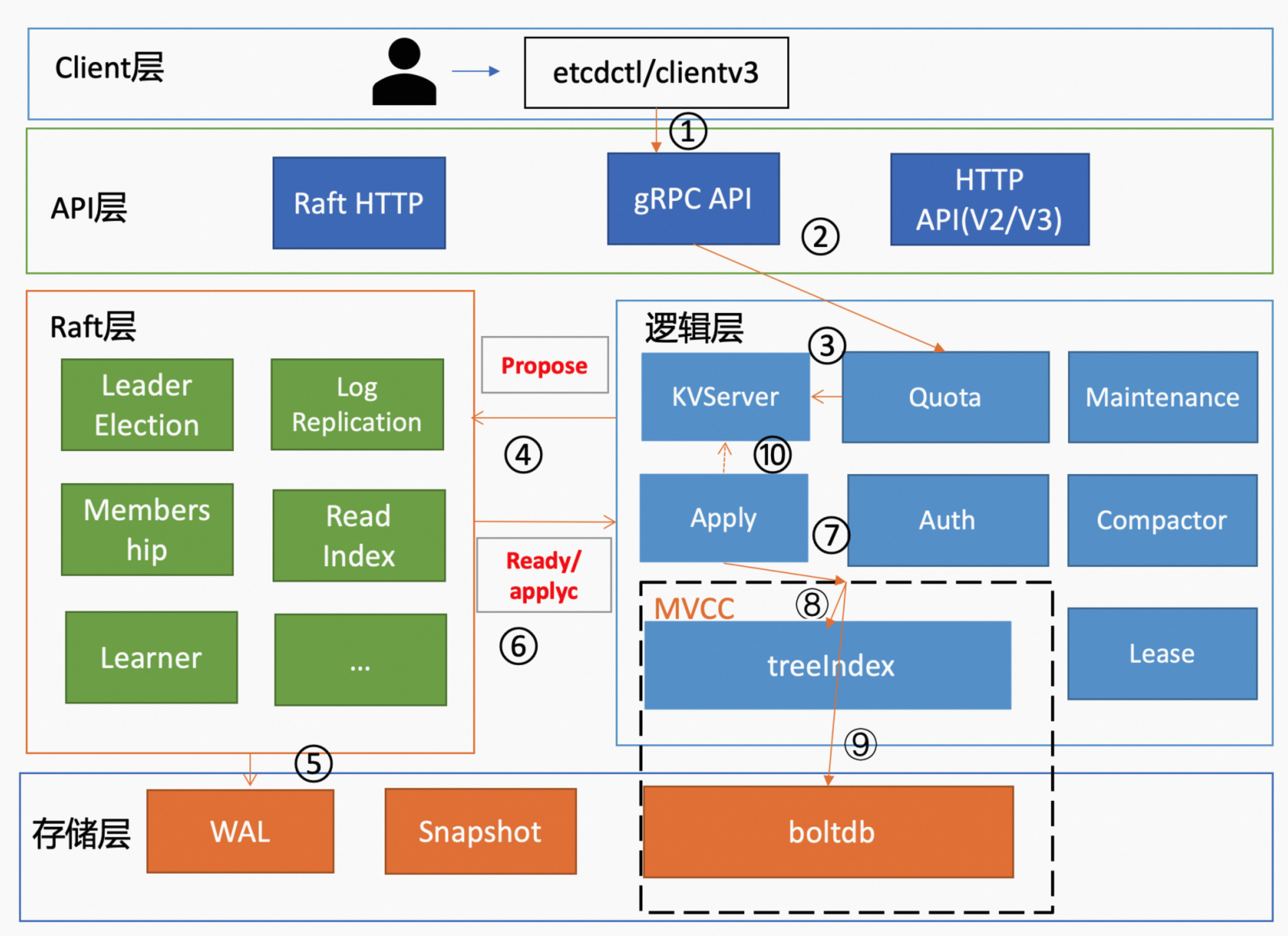
写请求流程
当 client 发起一个更新 hello 为 world 请求后。若 Leader 收到写请求,它会将此请求持久化到 WAL 日志,并该 WAL 日志打包发送给其他节点。若一半以上节点持久化成功,则该请求对应的日志条目会被标识为已提交(commited)。之后,会将已 commited 的日志条目应用到状态机 boltdb 中,该日志条目就变成了 applied。写请求的流程如图所示,
1. 客户端发起请求
etcdctl 发起 put 请求,将 key 为 hello 的 value 更新为 world。在 Kubernetes 集群中,则由 API Server 通过 etcd 的 client 库发起请求,etcdctl 也使用了该库。
etcdctl 会通过负载均衡算法选择一个 etcd 节点建立连接,随后发起 Put 请求的 gRPC 调用。
etcd put hello world --endpoints http://172.16.0.1:2379,http://172.16.0.2:2379
2. API 层处理
先经过 API 层的 gRPC 拦截器处理。
3. Quota 模块
之后,请求先到达来到逻辑层的 Quota 模块。Quota 模块会先检查当前 etcd db 大小加上写请求的 key value 大小之和是否超过了 db quota。先经过 Quota 模块的主要原因是写请求会增加 etcd db 的容量,而 db 容量是有 quota 的,因此需要先检查写请求的增加会不会导致 db 容量超过 quota。
-
如果超过了 quota,etcd 会产生一个 NO SPACE 的 alarm(告警)请求,并通过 Raft 日志同步给其他节点。同时会将告警持久化到 db 中。之后,Apply 模块在 apply 日志的时候,会先检测当前 db 是否存在 NO SPACE 的 alarm。如果存在该 alarm,就会拒绝写入,此时 etcd 集群会变成只读状态,etcd 的日志中会出现 "etcdserver: mvcc: database space exceeded" 的错误。
