1. Linux 文件系统介绍
Linux 中一切皆文件,目录只是一种特殊的文件。
1.1. Linux 目录介绍
Linux 下的目录主要遵守 Filesystem Hierarchy Standard(FHS)标准。FHS 的重点在于规范每个特定的目录下应该要放置什么样子的数据。FHS 根据文件系统使用的频繁与否以及是否允许使用者随意更动,将目录定义为四种交互作用的形态,下面的表格列出了一些代表性的目录。
| 可分享的(shareable) | 不可分享的(unshareable) | |
|---|---|---|
| 不变的(static) | /usr (软件放置处) | /etc (配置文件) |
| /opt (第三方协力软件) | /boot (开机与核心档) | |
| 可变动的(variable) | /var/mail (使用者邮件信箱) | /var/run (程序相关) |
| /var/spool/news (新闻群组) | /var/lock (程序相关) |
- 可分享的:可以分享给其他系统挂载使用的目录,所以包括可执行文件与使用者的邮件等数据, 是能够分享给网络上其他主机挂载用的目录;
- 不可分享的:自己机器上面运行的设备文件或者是与程序有关的 socket 文件等, 由于仅与自身机器有关,所以当然就不适合分享给其他主机了。
- 不变的:有些数据是不会经常变动的,跟随着 distribution 而不变动。 例如函数库、文件说明文档、系统管理员所管理的主机服务配置文件等等;
- 可变动的:经常改变的数据,例如登录文件、一般用户可自行收受的新闻群组等。
另外,FHS 针对目录树架构仅定义了三层目录下面应该放置什么数据而已,分别是下面这三个目录的定义:
- / (root, 根目录):与开机系统有关;
- /usr (unix software resource):与软件安装/执行有关;
- /var (variable):与系统运行过程有关。
1.1.1. / 根目录的意义与内容
根目录是整个系统最重要的一个目录,因为不但所有的目录都是由根目录衍生出来的,同时根目录也与开机/还原/系统修复等动作有关。所以根目录除包含开机时需要特定的开机软件、核心文件、开机所需程序、函数库等文件数据之外,还需要包含能够修复文件系统的程序才行(以防系统出现错误)。但是,FHS 希望根目录不要放在非常大的分区内,且应用程序所安装的软件最好不要与根目录放在同一个分区内,保持根目录越小越好。 如此不但性能较佳,根目录所在的文件系统也较不容易发生问题,因为越大的分区你会放入越多的数据,如此一来根目录所在分区就可能会有较多发生错误的机会。
FHS 定义出根目录下面要有下面这些次目录的存在才好,即使没有实体目录,希望至少有链接文件存在才好:
| 目录 | 应放置文件内容 |
|---|---|
| 第一部份:FHS 要求必须要存在的目录 | |
| /bin | 系统有很多放置可执行文件的目录,但 /bin 比较特殊。因为 /bin 放置的是在单人维护模式下还能够被操作的指令。 在 /bin 下面的指令可以被 root 与一般帐号所使用,主要有:cat, chmod, chown, date, mv, mkdir, cp, bash 等等常用的指令。 |
| /boot | 这个目录主要在放置开机会使用到的文件,包括 Linux 核心文件以及开机菜单与开机所需配置文件等等。 Linux kernel 常用的文件名为:vmlinuz,如果使用的是 grub2 这个开机管理程序, 则还会存在 /boot/grub2/ 这个目录喔! |
| /dev | 在 Linux 系统上,任何设备与周边设备都是以文件的型态存在于这个目录当中的。 你只要通过存取这个目录下面的某个文件,就等于存取某个设备。比要重要的文件有 /dev/null, /dev/zero, /dev/tty, /dev/loop, /dev/sd 等等 |
| /etc | 系统主要的配置文件几乎都放置在这个目录内,例如人员的帐号密码档、 各种服务的启始档等等。一般来说,这个目录下的各文件属性是可以让一般使用者查阅的, 但是只有 root 有权力修改。FHS建议不要放置可执行文件(binary)在这个目录中。比较重要的文件有: /etc/modprobe.d/, /etc/passwd, /etc/fstab, /etc/issue 等等。另外 FHS 还规范几个重要的目录最好要存在 /etc/ 目录下:/etc/opt(必要):这个目录在放置第三方协力软件 /opt 的相关配置文件 /etc/X11/(建议):与 X Window 有关的各种配置文件都在这里,尤其是 xorg.conf 这个 X Server 的配置文件。 /etc/sgml/(建议):与 SGML 格式有关的各项配置文件 /etc/xml/(建议):与 XML 格式有关的各项配置文件 |
| /lib | 系统的函数库非常的多,而 /lib 放置的则是在开机时会用到的函数库, 以及在/bin或/sbin下面的指令会调用的函数库而已。 什么是函数库呢?你可以将他想成是“外挂”,某些指令必须要有这些“外挂”才能够顺利完成程序的执行之意。 另外 FSH 还要求下面的目录必须要存在:/lib/modules/:这个目录主要放置可抽换式的核心相关模块(驱动程序)! |
| /media | media 是“媒体”的英文,顾名思义,这个 /media 下面放置的就是可移除的设备! 包括软盘、光盘、DVD等等设备都暂时挂载于此。常见的文件名有:/media/floppy, /media/cdrom 等等。 |
| /mnt | 如果你想要暂时挂载某些额外的设备,一般建议你可以放置到这个目录中。 在古早时候,这个目录的用途与/media相同啦!只是有了/media之后,这个目录就用来暂时挂载用了。 |
| /opt | 这个是给第三方协力软件放置的目录。什么是第三方协力软件啊? 举例来说,KDE 这个桌面管理系统是一个独立的计划,不过他可以安装到 Linux 系统中,因此 KDE 的软件就建议放置到此目录下了。 另外,如果你想要自行安装额外的软件(非原本的distribution提供的),那么也能够将你的软件安装到这里来。 不过,以前的 Linux 系统中,我们还是习惯放置在 /usr/local 目录下呢! |
| /run | 早期的 FHS 规定系统开机后所产生的各项信息应该要放置到 /var/run 目录下,新版的 FHS 则规范到 /run 下面。 由于 /run 可以使用内存来仿真,因此性能上会好很多! |
| /sbin | Linux 有非常多指令是用来设置系统环境的,这些指令只有 root 才能够利用来“设置”系统,其他使用者最多只能用来“查询”而已。 放在 /sbin 下面的为开机过程中所需要的,里面包括了开机、修复、还原系统所需要的指令。 至于某些服务器软件程序,一般则放置到 /usr/sbin/ 当中。至于本机自行安装的软件所产生的系统可执行文件(system binary), 则放置到 /usr/local/sbin/ 当中了。常见的指令包括:fdisk, fsck, ifconfig, mkfs等等。 |
| /srv | srv 可以视为“service”的缩写,是一些网络服务启动之后,这些服务所需要取用的数据目录。 常见的服务例如 WWW, FTP 等等。举例来说,WWW 服务器需要的网页数据就可以放置在 /srv/www/ 里面。 不过,系统的服务数据如果尚未要提供给网际网络任何人浏览的话,默认还是建议放置到 /var/lib 下面即可。 |
| /tmp | 这是让一般使用者或者是正在执行的程序暂时放置文件的地方。 这个目录是任何人都能够存取的,所以你需要定期的清理一下。当然,重要数据不可放置在此目录啊! 因为 FHS 甚至建议在开机时,应该要将 /tmp 下的数据都删除唷! |
| /usr | 第二层 FHS 设置,后续介绍 |
| /var | 第二曾 FHS 设置,主要为放置变动性的数据,后续介绍 |
| 第二部份:FHS 建议可以存在的目录 | |
