读请求流程
etcd 是典型的读多写少场景。读请求的流程如图所示:
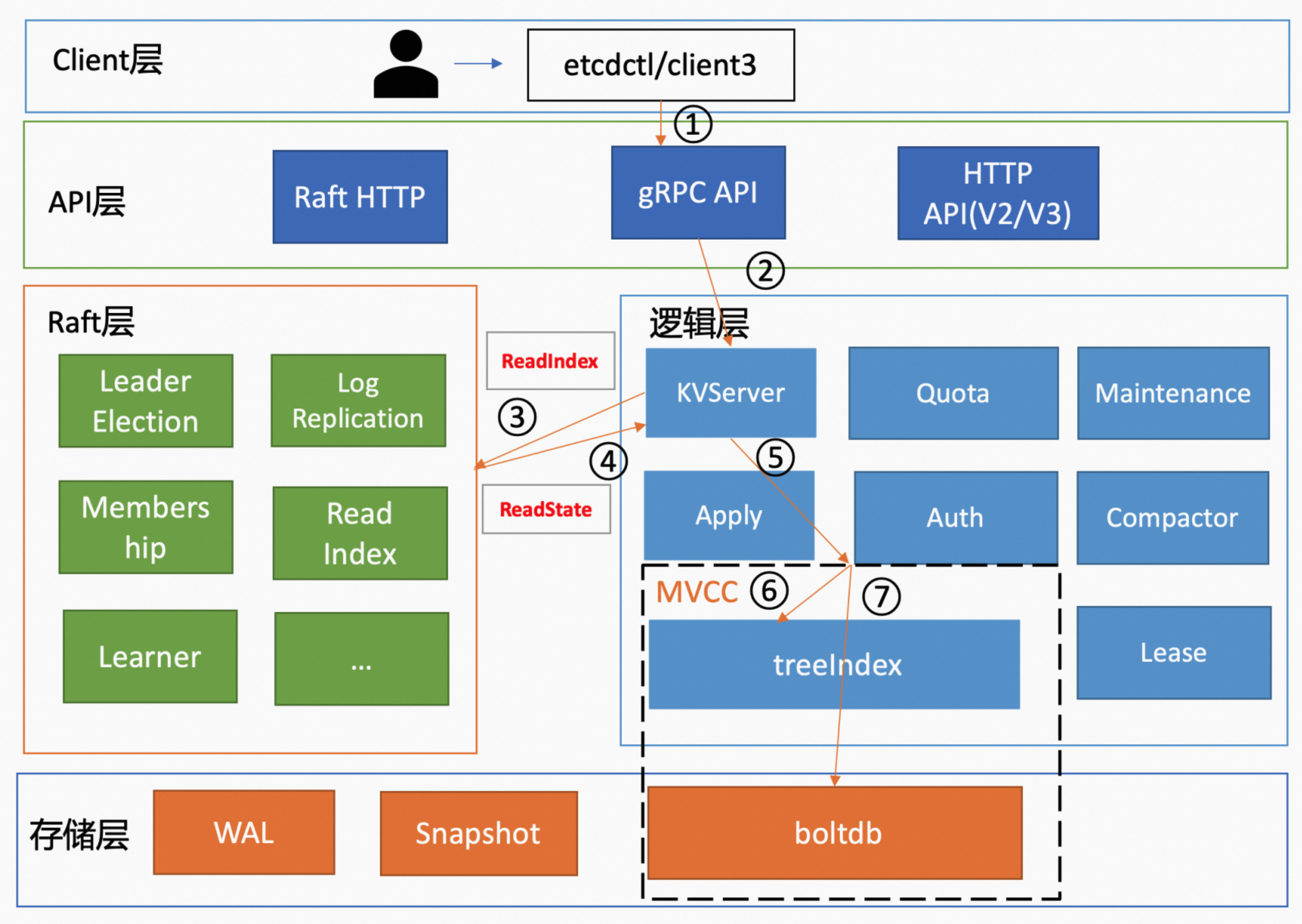
1. 客户端发起请求
etcdctl 发起 get 请求获取 key 为 hello 的 value。在 Kubernetes 集群中,则由 API Server 通过 etcd 的 client 库发起请求,etcdctl 也使用了该库。
etcdctl get hello --endpoints http://172.16.0.1:2379,http://172.16.0.2:2379
-
etcdctl 先对命令中的参数进行解析。其中
get是请求的方法;hello是要查询的 key 名;endpoints是 etcd 的地址,在生产环境中通常会配置多个 endpoints。 -
之后 client 使用 Round-Robin 算法从 endpoints 列表中选择一个 endpoint 建立连接,使 etcd server 负载尽量均衡。
-
接着 client 调用 Range RPC 方法,将请求发送给 etcd server。在这里需要注意:get 请求最终发起的是 Range RPC 方法,这是因为 etcd 没有提供获取单个 key 的方法,获取单个/多个 key 用的方法都是 Range 方法,只是在请求中通过参数来控制获取的是单个 key,还是一个范围。
2. API 层处理
client 发送的 Range RPC 请求到达 etcd 之后,etcd 会根据 RPC Method 找到相应的 handler 进行处理。handler 中会包含了一些拦截器,这些拦截器是串联执行的,在拦截器的逻辑中,最终会调用 KVServer 模块的 Range 接口处理请求。
拦截器是什么呢?拦截器其实提供了一个请求执行前后的 hook 能力,比如
- 记录请求的执行耗时;
- 记录请求的错误码;
- 记录请求的来源 IP(在请求延时超过指定阈值时,打印包含来源 IP 的慢查询日志(3.5 版本));