-
如果没有超过的话,则该请求的处理会来到 KVServer 模块。
4. KVServer 模块
KVServer 模块的 put 方法会继续对该请求进行处理。先经过限速检查、鉴权、大包检测等(这一系列检查主要是为了集群的稳定性考虑,避免雪崩),最终将写请求的内容打包成一个 proposal,提交给 Raft 模块。整体流程如图所示:
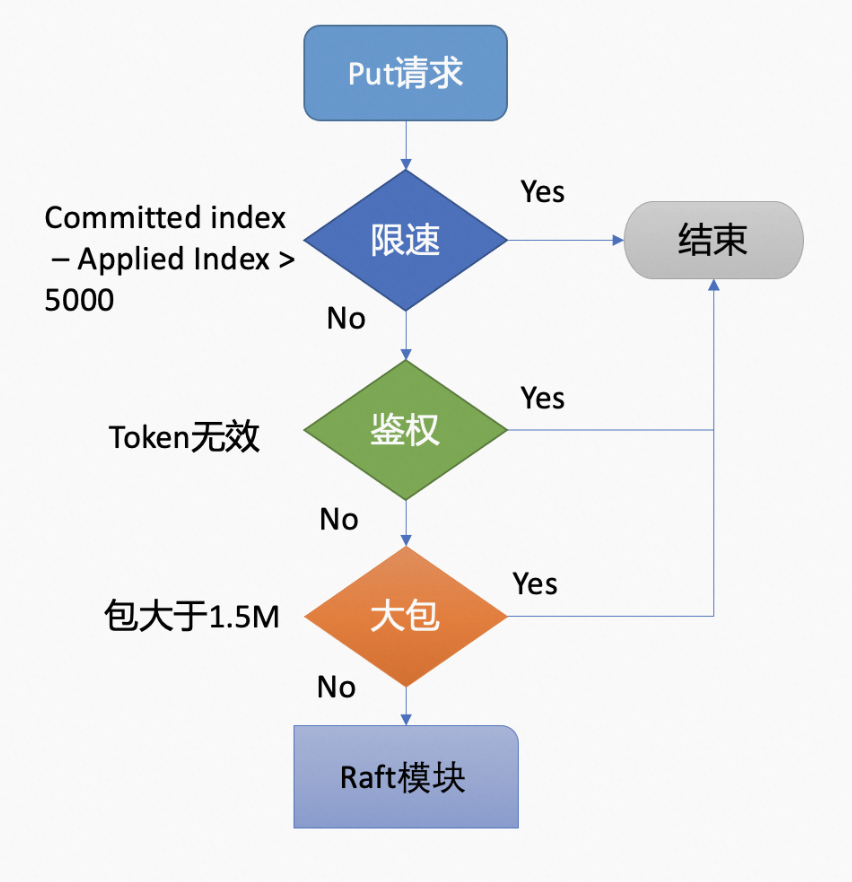
- 限速检查。如果已 commited 的日志索引(commited index)大于已 applied 到状态机的日志索引(applied index)超过 5000 的话,则会给客户端返回 “etcdserver: too many requests” 错误。
- 鉴权。如果限速检查通过,则会尝试获取请求中的鉴权信息。如果请求中的 token 无效的话,则会给客户端返回 “auth: invalid auth token” 错误。
- 大包检测。接着会检查写入的包的大小是否超过了默认的 1.5MB,如果超过了则会给客户端返回 “etcdserver:request is too large” 错误。
- propose 一个 prosoal 给 Raft 模块。通过上述一系列检查后,向 Raft 模板提交一个 proposal(提案)。提案的内容类似于“使用 put 命令,设置 key 为 hello 的 value 的值为 world”。
5. Raft 模块
Raft 模块收到 proposal 后,先判断当前节点的角色,
-
如果当前节点是 follower,它会将其转发给 leader 处理(只有 leader 才能处理写请求)。
-
如果当前节点是 leader 则自己处理。处理流程如下:
-
Raft 模块会生成待持久化的 Raft 日志(包含 proposal 的内容、leader 任期号、日志的索引)和待转发给 follower 节点的消息(包含 Raft 日志的内容)。
-
