1. 梯度下降法的作用
梯度下降法用来求函数的极小值,且是一种迭代算法,由于计算机效率高,在机器学习中经常使用。梯度下降法常求凸函数(如机器学习中各种代价函数)的极小值,因为凸函数只有一个极小值,使用梯度下降法求得的极小值就是最小值。与其对应的有梯度上升法,用来求函数的极大值,两种方法原理一样,只是计算的过程中正负号不同而已。
凸函数的数学定义:某个向量空间的凸子集(区间)上的实值函数,如果在其定义域上的任意两点,有 f(tx + (1-t)y) <= tf(x) + (1-t)f(y),则称其为该区间上的凸函数。
并不是所有的函数都有最小值,我们需要保证是凸函数才有最小值。所以在自己构建的目标函数中,在应用任何算法之前,先确定它是凸函数。
2. 梯度下降法和梯度的介绍
梯度就是表示某一函数在该点处的方向导数沿着该方向取得最大值。这个概念比较抽象,我们拿下山做比较,一个人站在山上的某个山腰处,想要以最快的速度下山,那么该怎么最快下山呢?他只要每次沿着当前位置最陡峭最易下山的方向前进一小步,然后继续沿下一个位置最陡方向前进一小步。这样一步一步走下去,一直走到觉得我们到了山脚的位置。那么下山最陡的方向就是梯度的负方向,这种方法就是梯度下降法。
那怎么求一个函数的梯度呢?那就是这个函数在当前位置的导数。如函数的梯度就是
那么对于如何使用梯度下降算法呢?就是先选择一个初始点,计算该点的梯度,然后按照梯度的方向更新自变量,直到函数的值变化很小或者达到最大迭代次数为止。拿函数举例,若第次迭代值为,那么的梯度下降法的应用就是
其中称为步长或者学习率,表示每次迭代更新变化的大小。直到函数值变化非常小或者达到最大迭代次数时停止,此时认为函数达到极小值点。
3. 梯度下降法的简单应用
求函数
的极小值。该函数的梯度为:
那么根据梯度下降算法的迭代公式:
我们设步长,初始点为。那么梯度算法的核心Python代码如下:
# 求fxy的函数值
def fxy(x, y):
return (x - 10) ** 2 + (y - 10) ** 2
# 梯度下降法
def gradient_descent():
times = 100 # 迭代次数
alpha = 0.05 # 步长
x = 20 # x的初始值
y = 20 # y的初始值
# 梯度下降算法
for i in range(times):
x = x - alpha * 2 * (x - 10)
y = y - alpha * 2 * (y - 10)
f = fxy(x, y)
print("第%d次迭代:x=%f,y=%f,fxy=%f" % (i + 1, x, y, f))
if __name__ == "__main__":
gradient_descent()
输出内容如下(只截取了部分):
第1次迭代:x=19.000000,y=19.000000,fxy=162.000000
第2次迭代:x=18.100000,y=18.100000,fxy=131.220000
第3次迭代:x=17.290000,y=17.290000,fxy=106.288200
...
第92次迭代:x=10.000617,y=10.000617,fxy=0.000001
第93次迭代:x=10.000555,y=10.000555,fxy=0.000001
...
第98次迭代:x=10.000328,y=10.000328,fxy=0.000000
第99次迭代:x=10.000295,y=10.000295,fxy=0.000000
第100次迭代:x=10.000266,y=10.000266,fxy=0.000000
