什么是管道
管道命令使用的是 “|” 这个界定符号。“|” 仅能处理经由前面一个指令传来的正确信息,也就是 standard output 的信息,对于 standard error 并没有直接处理的能力。并且管线后面紧接着的指令必须要能够接受来自前一个指令的数据成为 standard input 继续处理才行。而这样的指令又被称为“管道命令”,例如 less、more、head、tail 等都是可以接受 stdin 的管道命令,而 ls、cp、mv 并不会接受来自 stdin 的数据,因此它们就不是管道命令。
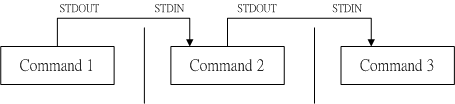
想要 stderr 也可以被管道命令所使用,那么可以通过数据流重导向实现,把 2>&1 加入指令中即可让 2> 变成 1>。
常用管道命令
cut
cut:将同一行里面的数据进行分解,最常使用在分析一些数据或文字数据的时候。
-d :后面接分隔字符。与 -f 一起使用;
-f :依据 -d 的分隔字符将一段讯息分区成为数段,用 -f 取出第几段的意思;
-c :以字符 (characters) 的单位取出固定字符区间;
# 以 : 作为分隔符对 PATH 变量的内容进行切分,并取出第一段的信息
$ echo ${PATH} | cut -d ':' -f 1
$ echo ${PATH} | cut -d ':' -f 1,2 # 取出第 1、2 段的信息
# 取出每一行第 5 个字符及其之后的所有字符
$ last | cut -c 5-
# 取出每一行第 5-10 个字符
$ last | cut -c 5-10
# 这边以一个空格为分隔符,而 last 输出的内容中的第一个字段和第二个字段有多个空格并非仅有一个,所以 cut 无法将第一个字段和第二个字段完美的分割出来。
$ last | cut -d ' ' -f 1,2
grep
xargs 参数代换
xargs:产生某个指令的参数。可以读入 stdin 的数据,并且以空白字符或断行字符作为分隔符,将 stdin 的数据分割成 arguments。当 xargs 后面没有接任何的指令时,默认是以 echo 来进行输出!
xargs [-0epn] command
-0 :如果输入的 stdin 含有特殊字符,例如 `, \, 空白键等等字符时,这个 -0 参数
可以将他还原成一般字符。这个参数可以用于特殊状态喔!
-e :这个是 EOF (end of file) 的意思。后面可以接一个字串,当 xargs 分析到这个字串时,
就会停止继续工作!
-p :在执行每个指令的 argument 时,都会询问使用者的意思;
-n :后面接次数,每次 command 指令执行时,要使用几个参数的意思。
# 查询使用者的 UID/GID 等信息
$ id root
# 错误!$(cmd) 虽然可以获取到参数,但是 id 指令只需要一个参数,而 $() 将会返回 3 个值
$ id $(cut -d ":" -f 1 /etc/passwd | head -n 3)
# 错误!id 并不是管道命令,所以上面的指令执行后,前面的执行结果将会都消失,而只会执行 id
$ cut -d ":" -f 1 /etc/passwd | head -n 3 | id
# 错误!xargs 将所有的数据全都作为 id 的参数了,但是 id 只需要一个参数
$ cut -d ":" -f 1 /etc/passwd | head -n 3 | xargs id
# 这个就正确了,-n 1 处理之后,每次只使用一个参数
$ cut -d ":" -f 1 /etc/passwd | head -n 3 | xargs -n 1 id
# 将 /etc/passwd 内的所有账号都以 id 查询,当查询到 sync 的时候就结束指令,其实 xargs 当遇到 sync 这个字符串之后,就将后面的 stdin 内容舍弃了。需要注意的是,-e'sync' 这之间没有空格。
$ cut -d ":" -f 1 /etc/passwd | xargs -e'sync' -n 1 id
tee 双向重导向
> 会将整个数据流传送给文件或设备,而这些数据流是无办法使用的。但是我们有时候既希望这些数据流存下来,也希望这些数据流可以被下一条指令再次利用起来,那么我们就可以使用 tee。tee 会同时将数据流送去文件或屏幕,而送到屏幕的数据就可以被下一条指令继续处理了。
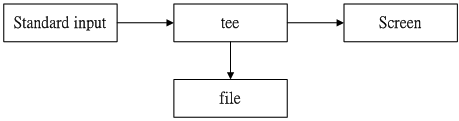
tee [-a] file