之后将消息发送给各个 follower 节点,同时把 Raft 日志持久化到 WAL(Write Ahead Log)日志文件中。
-
当一半以上节点都持久化该 Raft 日志后,Raft 模块会通过 channel 告知 Apply 模块 proposal 对应的 Raft 日志已被集群中多数节点确认,Raft 日志的状态为 commited。同时,proposal 的处理情况也会告知 KVServer 模块,KVServer 将写请求返回。KVServer 针对该 proposal 的处理有设置超时时间,默认超时时间是 7 秒(5 秒磁盘 IO 延时+2*1 秒竞选超时时间)。如果超时未收到该 proposal 的处理结果,则会返回“etcdserver:request timed out” 错误。
-
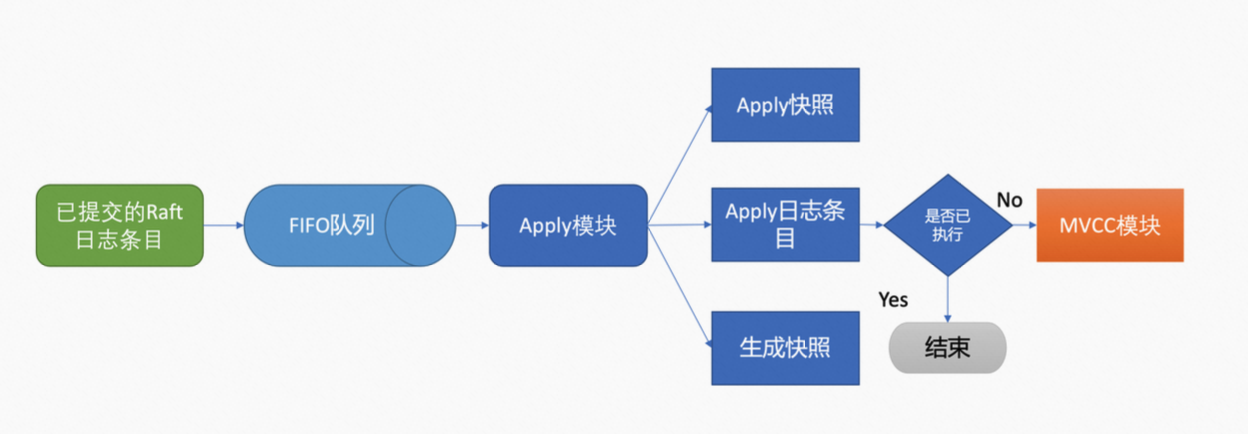
6. Apply 模块
Apply 模块会取出 Raft 日志,并异步地将 commited Raft 日志持久化到状态机。
- 首先,Apply 模块从 channel 中取出 Raft 日志,添加到先进先出(FIFO)队列。
- 随后,Apply 模块按入队顺序、异步、依次通过 MVCC 模块执行日志中的 proposal 内容。
- 如果 Apply 模块在执行 proposal 内容的时候挂了,那么 etcd 节点重启之后会从 WAL 日志文件中解析出已提交的 Raft 日志内容,将其重新交给 Apply 模块。
- 为了确保 Apply 模块执行的幂等性,也就是防止 proposal 被重复执行,导致 etcd 节点之间的版本号不一致、数据混乱的现象。etcd 引入了 consistent index。Apply 模块在执行 proposal 前,会首先判断当前 proposal 是否已经执行过了,也就是比较 consistent index 和 Raft 日志的 index,如果执行了则直接返回,若没有执行且无 db quota 满的告警,则会进入 MVCC 模块开始进行持久化。