| /home | 这是系统默认的使用者主文件夹(home directory)。在你新增一个一般使用者帐号时, 默认的使用者主文件夹都会规范到这里来。比较重要的是,主文件夹有两种代号喔:~:代表目前这个使用者的主文件夹;~dmtsai :则代表 dmtsai 的主文件夹! |
| /lib<qual> | 用来存放与 /lib 不同的格式的二进制函数库,例如支持 64 位的 /lib64 函数库等 |
| /root | 系统管理员(root)的主文件夹。之所以放在这里,是因为如果进入单人维护模式而仅挂载根目录时, 该目录就能够拥有root的主文件夹,所以我们会希望 root 的主文件夹与根目录放置在同一个分区中。 |
除此之外,Linux 下面还有以下这些目录。
| 目录 | 应放置文件内容 |
|---|---|
| /lost+found | 这个目录是使用标准的 ext2/ext3/ext4 文件系统格式才会产生的一个目录,目的在于当文件系统发生错误时, 将一些遗失的片段放置到这个目录下。不过如果使用的是 xfs 文件系统的话,就不会存在这个目录了! |
| /proc | 这个目录本身是一个“虚拟文件系统(virtual filesystem)”!他放置的数据都是在内存当中, 例如系统核心、进程信息(process)、周边设备的状态及网络状态等等。因为这个目录下的数据都是在内存当中, 所以本身不占任何硬盘空间啊!比较重要的文件例如:/proc/cpuinfo, /proc/dma, /proc/interrupts, /proc/ioports, /proc/net/ 等等。 |
| /sys | 这个目录其实跟 /proc 非常类似,也是一个虚拟的文件系统,主要也是记录核心与系统硬件信息较相关的信息。 包括目前已载入的核心模块与核心侦测到的硬件设备信息等等。这个目录同样不占硬盘容量喔! |
1.1.2. /usr 的意义与内容
根据 FHS 的基本定义,/usr 里面放置的数据属于可分享与不可变动的。/usr 确定可以通过网络进行分区的挂载,从而将 /usr 的内容分享给区域网络内的其他主机来使用。usr 是 Unix Software Resource 的缩写,所以 FHS 建议所有软件开发者,应该将他们的数据合理的分别放置到这个目录下的次目录,而不要自行创建该软件自己独立的目录。所有系统默认的软件(distribution发布者提供的软件)都会放置到/usr下面,因此这个目录有点类似 Windows 系统的“C:\Windows\ (当中的一部份) + C:\Program files\” 这两个目录的综合体,系统刚安装完毕时,这个目录会占用最多的硬盘容量。一般来说,/usr的次目录建议有下面这些:
| 目录 | 应放置文件内容 |
|---|---|
| 第一部份:FHS 要求必须要存在的目录 | |
| /usr/bin/ | 所有一般用户能够使用的指令都放在这里!目前新的 CentOS 7 已经将全部的使用者指令放置于此,而使用链接文件的方式将 /bin 链接至此! 也就是说, /usr/bin 与 /bin 是一模一样了!另外,FHS 要求在此目录下不应该有子目录! |
| /usr/lib/ | 基本上,与 /lib 功能相同,所以 /lib 就是链接到此目录中的! |
| /usr/local/ | 系统管理员在本机自行安装自己下载的软件(非distribution默认提供者),建议安装到此目录, 这样会比较便于管理。举例来说,你的distribution提供的软件较旧,你想安装较新的软件但又不想移除旧版, 此时你可以将新版软件安装于/usr/local/目录下,可与原先的旧版软件有分别啦! 你可以自行到/usr/local去看看,该目录下也是具有 bin, etc, include, lib... 的次目录喔! |
| /usr/sbin/ | 非系统正常运行所需要的系统指令。最常见的就是某些网络服务器软件的服务指令(daemon)啰!不过基本功能与 /sbin 也差不多, 因此目前 /sbin 就是链接到此目录中的。 |
| /usr/share/ | 主要放置只读架构的数据文件,当然也包括共享文件。在这个目录下放置的数据几乎是不分硬件架构均可读取的数据, 因为几乎都是文字文件嘛!在此目录下常见的还有这些次目录:/usr/share/man:线上说明文档 /usr/share/doc:软件杂项的文件说明 /usr/share/zoneinfo:与时区有关的时区文件 |
| 第二部份:FHS 建议可以存在的目录 | |
| /usr/games/ | 与游戏比较相关的数据放置处 |
| /usr/include/ | c/c++ 等程序语言的文件开始(header)与包含档(include)放置处,当我们以 tarball 方式 (*.tar.gz 的方式安装软件)安装某些数据时,会使用到里头的许多包含档喔! |
| /usr/libexec/ | 某些不被一般使用者惯用的可执行文件或脚本(script)等等,都会放置在此目录中。例如大部分的 X 窗口下面的操作指令, 很多都是放在此目录下的。 |
| /usr/lib<qual>/ | 与 /lib<qual>/ 功能相同,因此目前 /lib<qual> 就是链接到此目录中 |
| /usr/src/ | 一般源代码建议放置到这里,src 有 source 的意思。至于核心源代码则建议放置到 /usr/src/linux/ 目录下。 |
1.1.3. /var 的意义与内容
如果说 /usr 是安装时会占用较大硬盘容量的目录,那么 /var 就是在系统运行后才会渐渐占用硬盘容量的目录。/var 目录主要针对常态性变动的文件,包括高速缓存(cache)、登录文件(log file)以及某些软件运行所产生的文件, 包括程序文件(lock file, run file),或者例如 MySQL 数据库的文件等等。常见的次目录有:
| 目录 | 应放置文件内容 |
|---|---|
| 第一部份:FHS 要求必须要存在的目录 | |
| /var/cache/ | 应用程序本身运行过程中会产生的一些暂存盘; |
| /var/lib/ | 程序本身执行的过程中,需要使用到的数据文件放置的目录。在此目录下各自的软件应该要有各自的目录。 举例来说,MySQL的数据库放置到 /var/lib/mysql/ 而 rpm 的数据库则放到 /var/lib/rpm 去! |
| /var/lock/ | 某些设备或者文件资源一次只能被一个应用程序所使用,如果同时有两个程序使用该设备时, 就可能产生一些错误的状况,因此就得要将该设备上锁(lock),以确保该设备只会给单一软件所使用。 举例来说,烧录机正在烧录一块光盘,你想一下,会不会有两个人同时在使用一个烧录机烧片? 如果两个人同时烧录,那片子写入的是谁的数据?所以当第一个人在烧录时该烧录机就会被上锁, 第二个人就得要该设备被解除锁定(就是前一个人用完了)才能够继续使用啰。目前此目录也已经挪到 /run/lock 中! |
| /var/log/ | 重要到不行!这是登录文件放置的目录!里面比较重要的文件如 /var/log/messages, /var/log/wtmp(记录登陆者的信息)等。 |
| /var/mail/ | 放置个人电子邮件信箱的目录,不过这个目录也被放置到 /var/spool/mail/ 目录中! 通常这两个目录是互为链接文件啦! |
| /var/run/ | 某些程序或者是服务启动后,会将他们的 PID 放置在这个目录下喔!至于 PID 的意义我们会在后续章节提到的。 与 /run 相同,这个目录链接到 /run 去了! |
| /var/spool/ | 这个目录通常放置一些伫列数据,所谓的“伫列”就是排队等待其他程序使用的数据啦! 这些数据被使用后通常都会被删除。举例来说,系统收到新信会放置到 /var/spool/mail/中, 但使用者收下该信件后该封信原则上就会被删除。信件如果暂时寄不出去会被放到 /var/spool/mqueue/ 中, 等到被送出后就被删除。如果是工作调度数据(crontab),就会被放置到 /var/spool/cron/ 目录中! |