-a :以累加 (append) 的方式,将数据加入 file 当中
# 将 last 的输出内容存一份到 last.list 中,同时将内容输出给 cut 这条指令
$ last | tee last.list | cut -d ' ' -f1
split
split:可以将一个大文件依据文件大小或者行数来分区,也就是将大文件分成小文件。
split [-bl] file PREFIX
-b :后面可接欲分区成的文件大小,可加单位,例如 b, k, m 等;
-l :以行数来进行分区。
PREFIX :代表前置字符的意思,可作为分区文件的前导文字
# 将 ../demo.txt 分成 300k 为单位的多个文件,每个文件以 demo 作为文件名的前导文字。
$ split -b 300k ../demo.txt demo
# 将上述分割之后的文件重新合成一个文件,文件名为 demobak
$ cat demo* >> demobak
# 将 ls -al 的输出信息,每 10 行记录成一个文件。
# 需要注意的是这条指令中的 - 是不能缺少的。一般来说,如果需要 stdin/stdout 时,但又没有文件(跟上面进行相比,split 中会将一个文件作为 stdin),而只有 - 的时候,那么这个 - 就会被当作 stdin/stdout(也就说这条指令中的 - 是将 ls -al 的 stdout 作为 split 的 stdin)。
$ ls -al | split -l 10 - lsroot
sort
sort:根据不同的数据型态(数字与文字)来进行排序,并且排序的字符与语系的编码相关,建议使用 LANG=C 来让语系统一。
sort [-fbMnrtuk] [file or stdin]
-f :忽略大小写的差异,例如 A 与 a 视为编码相同;
-b :忽略最前面的空白字符部分;
-M :以月份的名字来排序,例如 JAN, DEC 等等的排序方法;
-n :使用“纯数字”进行排序(默认是以文字体态来排序的);
-r :反向排序;
-u :就是 uniq ,相同的数据中,仅出现一行代表;
-t :分隔符号,默认是用 [tab] 键来分隔;
-k :以那个区间 (field) 来进行排序的意思
# 对账号进行排序,默认是以第一个数据来排序的,而且默认是以文字型态来排序。
$ cat /etc/passwd | sort
# 用 : 进行分割,并且以第 3 栏进行排序,采用纯数字型态进行排序。
$ cat /etc/passwd | sort -t ":" -k 3 -n
# cat /etc/passwd | sort -t ":" -k 3 这条命令会以文字型态使用第三栏来对结果进行排序
uniq
uniq: 将重复的行删除掉只显示一个,由于这个指令是在将重复的行减少,所以需要配合排序过的文件来处理。
uniq [-ic]
-i :忽略大小写字符的不同;
-c :进行计数
# 仅取出账号栏,进行排序后仅取出一位
$ last | cut -d ' ' -f 1 | sort | uniq
# 仅取出账号栏,进行排序后取出一位,但是显示次数
$ last | cut -d ' ' -f 1 | uniq -c
4 root
1
1 wtmp
wc
减号 - 的用途
在管道命令中,常常将前一个指令的 stdout 作为这次的 stdin。比如 tar 会用到文件名称来处理,那么在 tar 时就可以使用 - 来代替 stdin 和 stdout。另外,如果需要 stdout/stdin 的时候,但是这时候又没有文件, 有的只是 - 的时候,那么这个 - 就会当成 stdout/stdin。
# 这是使用 tar 打包的一般步骤
$ tar -cvf demo.tar demo/
# 这是使用 tar 解包的一般步骤
$ tar -xvf demo.tar -C /tmp/demo/
# 这是使用减号 - 之后的。这个例子中是将 demo/ 这个目录里面的文件打包,但是打包的数据不是纪录到文件,而是传送到 stdout;经过管道之后,后面的 - 的表示取用前一个指令的 stdout。
$ tar -cvf - demo/ | tar -xvf - -C /tmp/demo/
个人觉得,减号 - 就可以当成一个匿名参数,当整个管道指令执行完成之后又会把这个匿名参数所代表的内容删掉。
tr
tr:可以用来删除一段信息中的内容,或者进行文字内容的替换。tr 这个指令也可以使用正则表达式,因为它也是由正则表达式的方式来取代数据的。
tr [-ds] ...