- 为了避免在执行完 proposal 内容后,etcd 节点就挂了,而 consistent index 还没更新的问题,MVCC 将 proposal 内容的执行和 consistent index 的更新两个操作作为一个原子性事务提交。
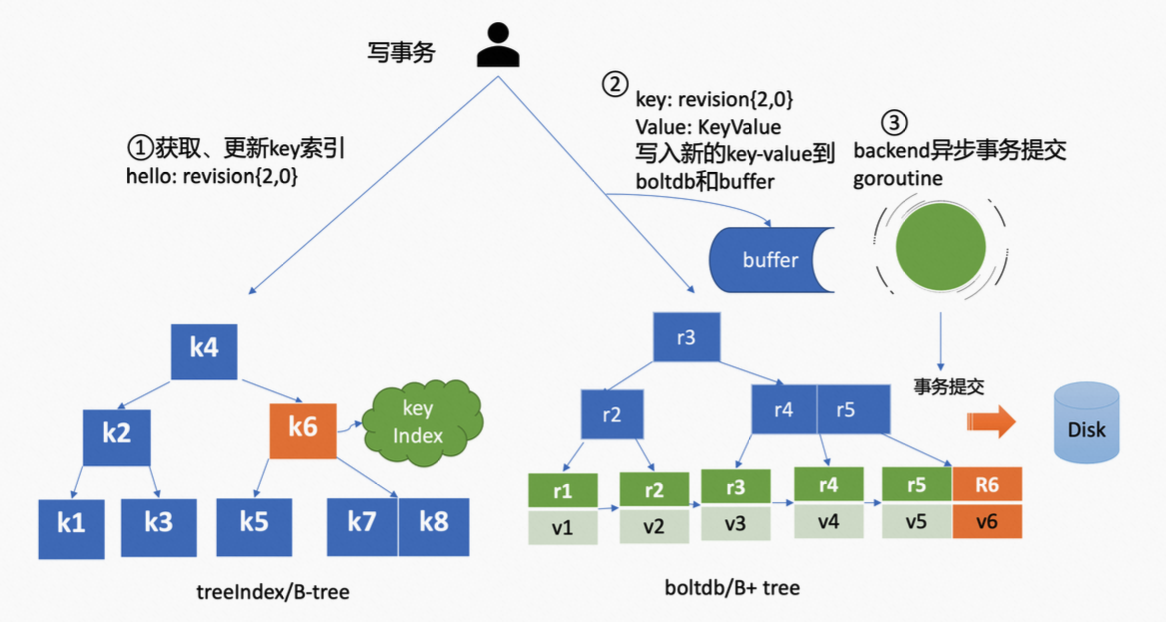
7. MVCC 模块
Apply 模块判断 proposal 未执行后,则会调用 MVCC 模块来执行 proposal 内容,也就是调用 MVCC 模块提供的接口。MVCC 处理流程如下,
-
首先基于 currentRevision 自增生成新的 revision 如 {2,0}(2 是创建版本号,0 是修改次数),也会从 treeIndex 模块中查询到 key 的创建版本号、修改次数,最终结合两者的情况,将更新后的 revision 信息和 key 存储到 treeIndex 中。由于,hello 这个 key 是新建的,因此它的 revision 就是 {2,0}。
-
之后先将数据写入到 buffer 中,并调用 boltdb 提供的 put 接口,该接口会将数据更新为 boltdb 对应的内存数据结构。完成之后就表示数据已写入完成,但是此时数据可能并未真正地持久化。
之前在介绍 etcd 读请求的时候,读请求也是优先从 buffer 中读取,如果未读取到,再从 boltdb 中读取。buffer 不仅实现了读写性能的提升,同时保证了数据的一致性。
-
同时 etcd 的 backend goroutine 会定期、异步、批量持久化之前 put 请求所做的改变,也就是在 goroutine 中定期调用 boltdb 的 commit 接口。
该接口会对内存数据结构中的 B+tree 进行平衡、分裂,并且将脏数据、元数据信息刷新到磁盘。由于该过程开销昂贵,如果每次 put 请求都同步调用一次 commit 接口,etcd 的写性能将会变得很差。因此,etcd 才采用合并多个写请求后再进行一次提交,这种方式显著提升了 QPS 和吞吐量。通常情况下,goroutine 会默认每隔 100ms,将累积的写请求一次性提交。但是,如果堆积的请求数过多(大于 1w)时,也会触发同步提交。