1.1.4. Linux 目录树导图

1.2. Linux 文件属性
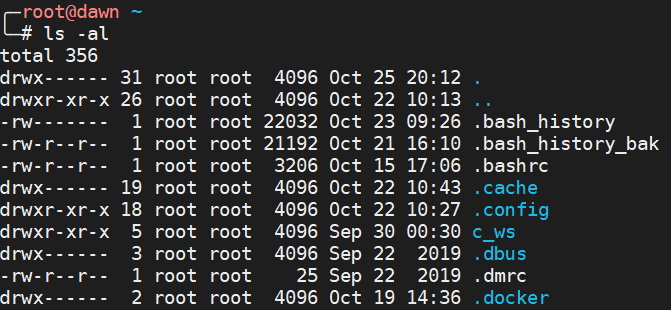
通过 ls -al 命令,我们可以看到 root 目录的部分情况如上图所示。那么下面对上述显示的信息进行讲解。
1.2.1. 第一栏代表这个文件的类型和权限
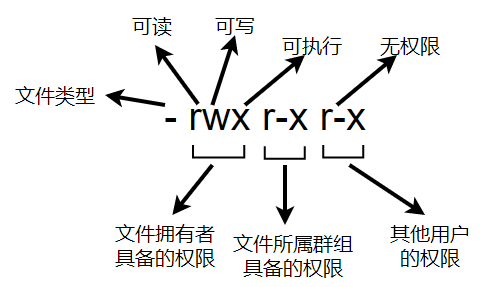
-
第一个字符代表这个文件的类型,比如“目录、文件或链接文件等等”:
当为[d]则是⽬录;
当为[-]则是普通⽂件;
若是[l]则表⽰为链接文件(link file);
若是[b]则表⽰为装置⽂件⾥⾯的可供储存的接⼝设备(可随机存取装置);
若是[c]则表⽰为装置⽂件⾥⾯的串⾏端⼝设备,例如键盘、⿏标(⼀次性读取装置);
若是[s]则表⽰为套接接⼝⽂件;
若是[p]则表⽰为管道。
-
接下去的字符中,三个为一组,分别表示“文件拥有者具备的权限”、“文件所属群组具备的权限(是指加入该群组的用户对该文件具备的权限)”、“其他用户的权限”。每组的顺序都是 rwx(位置是不会改变的),假如显示 r 则表示具有 read 权限,假如不具有 read 权限,那么则用 - 表示。另外,rwx 这三种权限对于文件和目录来说是不一样的。
对于文件来说,文件是实际包含数据的地方,包括一般文本文件、数据库内容档、二进制可执行文件等等。因此对于文件来说,rwx 的权限是这样的:
- r:可读取此文件的实际内容
- w:可编辑、新增或者修改文件的内容(但不含删除该文件,因为 rwx 只是针对文件内容而言)
- x:该文件具有可以被系统执行的权限。在 Linux 下一个文件是否被执行,是看这个文件是否具有 x 权限来决定的,而不是由文件名决定的(windows 下的一个文件是否具有执行能力是由扩展名决定的)。
对于目录来说,目录主要的内容是记录文件名清单、文件名与目录。那么针对目录来说,rwx 的权限是这样的:
-
r:表示具有读取目录结构清单的权限,也就是可以查看该目录下的文件名数据。
-
w:具有改动该目录结构清单的权限,也就是下面这些权限:创建新的文件与目录;删除已经存在的文件与目录(不论该文件的权限如何);更名已存在的文件或目录;搬移该目录内的文件、目录位置。
总之,w 的权限对于目录来说就是与目录的结构改变有关。
-
x:代表能否进入该目录成为工作目录。
总的来说,对于文件而言,rwx 是针对文件的内容来设计权限;对于目录来说,rwx 则是对目录内的文件名列表来设计权限。
内容 r w x 文件 详细数据 data 读文件内容 修改文件内容 执行文件内容 目录 文件名 读文件名 修改文件名 进入该目录的权限(key) 假如一个目录没有 r 的话,使用 tab 键的时候,无法自动补齐文件名了。
拷贝 A 目录中的一个文件到 B 目录中时,A 目录也需要有 x 权限。通常要开放的目录,至少会具备 rx 这两个权限。
1.2.2. 第二栏表示有多少个文件名链接到此节点(i-node)
每个文件都会将它的权限与属性记录到文件系统的 i-node 中。但是,我们使用的目录树都是使用文件名来记录的,因为每个文件名会链接到一个 i-node 上。而这个属性记录的,就是有多少个不同的文件名会链接到相同的一个 i-node 上去。
1.2.3. 第三栏表示这个文件(或目录)的拥有者账号名称
1.2.4. 第四栏表示这个文件的所属群组
在 Linux 系统中,你的账号会加入一个或多个群组中。假如你的账号加入了一个群组,那么你对属于这个群组的文件或者目录具有相应的权限,由第二组所表示。
1.2.5. 第五栏为这个文件的容量大小,默认单位为 Bytes
1.2.6. 第六栏为这个文件的创建日期或者最近修改的日期
这一栏的内容显示日期(月/日)及时间,如果这个文件被修改的时间距离现在太久了,那么会仅显示年份而已。
如果想要显示完整的时间格式,那么可以使用
ls -l --full-time。
1.2.7. 第七栏为这个文件的文件名
如果文件之前多了一个 . ,则表示这个文件为隐藏文件,那么 ls 默认情况下是不会显示隐藏文件的。
1.3. Linux 文件种类与扩展名
Linux 中一切皆文件,目录只是一种特殊的文件,连数据沟通的接口也有专属的文件。下面对 Linux 文件种类进行了一波整理。
1.3.1. 文件种类
- 正规文件(regular file ): 就是一般我们在进行存取的类型的文件,在由 ls -al 所显示出来的属性方面,第一个属性为 [-]。照文件的内容,又大略可以分为:
- 纯文本文件(ASCII):这是 Linux 文件系统中最多的一种文件类型,称为纯文本文件是因为内容为我们人类可以直接读到的数据,例如数字、字母等等。
- 二进制文件(binary):Linux 当中的可执行文件就是这种格式(script 不算),比如 cat。
- 数据格式文件(data):有些程序在运行的过程中会读取某些特定格式的文件,那些特定格式的文件可以被称为数据文件。比如 Linux 在使用者登陆时都会将登陆的数据记录在 /var/log/wtmp 这个文件内,该文件是一个 data file,他能够通过 last 这个指令读出来,但是当使用 cat 查看这个文件内容时又会出现乱码(毕竟人家是一种特殊格式的文件)。
- 目录(directory):就是目录,第一个属性是 [d]
- 链接文件(link):第一个属性为 [l],这种就类似于 Windows 系统下的快捷链接。
- 设备与设备文件(device):与系统周边及储存等相关的一些文件, 通常都集中在 /dev 这个目录之下!设备文件是我们系统中很重要的文件,最好不要随意修改。它通常又分为两种:
- 块设备文件(block):就是一些储存数据, 以提供系统随机存取的周边设备,举例来说,硬盘与软盘等就是啦! 你可以随机的在硬盘的不同区块读写,这种设备就是块设备。第一个属性是 [b],比如 /dev/sda。
- 字符设备文件(character):亦即是一些 Serial port 的周边设备, 例如键盘、鼠标等等!这些设备的特色就是“一次性读取”的,不能够截断输出。比如,你不能让鼠标跳到另一个画面,而是连续滑到另一个地方。第一个属性是 [c]。
- 数据接口文件(sockets):这种类型的文件通常被用在网络上的数据承接。我们可以启动一个程序来监听用户端的要求,而用户端可以通过这个 socket 来进行数据的沟通。第一个属性是 [s],通常在 /run 或者 /tmp 这个目录中看到这种文件类型。
- 数据输送档(FIFO(first-in-first-out)、pipe):FIFO 也是一种特殊的文件类型,主要目的就是解决多个进程同时存取一个文件所造成的错误问题。第一个属性是 [p]。
1.3.2. Linux 文件扩展名
基本上,Linux 的文件是没有所谓的“扩展名”的。但是,我们仍然希望可以借助扩展名来了解文件是什么东西。因此,我们通常还是会以适当的扩展名来表示该文件是什么种类。比如,
- *.sh:脚本或批处理文件(script),因为批处理文件为使用 shell 写成的,所以扩展名就编成了 .sh 。
- *Z,* .tar, *.tar.gz,* .zip, *.tgz: 经过打包的压缩文件。这是因为压缩软件分别为 gunzip, tar 等等的,由于不同的压缩软件,而取其相关的扩展名。
- *.html,* .php:网页相关文件。
但是,Linux 系统上的文件名真的只是让你了解该文件可能的用途而已, 真正的执行与否仍然需要权限的规范才行!例如虽然有一个文件为可执行文件,但是如果这个文件的权限被修改成无法执行时, 那么ls就变成不能执行!
权限发生改变通常发生在文件传送过程中。例如你在网络上下载一个可执行文件,但是在你的 Linux 系统中就是无法执行!那么就是可能文件的属性被改变了!因为,从网络上传送到你的 Linux 系统中,文件的属性与权限确实是会被改变的!