-d :删除信息当中 -d 指定的字串;
-s :取代掉重复的字符
# 将 last 输出的信息中的所有小写字符都变成大写字符
$ last | tr '[a-z]' '[A-Z]'
# 将 /etc/passwd 输出的内容中的 : 全都删除
$ cat /etc/passwd | tr -d ':'
col
col:col 有其他特殊的用途,但是很多时候,它可以用来简单将 tab 键取代成为空白键
col [-x]
-x :将 tab 键转换成对等的空白键
# 将 tab 键全都取代成为空白键
cat /etc/man_db.conf | col -x | cat -A | more
expand
expand:将 tab 键转换为空白键
expand [-t] file
-t :后面可以接数字,表示需要取代的空白键数量。一般来说,一个 tab 按键可以用 8 个空白键取代。
# 这是未替换之前,含特殊符号的情况。^I 是指 tab 键
$ grep '^MANPATH' /etc/manpath.config | head -n 3 | cat -A
MANPATH_MAP^I/bin^I^I^I/usr/share/man$
MANPATH_MAP^I/usr/bin^I^I/usr/share/man$
MANPATH_MAP^I/sbin^I^I^I/usr/share/man$
# 下面将 tab 键设置成 6 个空白键。需要注意的是,tab 键最大的功能是格式排列整齐,因此替换成空白键之后的目的也要跟 tab 键一样。所以这个设置并不是简单的替换,空白键会根据我们的定义来增加大小,而不是单纯的一个 ^I 就会转换为 6 个空白键。
$ grep '^MANPATH' /etc/manpath.config | head -n 3 | expand -t 6 - | cat -A
MANPATH_MAP /bin /usr/share/man$
MANPATH_MAP /usr/bin /usr/share/man$
MANPATH_MAP /sbin /usr/share/man$
123456123456123456123456123456123456123456123456
# 下面是 5 个空白键的情况
$ grep '^MANPATH' /etc/manpath.config | head -n 3 | expand -t 5 - | cat -A
MANPATH_MAP /bin /usr/share/man$
MANPATH_MAP /usr/bin /usr/share/man$
MANPATH_MAP /sbin /usr/share/man$
1234512345123451234512345123451234512345
# 下面是 9 个空白键的情况
$ grep '^MANPATH' /etc/manpath.config | head -n 3 | expand -t 9 - | cat -A
MANPATH_MAP /bin /usr/share/man$
MANPATH_MAP /usr/bin /usr/share/man$
MANPATH_MAP /sbin /usr/share/man$
123456789123456789123456789123456789123456789123456789123456789
# 通过上面的 5、6、9 三种情况我们可以发现,假设一个 tab 键是被替换为 9 个空格的话,那么第二个字段结束和第三个字段开始之间的空白字符数量不是简单的 3*9 个,而是在 (18,27] 之间的。也就说 ”(它们中间的字符数+8)/9“ 需要等于 3 。
join
join:处理两个文件,将有两个文件中有相同数据的那一行加一起。需要注意的是,在 join 之前,需要处理的文件要先经过 sort 处理,否则有些比对项目将会被略过。
join [-ti12] file1 file2
-t :join 默认以空白字符分隔数据,并且比对“第一个字段”的数据,
如果两个文件相同,则将两笔数据联成一行,且第一个字段放在第一个!
-i :忽略大小写的差异;
-1 :这个是数字的 1 ,代表“第一个文件要用哪个字段来分析”的意思;
-2 :代表“第二个文件要用哪个字段来分析”的意思。
# 将两个文件第一字段相同的两行整合成一行,第二个文件中的相同字段并不会显示
$ join -t ':' /etc/passwd /etc/shadow | head -n 3
# /etc/passwd 的第四个字段是 GID,/etc/group 的第三个字段是 GID。这条命令的作用是根据 GID 将两个文件整合。同样的,相同的字段部分被移动到最前面,并且第二个文件中的内容就不会再显示了。
$ join -t ':' -1 4 /etc/passwd -2 3 /etc/group | head -n 3
paste
paste:join 是需要比对两个文件的相关性,而 paste 是直接将两行粘贴在一起,且中间以 tab 键隔开。
paste [-d] file1 file2
-d :后面可以接分隔字符。默认是以 [tab] 来分隔的!
- :如果 file 部分写成 - ,表示来自 standard input 的数据的意思
# 将 /etc/passwd 和 /etc/shadow 中的两行粘贴在一起
$ paste /etc/passwd /etc/shadow
# 先将 /etc/group 使用 cat 读出,然后再将其与 /etc/passwd、/etc/shadow 这两个文件进行合并。其实就是将 3 个文件按行进行合并。
$ cat /etc/group | paste /etc/passwd /etc/shadow - | head -n 3