可见迭代到后面得到的是函数的极小值(也是最小值),并且此时自变量的值也知道。为了有一个更加直观的展示,我们对上述代码进行改写,加上画图后的代码如下所示:
import matplotlib.pyplot as plt
import numpy as np
from mpl_toolkits.mplot3d import Axes3D
# 求fxy的函数值
def fxy(x, y):
return (x - 10) ** 2 + (y - 10) ** 2
def gradient_descent():
times = 100 # 迭代次数
alpha = 0.05 # 步长
x = 20 # x的初始值
y = 20 # y的初始值
fig = Axes3D(plt.figure()) # 将figure转化为3D
xp = np.linspace(0, 20, 100)
yp = np.linspace(0, 20, 100)
xp, yp = np.meshgrid(xp, yp) # 将数据转化为网格数据
zp = fxy(xp, yp)
fig.plot_surface(xp, yp, zp, rstride=1, cstride=1, cmap=plt.get_cmap('rainbow'))
# 梯度下降算法
for i in range(times):
xb = x # 用于画图
yb = y # 用于画图
fb = fxy(x, y) # 用于画图
x = x - alpha * 2 * (x - 10)
y = y - alpha * 2 * (y - 10)
f = fxy(x, y)
print("第%d次迭代:x=%f,y=%f,fxy=%f" % (i + 1, x, y, f))
fig.plot([xb, x], [yb, y], [fb, f], 'ko', lw=2, ls='-')
plt.show()
if __name__ == "__main__":
gradient_descent()
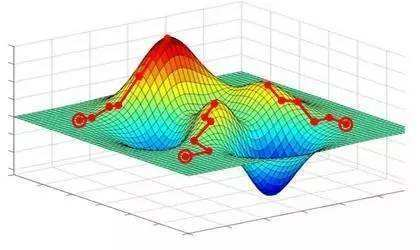
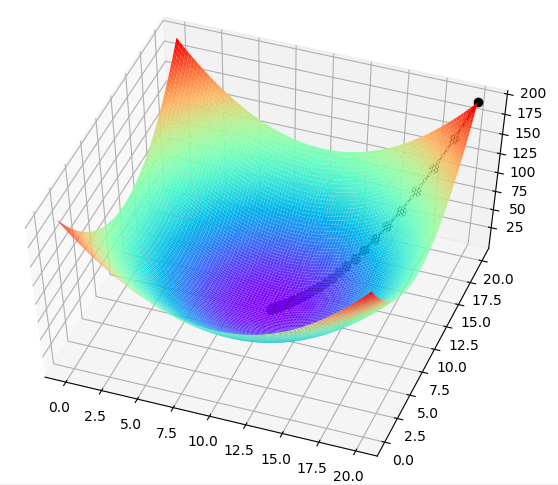
画图的结果如图所示,图中黑色曲线表示梯度下降算法下降时的轨迹
4.梯度下降算法中的超参数
上面提到的,又叫步长,它决定了为了找到极小值点而尝试在目标函数上前进的步伐到底走多大。**步长必须由外界制定,这种需要人为设定的参数,叫超参数。**步长参数 是梯度下降算法中非常重要的超参数。这个参数设置的大小需要合适。
- 步长太大,可能会找不到最低点
- 步长太小,需要的迭代次数多,相应需要的运算时间也就越多
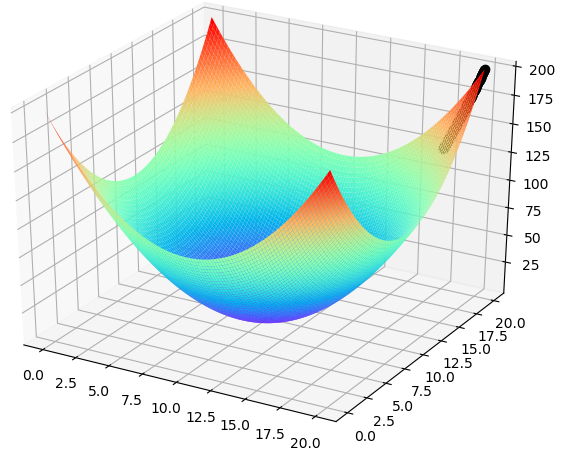
假如把上述简单应用中的步长设为0.001,那么迭代100次之后的结果如下所示,即要达到极小值需要迭代次数超级多:
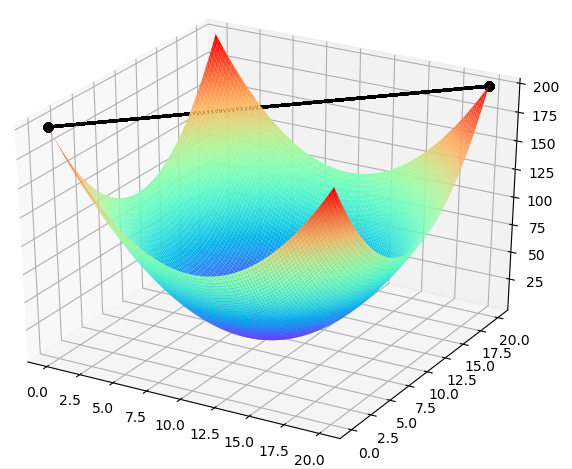
假如把上述的步长设为1,那么结果如下所示,将找不到最低点
所以对于步伐的设置有如下建议:
-
斯坦福的机器学习视频中建议按照[0.001,0.003,0.01,0.03,…]的顺序尝试设置步长,同时观察函数值选择收敛最快的步长。
-
步长也可以设置为非固定值,根据迭代的情况变化。比如可以在一开始的时候先大步走,当所到达点斜率逐渐下降,可以缩小步伐。
对于初始值的设置有如下建议:
- 下降的初始点一般设置为从原点开始
本文参考与推荐