1.3.3. Linux 文件长度限制
在 Linux 下面,使用传统的 Ext2/Ext3/Ext4 文件系统以及近来被 CentOS 7 当作默认文件系统的 xfs 而言,针对文件的文件名长度限制为:
单一文件或目录的最大容许文件名为 255Bytes,以一个 ASCII 英文占用一个 Bytes 来说,则大约可达 255 个字符长度。若是以每个中文字占用 2Bytes 来说, 最大文件名就是大约在 128 个中文字。
1.3.4. Linux 文件名称的限制
在设置 Linux 下面的文件名称时,最好可以避免一些特殊字符比较好!例如下面这些,因为下面这些符号在命令行下会有特殊意义,假如被当成文件名之后,那么会有可能被解释为命令行的参数等。另外,最好也避免文件名以 - 或 + 开头来命名,因为会使用 -option 之类的选项。
? > < ; & ! [ ] | \ ' " ` ( ) { }
2. 命令集合
2.1. 文件/目录属性修改
chgrp:改变文件所属群组,change group。要改变之后的群组名必须在 /etc/grouo 这个文件中存在才行,否则会出现错误。
chgrp [-R] dirname|filename
-R:进行递回(recursive)的持续变更,亦即连同次目录下的所有文件、目录都更新成为这个群组之意。常常用在变更某一目录内所有的文件之情况。
# 将 initial-setup-ks.cfg 这个文件所属群组改为 user。注意:user 这个群组必须在 /etc/group 这个文件中。
chgrp user initial-setup-ks.cfg
chown:改变文件拥有者,change owner。同样,改变之后的用户名必须在 /etc/passwd 这个文件中有记录的。除此之外,chown 还可以修改群组的名称。
chown [-R] 帐号名称 文件或目录
chown [-R] 帐号名称:群组名称 文件或目录
-R : 进行递回(recursive)的持续变更,亦即连同次目录下的所有文件都变更。
# 将 initial-setup-ks.cfg 这个文件的拥有者改为 bin 这个账号
chown bin initial-setup-ks.cfg
# 将 initial-setup-ks.cfg 这个文件的拥有者与群组全都改为 root 这个账号
chown root:root initial-setup-ks.cfg
附:
1.改变群组或者拥有者的一个应用场景就是在复制文件给别人的时候。
chmod:改变文件的权限,SUID、SGID、SBIT 等等。权限的设置方法有两种,一种是数字,另一种是符号。
#### 数字方式进行设置
Linux 文件的基本权限就 9 个,分别是 owner/group/others 三种身份各有自己的 read/write/execute 权限。上面提到这三种权限的顺序是:rwx,那么对应的数字如下所示:
r---4(100)
w---2(010)
x---1(001)
那么,每种身份各自的三个权限对应的数字需要累加。假如想要将一个文件对应的权限分别是:rwxr-x---。由于 owner 这个身份拥有 rwx 权限,所以最终分数就是 4+2+1=7。同理,group 这个身份拥有 r-x 权限,所以最终分数就是 4+1=5;others 这个身份拥有 --- 权限,所以最终分数是 0。那么以数字方式进行设置的时候,则需要以 750 这个数字进行设置。
chmod [-R] xyz 文件|目录
xyz:就是刚刚提到的数字类型的权限属性
-R:进行递归的持续变更,亦同次目录下的所有文件都会变更
#### 符号方式进行设置
chmod u(user)|g(group)|o(others)|a(all) +(加入)|-(除去)|=(设置) r|w|x 文件|目录
# 将 user 设置成可读、可写、可执行;group 和 others 设置成可读可执行
chmod u=rwx,go=rx .bashrc
# user、group、others 这三种身份都加上 x 权限(可执行权限)。
chmod a+x .bashrc
2.2. 更改、查看、创建、删除目录
cd:改变当前的工作目录。Change Directory 的缩写,这是用来变换工作目录的指令
cd /var/spool/mail # 绝对路径
cd ../postfix # 相对路径
cd # 不跟任何也是回到当前用户的 home 目录
cd ~ # 进入当前用户的 home 目录,root 用户就是 /root/
cd - # 回到之前的目录
附:
用户登入之后的默认工作目录是该用户的 home 目录。
pwd:显示当前所处的目录
tree:以树状图列出目录的内容
tree [-L] [目录...]
-L level 限制目录显示层级
mkdir:建立一个新的目录
mkdir [-mp] 目录名称
-m :直接配置目录的权限!直接设定,不需要看预设权限 (umask) 的脸色~
-p :帮助你直接将所需要的目录(包含上层目录)递归建立起来!
mkdir -m 711 test2
mkdir -p /home/bird/testing/test1 # 假如不存在 /home, /home/bird, /home/bird/testing 目录的话,那么需要 -p 参数,-p 会依序的建立起这些目录
附:
1.如果没有加上 -m 来强制设定属性,系统会使用默认属性。
2.如你要建立一个目录为 /home/bird/testing/test1,那么首先必须要有 /home 然后 /home/bird ,再来 /home/bird/testing 都必须要存在,才可以建立/home/bird/testing/test1 这个目录!假如没有 /home/bird/testing 时,就没有办法建立 test1 的目录。
3.如果该目录本来就已经存在时,系统也不会显示错误讯息喔。
rmdir:删除一个空的目录
rmdir [-p] 目录名称
-p :连同『上层』『空的』目录也一起删除
2.3. 文件整体
2.3.1. 查看文件信息
ls:显⽰指定⼯作⽬录下的内容
ls [-alhrtAFR] [name]
-a 显⽰所有⽂件及⽬录 (ls内定将⽂件名或⽬录名称开头为"."的视为隐藏档,不会列出)
-l 除⽂件名称外,亦将⽂件型态、权限、拥有者、⽂件⼤⼩等资讯详细列出
-h 文件的大小以可读的方式显示出来,比如 1K、234M(需要和 -l 联合使用)
-r 将⽂件以相反次序显⽰(原定依英⽂字⺟次序)
-t 将⽂件依建⽴时间之先后次序列出
-A 同 -a ,但不列出 "." (⽬前⽬录) 及 ".." (⽗⽬录)
-F 在列出的⽂件名称后加⼀符号;例如可执⾏档则加 "*", ⽬录则加 "/"
-R 若⽬录下有⽂件,则以下之⽂件亦皆依序列出
附:
有些 Linux 发行版中有时会有 ll 命令,这个命令其实是 ls -lh 的一个别名,alias ll='ls -lh'
file:⽤于辨识⽂件类型。file 命令对文件的检查分为文件系统、魔法幻数检查和语言检查 3 个过程。
file [-bcLz][-f <名称⽂件>][-m <魔法数字⽂件>...][⽂件或⽬录...](文件或目录可以多个,多个文件使用空格分开,也可以使用通配符)
-b 列出辨识结果时,不显示文件名称;
-c 详细显示指令执行过程,便于排错或分析程序执行的情形;
-L 直接显示符号连接所指向的文件类别;
-z 尝试去解读压缩文件的内容;
-f<名称文件> 指定名称文件,其内容有一个或多个文件名称时,让file依序辨识这些文件,格式为每列一个文件名称;
-m<魔法数字⽂件> 指定魔法数字⽂件;
type:用来显示指定命令的类型,判断给出的指令是内部指令还是外部指令。
-t:输出 “file”、“alias” 或者 “builtin”,分别表示给定的指令为“外部指令”、“命令别名”或者“内部指令”;
-p:如果给出的指令为外部指令,则显示其绝对路径;
-a:在环境变量“PATH”指定的路径中,显示给定指令的信息,包括命令别名。
命令类型:
alias:别名。
keyword:关键字,Shell保留字。
function:函数,Shell函数。
builtin:内建命令,Shell内建命令。
file:文件,磁盘文件,外部命令。
unfound:没有找到。
ldd:用于打印程序或者库文件所依赖的共享库列表
-v:详细信息模式,打印所有相关信息;
-u:打印未使用的直接依赖;
-d:执行重定位和报告任何丢失的对象;
-r:执行数据对象和函数的重定位,并且报告任何丢失的对象和函数;
附:
1.ldd 不是一个可执行程序,而只是一个shell脚本。
2.ldd 能够显示可执行模块的 dependency,其原理是通过设置一系列的环境变量,如下:LD_TRACE_LOADED_OBJECTS、LD_WARN、LD_BIND_NOW、LD_LIBRARY_VERSION、LD_VERBOSE 等。当LD_TRACE_LOADED_OBJECTS 环境变量不为空时,任何可执行程序在运行时,它都会只显示模块的 dependency,而程序并不真正执行。
3.ldd 显示可执行模块的 dependency 的工作原理,其实质是通过 ld-linux.so(elf动态库的装载器)来实现的。我们知道,ld-linux.so 模块会先于 executable 模块程序工作,并获得控制权,因此当上述的那些环境变量被设置时,ld-linux.so 选择了显示可执行模块的dependency。 实际上可以直接执行 ld-linux.so模块,如:/lib/ld-linux.so.2 --list program(这相当于ldd program)
2.3.2. 复制、删除、移动创建文件
cp:主要⽤于复制⽂件或⽬录
cp [options] source dest
-r:若给出的源⽂件是⼀个⽬录⽂件,此时将复制该⽬录下所有的⼦⽬录和⽂件
-f:覆盖已经存在的⽬标⽂件⽽不给出提⽰
-i:与-f选项相反,在覆盖⽬标⽂件之前给出提⽰,要求⽤⼾确认是否覆盖,回答"y"时⽬标⽂件将被覆盖
-a:此选项通常在复制⽬录时使⽤,它保留链接、⽂件属性,并复制⽬录下的所有内容
-d:复制时保留链接
-p:除复制⽂件的内容外,还把修改时间和访问权限也复制到新⽂件中
-l:不复制⽂件,只是⽣成链接⽂件
rm:删除⼀个⽂件或者⽬录
rm [options] name
-i 删除前逐⼀询问确认。
-f 即使原档案属性设为唯读,亦直接删除,⽆需逐⼀确认。
-r 将⽬录及以下之档案亦逐⼀删除。
mv:⽤来为⽂件或⽬录改名、或将⽂件或⽬录移⼊其它位置
mv [options] source dest
mv [options] source... directory
mv 文件名 文件名 # 将源文件名改为目标文件名
mv 文件名 目录名 # 将源文件移到目标目录
mv 目录名 目录名 # 目标目录已存在,将源目录移到目标目录;目标目录不存在就是改名
-i 若指定目录已有同名文件,则先询问是否覆盖旧文件
