这个时候客户端知道这个包肯定收到了,但是往返时间是多少呢?是 ACK 到达的时间减去后一个 100 发送的时间,还是减去前一个 100 发送的时间呢?事实是,第一种算法把时间算短了,第二种算法把时间算长了。
QUIC 也有个序列号,是递增的。任何一个序列号的包只发送一次,下次就要加一了。例如,发送一个包,序号是 100,发现没有返回;再次发送的时候,序号就是 101 了;如果返回的 ACK 100,就是对第一个包的响应。如果返回 ACK 101 就是对第二个包的响应,RTT 计算相对准确。
但是这里有一个问题,就是怎么知道包 100 和包 101 发送的是同样的内容呢?QUIC 定义了一个 offset 概念。QUIC 既然是面向连接的,也就像 TCP 一样,是一个数据流,发送的数据在这个数据流里面有个偏移量 offset,可以通过 offset 查看数据发送到了哪里,这样只要这个 offset 的包没有来,就要重发;如果来了,按照 offset 拼接,还是能够拼成一个流。

-
机制三:无阻塞的多路复用
有了自定义的连接和重传机制,我们就可以解决上面 HTTP 2.0 的多路复用问题。同 HTTP 2.0 一样,同一条 QUIC 连接上可以创建多个 stream,来发送多个 HTTP 请求。但是,QUIC 是基于 UDP 的,一个连接上的多个 stream 之间没有依赖。这样,假如 stream2 丢了一个 UDP 包,后面跟着 stream3 的一个 UDP 包,虽然 stream2 的那个包需要重传,但是 stream3 的包无需等待,就可以发给用户。
-
机制四:自定义流量控制
TCP 的流量控制是通过滑动窗口协议。QUIC 的流量控制也是通过 window_update,来告诉对端它可以接受的字节数。但是 QUIC 的窗口是适应自己的多路复用机制的,不但在一个连接上控制窗口,还在一个连接中的每个 stream 控制窗口。
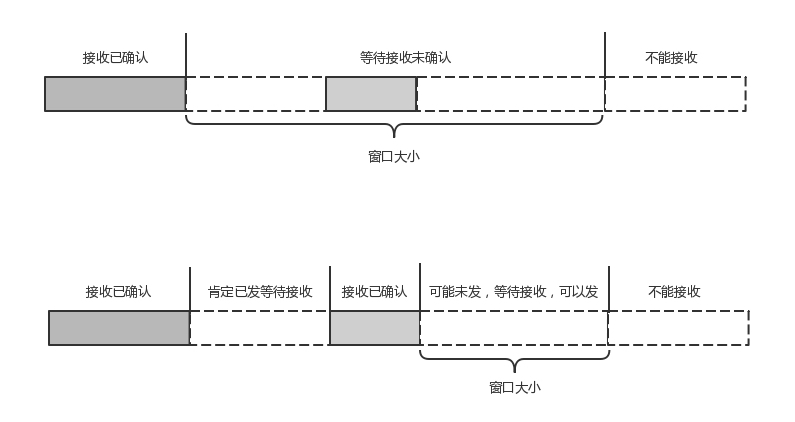
还记得吗?在 TCP 协议中,接收端的窗口的起始点是下一个要接收并且 ACK 的包,即便后来的包都到了,放在缓存里面,窗口也不能右移,因为 TCP 的 ACK 机制是基于序列号的累计应答,一旦 ACK 了一个序列号,就说明前面的都到了,所以只要前面的没到,后面的到了也不能 ACK,就会导致后面的到了,也有可能超时重传,浪费带宽。
QUIC 的 ACK 是基于 offset 的,每个 offset 的包来了,进了缓存,就可以应答,应答后就不会重发,中间的空档会等待到来或者重发即可,而窗口的起始位置为当前收到的最大 offset,从这个 offset 到当前的 stream 所能容纳的最大缓存,是真正的窗口大小。显然,这样更加准确。