-f 在 mv 操作要覆盖某已有的目标文件时不给任何提示
touch:文件存在的话,则会修改⽂件或者⽬录的时间属性,包括存取时间和更改时间。若文件不存在,系统会建⽴⼀个新的⽂件
touch testfile # testfile 存在就修改⽂件"testfile"的时间属性为当前系统时间
touch file # file 不存在就创建
2.3.3. 查找文件
find:递归查找文件
find [PATH] [option] [action]
PATH 可以是多个目录
-mtime n:在 n 天之前的一天之内被更改过的文件(也就是第 n 天之前的那一天),即 4-5 天那一天的文件文件名
-mtime +n:在 n 天之前(不包含 n 天本身)被更改过内容的文件,大于等于 n + 1 前的文件文件名
-mtime -n:在 n 天之内(包 n 天本身)被更改过内容的文件,小于等于 n 天内的文件文件名
-atime
-ctime
-newer file:file 是一个存在的文件,列出比 file 还要新的文件文件名
-uid n:n 是使用者的账号 ID,即 UID 是记录在 /etc/passwd 里面与账号名称对应的数字
-gid n:n 是群组名称的 ID,即 GID
-user name:name 为使用账号名称
-group name:name 为群组名称
-nouser:寻找文件的拥有者不存在 /etc/passwd
-nogroup :寻找文件的拥有群组不存在于 /etc/group
# nouser 和 nogroup 除了自行从网络下载文件时会发生之外。如果你将系统里面的某个账号删除了,但是该账号已经在系统内创建了很多文件时,此时就可以使用 nouser 找出来。
-name filename:搜寻文件名称为 filename 的文件(包括目录,这个是匹配的是文件名而不是路径),-name 默认是大小写字母敏感的,-i 可以忽略大小写。
-regex "[正则表达式]":使用正则表达式的方式查询,但是 -regex 不是匹配文件名而是完整的文件名(包括路径)
-size [+-]SIZE:搜寻比 SIZE 还要大(+)或小(-)的文件。这个 SIZE 的规则有:C-代表 Byte;K-代表 1024 Bytes。比如要找比 50KB 还要大的文件,就是 -size +50K
-type TYPE:搜寻文件的类型为 TYPE 的,类型主要有:一般正规文件(f),设备文件(b、c),目录(d),链接文件(l),socket(s)及 FIFO(p)等属性。
-perm mode:搜寻文件权限“刚好等于” mode 的文件,这个 mode 为类似 chmod 的属性。
-perm -mode:搜寻文件权限“必须要全部囊括 mode”的文件,举例来说,我们必须要搜寻 -rwxr--r-- ,也就是 0744 的文件。那么,一个文件的权限是 -rwsr-xr-x,也就是 4755 的文件也会被列出来。因为 -rwsr-xr-x 已经囊括了 -rwxr--r-- 的属性了。
-perm /mode:搜寻文件权限“包含任一 mode 的权限”的文件,比如 -perm /755,也就是搜寻 -rwxr-xr-x,但一个文件的属性为 -rw------- 也会被列出来,因为有 -rw- 的属性在。
-exec command:command 为其他指令,-exec 后面可再接额外的指令来处理搜寻到的结果
-print:将结果打印到屏幕上,这个动作是默认动作
find / -mtime 0 # 系统上面 24 小时之内有改动过的文件列出,0 代表目前的时间,所以从现在开始到 24 小时前
find / -mtime 3 # 3 天前的 24 小时内
find /home -user dawn # 查看 /home 下面属于 dawn 的文件
find / -nouser # 搜索系统中不属于任何人的文件,这个可以轻易找出那些不太正常的文件。如果有找到不属于系统任何人的文件时,不要慌张,这些是正常的。尤其在以源代码自行编译软件的时候。
find / -name passwd # 找出文件名为 passwd 的文件(这个相当于文件名为 test 的,包括目录和文件)
find / -name '*passwd*' # 找出文件名包含了 passwd 这个关键字的文件(包括目录)
find /run -type s # 找出 /run 目录下,文件类型为 socket 的文件
find / -perm /7000 # 所谓 7000 就是 ---s--s--t,那么只要含有 s 或 t 属性的文件就会列出。-perm -7000 表示要同时含有 ---s--s--t 的所有三个权限的文件。
find /usr/bin /usr/sbin -perm /7000 -exec ls -l {} \;
# 将 find 找到的文件用 ls -l 显示出来。{} 代表的是“由 find 找到的内容”,也就是 find 的结果会被放置到 {} 位置中;-exec 一直到 \; 是关键字,代表 -exec 动作的开始到结束(\;)。
# 需要注意的是,-exec 后面的指令是不支持别名的,比如不能使用 ll
附加:
1. find 还可以利用通配符来寻找文件名,比如上面的 find / -name "*passwd*"
2. find 是去磁盘或者硬盘上查找数据,所以查找数据的时候磁盘操作会很多,所以一般情况下可使用 whereis 和 locate
which:寻找可执行文件
which [-a] 文件名
此时会输出该文件名的 alias 信息(如果有的话)和所在的路径。
-a 将所有的由 PATH 目录中可以找到的指令均列出,不止第一个被找到的指令名称。
附加:
which 指令是根据 PATH 这个环境变量所规范的路径,去搜索可执行文件。
whereis:只找系统中某些特定目录下面的文件而已。
whereis [-bmsu][-B <⽬录>...][-M <⽬录>...][-S <⽬录>...][文件或目录名]
-l 列出 whereis 会去查询的几个主要目录
-b 只找 binary 格式的文件
-m 只找在说明文档 manual 路径下的文件
-s 只找 source 来源文件
-u 查找不在上述三个项目当中的其他特殊文件
-B<⽬录> 只在设置的⽬录下查找⼆进制⽂件
-M<⽬录> 只在设置的⽬录下查找说明⽂件
-S<⽬录> 只在设置的⽬录下查找原始代码⽂件
附:
find 命令是直接搜索磁盘的,而 whereis 是指找几个特定的目录而已,并没有全系统去查,所以 whereis 的速度很快。但是,由于查找的目录有限,因此会存在找不到的情况。要想知道 whereis 查找的是哪些目录下的,可以使用 -l 参数。
locate:利用数据库来搜寻文件名。在完整文件名中(包含路径名称)当中,如果包含了 keyword 的内容,那么就会被显示出来。
locate [options] keyword
-i 忽略大小写的差异
-c 不输出文件名,仅计算找到的文件数量
-l 仅输出几行, -l 5 就表示只输出 5 行
-S 输出 locate 所使用的数据库文件的相关信息,包括该数据库纪录的文件/目录数量
-r 后面可接正则表达式的显示方式,正则表达式是用单引号
-d或--database= 配置 locate 指令使用的数据库
附:
locate 在寻找数据的时候是在已创建的数据库 /var/lib/mlocate 中查找的,而不是去磁盘查找的。数据库的创建默认是在每天执行一次(每个 distribution 都不同),所以当你去搜索你新创建的文件时,locate 会告诉你找不到。
这个时候,就需要更新数据库。使用 updatedb 即可更新数据库,这个指令会去读取 /etc/updatadb.conf 这个配置文件的设置,然后再去硬盘里面进行搜索,最后更新整个数据库文件。
2.4. 文件内容查看、比较
cat:由第一行开始显示文件内容 用于连接文件并打印到标准输出设备上
cat [-AbeEnstT] fileName
-n 或 --number:由 1 开始对所有输出的行数编号。
-b 或 --number-nonblank:和 -n 相似,只不过对于空白行不编号。
-s 或 --squeeze-blank:当遇到有连续两行以上的空白行,就代换为一行的空白行。
-v 或 --show-nonprinting:使用 ^ 和 M 符号,除了 LFD 和 TAB 之外。
-E 或 --show-ends : 在每行结束处显示 $。
-T 或 --show-tabs: 将 TAB 字符显示为 ^I。
-A, --show-all:等价于 -vET。
-e:等价于"-vE"选项;
-t:等价于"-vT"选项;
cat -n textfile1 > textfile2 # 把 textfile1 的文档内容加上行号后输入 textfile2 这个文档里
cat -b textfile1 textfile2 > textfile3 # 把 textfile1 和 textfile2 的文档内容加上行号(空白行不加)之后将内容附加到 textfile3 文档里
cat /dev/null > /etc/test.txt # 清空 /etc/test.txt 文档内容
cat /dev/fd0 > OUTFILE # cat 也可以用来制作镜像文件。例如要制作软盘的镜像文件,将软盘放好后输入
cat IMG_FILE > /dev/fd0 # 相反的,如果想把 image file 写到软盘,输入
more:一页一页的显示文件内容,只能向后
less:less 与 more 类似, 但是比 more 更好的是,less 可以往前翻页
less demo.log # 查看文件
less demo1.log demo2.log # 查看多个文件
ps -elf | less # ps 查看进程信息并通过 less 分页显示
附:
1. 先输入数字 n,再按 <Enter> 键,表示向下 n 行。默认情况为 1 行(less、more)
2. <Space> 向下滚动一屏(less、more)
3. q 退出 more(less、more)
4. = 输出当前行号(less、more)
5. !命令调用 shell(less、more)
6. ctrl + F 往后一屏(less、more会跳过一行)
ctrl + B 往前一屏(less)
ctrl + D 往后半屏(less、more)
ctrl + U 往前半屏(less)
7. j - 向前移动一行 (less)
k - 向后移动一行(less)
8. G - 移动到最后一行 (less)
g - 移动到第一行(less)
head: 用于显示文件的开头的内容。在默认情况下,显示文件的头 10 行内容。如果指定了多于一个文件,在每一段输出前会给出文件名作为文件头。如果不指定文件,或者文件为"-",则从标准输入读取数据。
head [选项] [文件]...
-n, --lines=[-]K # 显示每个文件的前 K 行内容;如果附加"-"参数,则除了每个文件的最后 K 行外显示剩余全部内容
-c, --bytes=[-]K # 显示每个文件的前K 字节内容;如果附加"-"参数,则除了每个文件的最后K字节数据外显示剩余全部内容
-q, --quiet, --silent # 不显示包含给定文件名的文件头
-v, --verbose # 总是显示包含给定文件名的文件头
head -5 demo # 显示文件的前 5 行
head -n 5 demo # 显示文件的前 5 行
head -n -5 demo # 显示除文件最后 5 行外的内容
附:
K 后面可以跟使用这些单位:b 512, kB 1000, K 1024, MB 1000*1000, M 1024*1024, GB 1000*1000*1000, G 1024*1024*1024, 对于T, P, E, Z, Y 同样适用。
tail:用于输入文件中的尾部内容。tail命令默认在屏幕上显示指定文件的末尾 10 行。如果给定的文件不止一个,则在显示的每个文件前面加一个文件名标题。如果没有指定文件或者文件名为“-”,则读取标准输入。
tail [选项] [文件]
-n, --lines=k # 输出最后的 k 行,若使用-n +k 从第 k 行开始输出
-c, --bytes=k # 输出最后 k 字节。另外,使用-c +K 从第 k 字节输出
-q, --quiet, --silent # 不输出给出文件名的头
-v, --verbose # 总是输出文件名的头
-f # 即时输出文件变化后追加的数据
-pid=PID # 与 -f 合用,表示在进程 PID 死掉结束之后使用
tail -f notes.log # 此命令显示 notes.log 文件的最后 10 行。当将某些行添加至 notes.log 文件时,tail 命令会继续显示这些行。 显示一直继续,直到您按下(Ctrl-C)组合键停止显示。
附:
1. 有一个常用的参数 -f 常用于查阅正在改变的日志文件。tail -f filename 会把 filename 文件里的最尾部的内容显示在屏幕上,并且不断刷新,只要 filename 更新就可以看到最新的文件内容。
2. 如果字节数或行数 K 的第一个字符是"+",输出从文件开始第 K 个项目,否则输出文件最后 K 个项目。K 可以使用一下几种单位之一:b 512,kB 1000,K 1024,MB 1000*1000,M 1024*1024,GB 1000*1000*1000,G 1024*1024*1024,以及T,P,E,Z,Y。
diff:用在比对两个文件之间的差异的, 并且是以行为单位来比对的。一般是用在 ASCII 纯文本 档的比对上。由于是以行为比对的单位, 因此 diff 通常是用在同一的文件(或软件)的新旧版本差异上。
diff [-bBi] from-file to-file
-b 忽略一行当中,仅有多个空白的差异
-B 忽略空白行的差异
-i 忽略大小写的差异
from-file 作为原始比对文件的档名(可以是目录)
to-file 作为目的比对文件的档名(可以是目录)
附加:
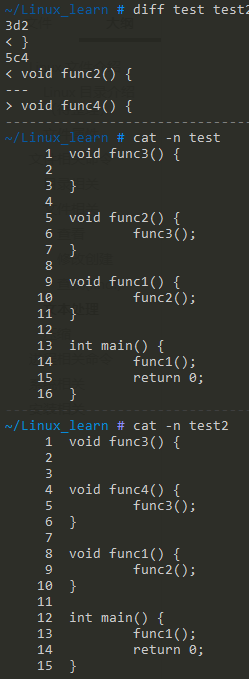
如下图所示,diff 是很智能的:
- 3d2 表示 test 中的第 3 行被删掉了,基准是 test2 中的第 2 行,删除的内容也列出来。个人理解就是左边的第 3 行被删除了,删除之后变成了第 2 行。
- 5c4 表示 test 中的第 5 行改成了右边的第 4 行的内容。
2.5. 文件内容处理
wc:计算文件内容
wc [-lwmc]
-l:仅列出行数;
-w:仅列出多少字(英文单字);
-m:多少字符;
-c:只显示Bytes数;
wc -l test # 计算 test 这个文件的行数
cat test | wc -l # 计算 test 这个文件的行数
附加:
输出的内容分别代表:行树、字数、字符数
grep:进行字符串数据的比较,然后将符合用户需求的字符串打印出来。grep 在数据中查找一个字符串时,是以整行为单位进行数据的选取的。grep 会分析一行讯息,如果当中有我们所需要的信息,就将这一行显示出来。
grep [-acinv] [-A] [-B] [--color=auto] '搜寻字串' filename
搜寻字串:可以使用基本的正则表达式
filename:可以多个
-A:后面可加数字,为 after 的意思,也就是除匹配的那行显示出来之外,后续的 n 行也显示出来
-B: 与 -A 类似,只是取前面的 n 行
-a:将 binary 文件以 text 文件的方式搜寻数据
-c:计算找到 '搜寻字串' 的次数
-i:忽略字符大小写的差别
-n:输出行号
-v:反向选择,也就是显示出没有'搜寻字串'内容的那一行
--color=auto:将找到的关键字部分加上颜色的显示
# last 中有出现 root 的那一行取出来
last | grep 'root'
# last 中没有出现 root 的那一行取出来
last | grep -v 'root'
# 取出 /etc/man.config 中含 MANPATH 的那几行
grep --color=auto 'MANPATH' /etc/man.config
# 将关键字所在的前两行和后三行也一起显示出来,同时显示行号
dmesg | grep -n -A3 -B2 'eth'
grep -n 't[ae]st' regular_express.txt
# 下面这两条命令是同样的意思
grep '[^a-z]oo' regular_express.txt
grep '[^[:lower:]]' regular_express.txt
# 查找以 the 为开头的行
grep '^the' regular_express.txt
# 查找以小数点为结尾的那一行,由于小数点是特殊字符,所以小数点需要进行转义,也就是使用(\)
grep '\.$' regular_express.txt
# 查找空白行
grep '^$' regular_express.txt
# 统计当前目录及其子目录下的所有文件包含非空白行的行数
grep -c '[^^$]' * # 这个时候 ^ 放在 [] 里头和外头差别不大
grep -c '[^$]' *
# 找到 g...g 的情况(以 g 为开头,以 g 为结尾的内容)
grep 'g.*g' regular_express.txt
# 找到任意数字的行,比如 “7834 test” 就需要找出 7834
grep '[0-9][0-9]*' regular_express.txt
# 找到含两个 o 的字符串,由于 {} 在 shell 中是有特殊的意义,所以需要使用转义字符(\)
grep 'o\{2\}' regular_express.txt
# 找到 g 后面接 2 到 5 个 o,然后再接一个 g 的
grep 'go\{2,5\}g' regular_express.txt
# 找到 g 后面至少接 2 个 o,并且最后再是一个 g 的
grep 'go\{2,\}g' regular_express.txt
# 后面的是通配符,也就是在 doc、txt、pptx、docx 结尾的文件中找 chapter 的行
grep –n 'chapter' {*.doc, *.txt, *.pptx, *.docx}
附:
1. grep 标准的 grep 命令,支持正则表达式
2. egrep 扩展的 grep 命令,支持基本和扩展正则表达式
3. fgrep 快速的 grep 命令,不支持正则表达式,按照字符串的字面意思进行匹配
sed:sed 是一个非交互式文本编辑器,可对文本文件和标准输入进行编辑,标准输入可以来自键盘输入、文件重定向、字符串、变量和管道的文本。sed 可以将数据进行替换、删除、新增、选取特定行等功能。
sed [-nefr] '动作'
-n:使用安静(silent)模式。在一般 sed 的用法中,所有来自 STDIN 的数据都会被列出在屏幕上。但是加上 -n 参数后,只有经过 sed 特殊处理的那一行(或操作)才会被列出来
-e:直接在命令行模式上进行 sed 的动作编辑
-f:直接将 sed 的动作写在一个文件内,-f filename 则可以执行 filename 内的 sed 动作。
-r:sed 的动作支持的是扩展型正则表达式的语法(默认是基础正则表达式语法)
-i:直接修改读取的文件内容,而不是由屏幕输出
动作说明:
n1[,n2] function(动作,必须要以两个单引号括住):对指定行进行操作(n2 没有就表示 n1 这一行,n1 和 n2 都没有表示全部),一般代表选择进行动作的行数,比如 10,20 [动作行为] 表示我的动作需要在 10 到 20 行之间进行。
/pattern/ function:对包含 pattern 的行进行操作,pattern 支持正则,但是对大小写敏感。
/pattern/pattern/ function:对包含两个 pattern 的行进行操作
/pattern/,n2 function:从 pattern 匹配的行到 n2 行之间的行进行操作
n1,/pattern/ function:从 n1 号当 pattern 匹配的行进行操作
n1[,n2]! function:对除 n1 到 n2 行之外的行进行操作(n2 没有则表示除 n1 外的行)
function:直接 function 也是可以的,表示全部的内容
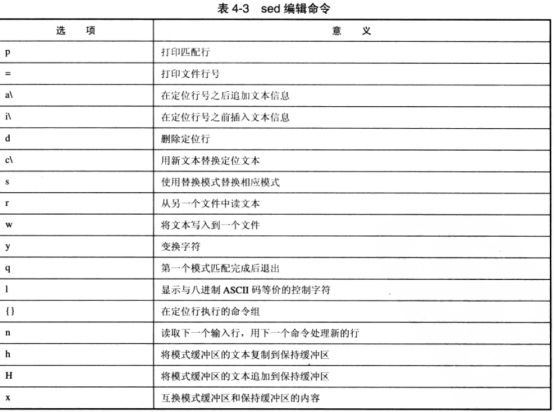
function 有以下这些参数(这边只列出个人觉得常用的,详细地见图):
a:新增,a 的后面可以接字符串,而这些字符串会在新的一行出现(目前的下一行)。
i:插入,i 后面可接字符串,而这些字符串会在新的一行出现(目前的上一行)。
c:替换,c 的后面可以接字符串,这些字符串可以替换 n1,n2 之间的行。
s:替换,可以直接进行替换的工作,使用方式为:sed 's/要被替换的字符串/新的字符串/[n[g]]'。
s 的动作可以搭配正则表达式。这个跟 c 的区别在于,c 是整行,而这个可以是一行中的某段内容。
g 表示把一行中所有匹配的词都被替换为指定单词。在没有 g 的时候,某行的第 1 处匹配并替换之后,就跳转到下 一匹配行。
n 还可以表示替换第几次匹配到的内容。
s 后面还可以跟一个操作哦!
d:删除,后面一般不接参数。
p:打印,也就是将某个选择的数据打印出来,p 通常与 sed -n 一起使用。
=:打印匹配的行号
r:后面跟 filename,表示添加 filename 中内容,如 sed -n '/library/r output' glib.h。
w:表示将取到的内容重定向到 filename 这个文件中,如 sed -n 's/library/hhh/w output' glib.h。
{}:将多个命令组合在一起运行,有先后顺序,用分号隔开。
# 输出 2-5 行的内容,注意添加 -n 参数
cat -n regular_express.txt | sed -n '2,5p'
# 输出的内容中,第 2-5 行被删除了。原本要跟 -e,但是没有 -e 也行
cat -n regular_express.txt | sed '2,5d'
# 删除第 2 行到最后一行,$在sed命令中代表最后一行
cat -n regular_express.txt | sed '2,$d'
# 对输出内容中的空白行进行删除
cat regular_express.txt | sed '/^$/d'
# 在第二行后面加上 drink tea 这一行
cat -n regular_express.txt | sed '2a drink tea'
# 想要添加多行,那么在输入要添加的第一行内容之后,先不要用 ' 结束,而是添加 \,然后输出新的内容。当还想添加第 3 行,那么在最后添加 \,而不是 '。以此类推。
cat -n regular_express.txt | sed '2a drink tea or ......\
pipe quote> drink beer?\
pipe quote> hello world'
# 在第二行前面加上 drink tea 这一行
cat -n regular_express.txt | sed '2i drink tea'
# 将 2-5 行的内容替换为 No 2-5 Number
cat -n regular_express.txt | sed '2,5c No 2-5 Number'
# 下面演示 sed 的替换功能,主要就是只显示 eno1 网卡的 IP 地址
$ ifconfig eno1 | grep 'inet addr'
inet addr:172.16.1.73 Bcast:172.16.1.255 Mask:255.255.255.0
$ ifconfig eno1 | grep 'inet addr' | sed 's/^.*addr://g'
172.16.1.73 Bcast:172.16.1.255 Mask:255.255.255.0
$ ifconfig eno1 | grep 'inet addr' | sed 's/^.*addr://g' | sed 's/Bcast.*//g'
172.16.1.73
# 将 regular_express.txt 内每一行结尾为 . 替换为 !。注意这个操作是直接修改 regular_express.txt 这个文件的内容。
sed -i 's/\.$/\!/g' regular_express.txt
# 替换之后并输出
sed -n 's/library/hhh/gp' glib.h
# 将第二次匹配到的内容进行替换并输出
sed -n 's/library/hhh/2p' glib.h
# 将替换的结果输出到 output 文件中
sed -n 's/library/hhh/w output' glib.h
# 将符合模式的行号打印出来
sed –n '/library/=' glib.h
# 将符合模式的行内容和行号打印出来
sed –n –e '/library/p' –e '/library/=' glib.h
# 等价于: sed -n '/apple/{p;=}' regular_express.txt
# 在匹配行后面添加 output 中的内容
sed -n '/library/r output' glib.h
# 先打印匹配行,再将匹配行中的 it 替换为 ll,在打印出来
sed -n '/library/{p;s/it/ll/;p}' glib.h
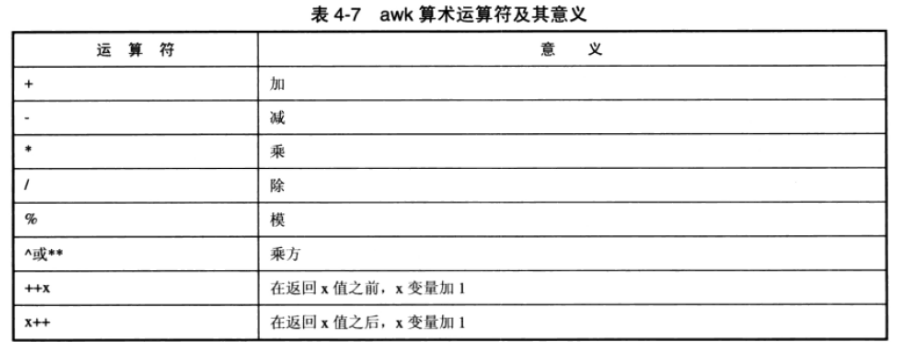
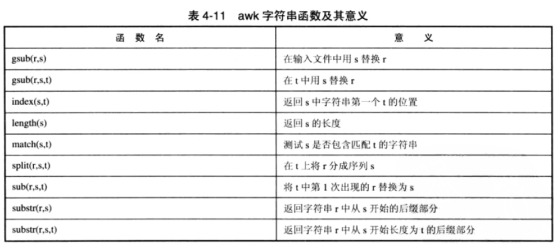
awk:awk 是以行为一次处理的单位,但以字段为最小的处理单位。也就是说将一行数据分成数个 “字段” 来处理(字段的分隔符默认为空格键或者 tab 键),比较适合处理小型的数据处理。awk 可以处理后续接的文件,也可以读取来自前面命令的 standard output(管道的方式)。
awk '条件类型1{动作1} 条件类型2{动作2} ...' filename
# 1. awk 后面跟两个单引号并加上大括号来设置想要对数据进行的处理动作和条件类型。
# 1.1 条件类型:一是使用逻辑运算符进行比较,满足比较的要求就进行紧跟的 {} 中的动作;二是 "/(中间是正则表达式)/"的使用,表示满足这个正则表达式的行则进行紧跟的 {} 中的动作;三是 BEGIN、END 等关键字。
# “条件类型 + {}” 这种方式其实和 sed 的 “定位 + function” 很像,其中这边的条件类型其实也就是相当于对处理的行进行定位。
# 1.2 {} 里面写的主要是各种 Linux 命令,因此当有多个命令的时候需要使用分号将这些命令隔开,或者直接以 Enter 键来隔开两个命令。awk 中还支持 if 条件判断,可实现对条件类型的替换。
# 1.3 动作里面的非变量的文字部分以及 printf 格式这些都需要使用双引号括住。因为单引号已经是 awk 命令的固定用法了。
# 1.4 与 bash、shell 的变量不同,在 awk 中变量可以直接使用而不用加 $ 符号。另外这些变量可以使用布尔运算符、比较运算符、算术运算符等。就跟 C 语言一样。
# 具体就是看后面的例子了。
# 2. awk 的处理流程是:
# 2.1 读取第一行,并将第一行的数据填入 $0、$1、$2 等变量中。其中 $0 代表一整行数据,$1 代表分割出来的第一个字段(默认分割符是空格或者 tab)。
# 2.2 根据条件类型的限制,判断是否需要进行后面的动作。
# 2.3 做完所有的动作和条件类型。
# 2.4 如果还有后续的 “行” 数据,则重复 1-3 的步骤,直接数据处理完毕。
# 3. awk 的运算符:
# 比较运算符:> 大于、< 小于、>= 大于等于、<= 小于等于、== 等于、!= 不等于。
# 赋值语句:=。
# 更详细地请看后面的图。
# 4. awk 的内置变量
# 4.1 NF-每一行拥有的字段数。
# 4.2 NR-目前 awk 处理的是第几行数据。
# 4.3 FS-目前的分割字符,默认是空格键。可以重新设置,并且支持正则表达式(扩展)。
# 更详细地请看后面的图。
# 5. 其他关键字
# 5.1 BEGIN 关键字,用来代表一个程序的开始,可以初始化变量,BEGIN 后面的内容只执行一次。
# 5.2 END 关键字,当 awk 程序执行结束之后执行 END 后面 {} 中的动作。
# 6. 内置函数
# 更详细地请看后面的图。
# 提取出账号与登录者的 IP,且账号 IP 之间以 tab 键隔开
$ last -n 5 | awk '{print $1 "\t" $3}'
# 以 : 为分隔符,对 /etc/passwd 文件进行处理,输出 UID(第三字段)小于 10 时的账号(第一字段)及其 UID。
# 需要注意的是,这边需要加上 BEGIN,表示在第一行处理之前就设置好,即预先设置好。假如没有使用 BEGIN 的话,那么第一行的分隔符还是空格或者 tab,可以看上面的流程,也就是从第二行开始分隔符才是 “:”。
$ cat /etc/passwd | awk 'BEGIN {FS=":"} $3 < 10 {print $1 "\t" $3}'
# test 的内容如下
Name 1st 2nd 3th
VBird 23000 24000 25000
DMTsai 21000 20000 23000
Bird2 43000 42000 41000
$ cat test | awk 'NR == 1 {printf "%10s %10s %10s %10s %10s\n", $1, $2, $3, $4,"Total"} NR >= 2 {total=$2 + $3 + $4; printf "%10s %10d %10d %10d %10d\n", $1, $2, $3, $4, total}'
Name 1st 2nd 3th Total
VBird 23000 24000 25000 72000
DMTsai 21000 20000 23000 64000
Bird2 43000 42000 41000 126000
# 跟上面效果一样,其中 {} 中可以使用 if,但是条件需要用 () 括起来。同时变量和表达式可以进行计算。
$ cat test | awk '{if (NR==1) printf "%10s %10s %10s %10s %10s\n", $1, $2, $3, $4,"Total"} NR >= 2 {total=$2 + $3 + $4; printf "%10s %10d %10d %10d %10d\n", $1, $2, $3, $4, total}'
# 表达式可以进行如下的算术运算符
awk 'BEGIN {FS=":";one=10;two=109} {if ($3==1000) print one + two}' /etc/passwd
# 可以使用 ||、&&、! 等运算符
awk 'BEGIN {FS=":"} {if ($3==1000 || $4== 1000) print $0}' /etc/passwd
# // 中的内容是正则表达式,/root/ 相当于一个条件,即这一行有满足 root 的字段话,就输出整行。
awk 'BEGIN{FS=":"} /root/{print $0}' /etc/passwd
# 第一个字段是 root 的话,则输出这一行。~ 是一个匹配正则表达式的符号。
awk 'BEGIN{FS=":"} $1~/root/' /etc/passwd
# 这一行中有匹配 root 的话,则输出这一行。
awk 'BEGIN{FS=":"} $0~/root/' /etc/passwd
# 第一个字段不是 root 的话,则输出。! 表示非。
awk 'BEGIN{FS=":"} $1!~/root/' /etc/passwd
# 将第一个字段中含有 root 的替换为 dawnguo,之后再打印整行。其中 OFS 是输出分隔符号。// 中同样是支持正则表达式的。
awk 'BEGIN {FS=":";OFS="--"} gsub(/root/, "dawnguo", $1) {print $0}' /etc/passwd



2.6. 压缩
Linux 下的压缩文件如下所示,常用的是 gzip、bzip2、xz 的压缩指令。但是这三个指令只能压缩一个文件,所以先使用 tar 指令将要压缩的多个文件打包,然后再压缩。
.Z compress 程序压缩的文件
.zip zip 程序压缩的文件
.gz gzip 程序压缩的文件
.bz2 bzip2 程序压缩的文件
.xz xz 程序压缩的文件
.tar tar 程序打包的数据,并没有压缩过
.tar.gz tar 程序打包的文件,并且经过 gzip 的压缩
.tar.bz2
.tar.xz
-c 建立打包文件
-t 查看打包的文件内容有哪些
-x 解打包或者解压缩
-z gzip 的方式进行压缩/解压缩,此时文档名最好以 .tar.gz 结尾
-j bzip2 的方式进行压缩/解压缩,此时文档名最好以 .tar.bz2 结尾
-J xz 的方式进行压缩/解压缩,此时文档名最好以 .tar.xz 结尾
-v 在压缩/解压缩的过程中,将正在处理的文件名显示出来
-f filename -f 后面要立刻接要被处理的文档名
-C 目录 解压缩,在特定的目录中解压缩
--exclude=FILE 压缩过程中,不将 FILE 打包
-p(小写) 保留备份数据的原本权限和属性
-P(大写) 保留绝对路径,即允许备份数据中可含有根目录存在之意
tar [-c] [z|j|J] [v] [-f 待建立的新档名] filename # 打包和压缩
tar [-t] [z|j|J] [v] [-f 已有的 tar 档名] # 查看
tar [-x] [z|j|J] [v] [-f 已有的 tar 档名] [-C 目录] # 解压缩
附:
1. [-f filename] 是紧接连一起的,那么 [-jcvf filename] 是可以的,但是 [-jvfc filename] 是不对的,因为文档名变成了 c。因此,最好将 -f 单独拎出来。