- 提供了丰富的 metrics、日志;
- 检查请求行为;
- 控制请求是否允许通过,比如 etcd learner 节点只允许指定接口和参数的访问;
- 要求执行一个操作前集群必须要有 leader,防止脑裂(脑裂就是存在多个 leader)。
etcd 在启动的时候会将实现 KV 各方法的对象注册到 gRPC Server 上,并在其基础注册对应的拦截器。
如果用过 gin 框架,或者其他 http 框架的话,就挺好理解的了。在编写 http 服务的时候,我们会编写相应的 handler 函数负责请求的处理。但是在这些 handler 被调用之前,往往会经过一些通用 handler 函数的处理,比如权限检查等。这些通用 handler 函数,就可以理解为拦截器。
3. KVServer 模块
KVServer 模块的 Range 接口在处理请求时,有串行读和线性读两种读处理方式。下面介绍一下这两种读方式的区别。
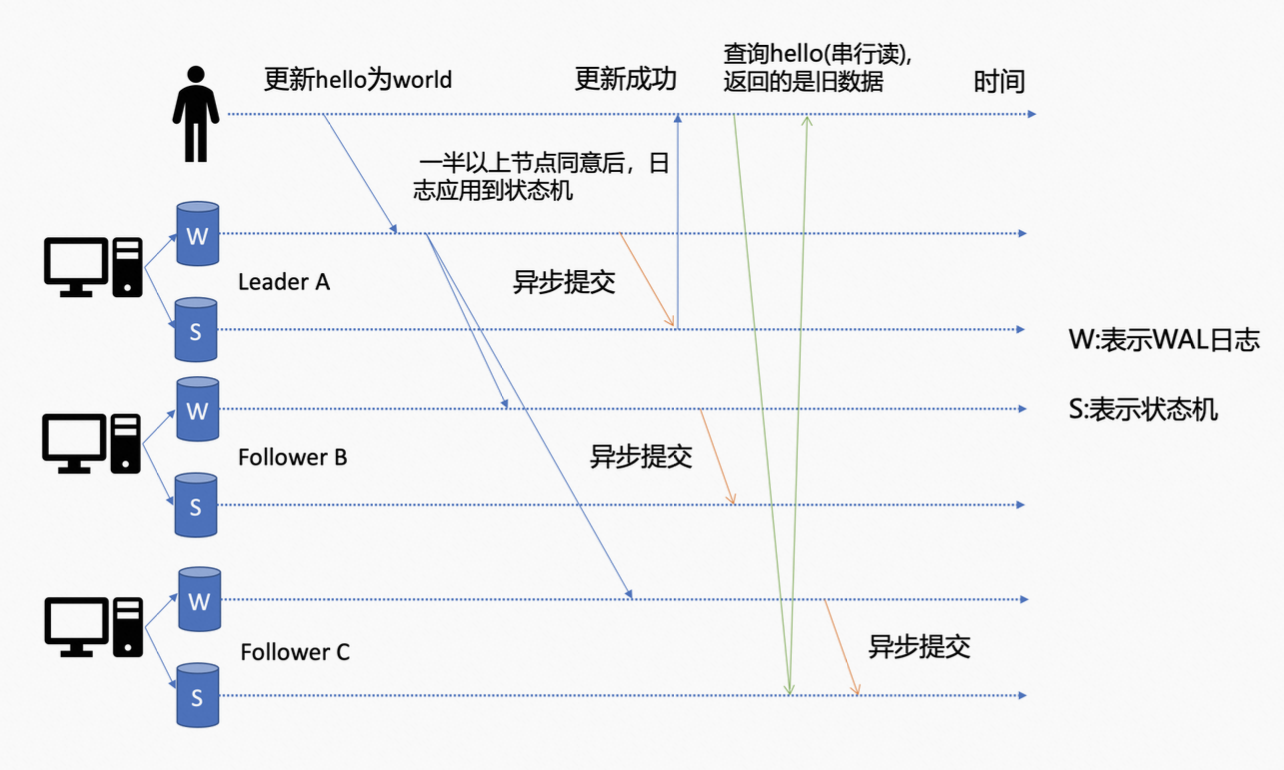
etcd 为了保证服务高可用,生产环境一般会部署多个节点,但是各个节点在任意时间点持久化之前写入数据的进度会不一样。举个例子,如下图所示,client 发起了一个更新 hello 为 world 的请求之后,如果 leader 收到了该写请求,那么会将该请求持久化到自己的 WAL 日志文件,同时广播给其他各个节点,如果一半以上的节点都持久化成功,则该请求对应的日志条目会被标识为 commited。etcd 会异步从 Raft 模块获取已 commited 的日志条目,并 apply 到 boltdb(状态机) 中。但是,这个过程不同节点的进度会不一样,比如此时 C 节点 apply commited 日志条目很慢,更新 hello 为 world 的日志条目还未被 apply 到状态机。
如果此时 client 发起了一个读取 hello 的请求,连接到的是 C 节点,
-
针对串行读来说的话。它会直接读取 boltdb(状态机)中的数据,并返回,此时就会返回旧数据。
-
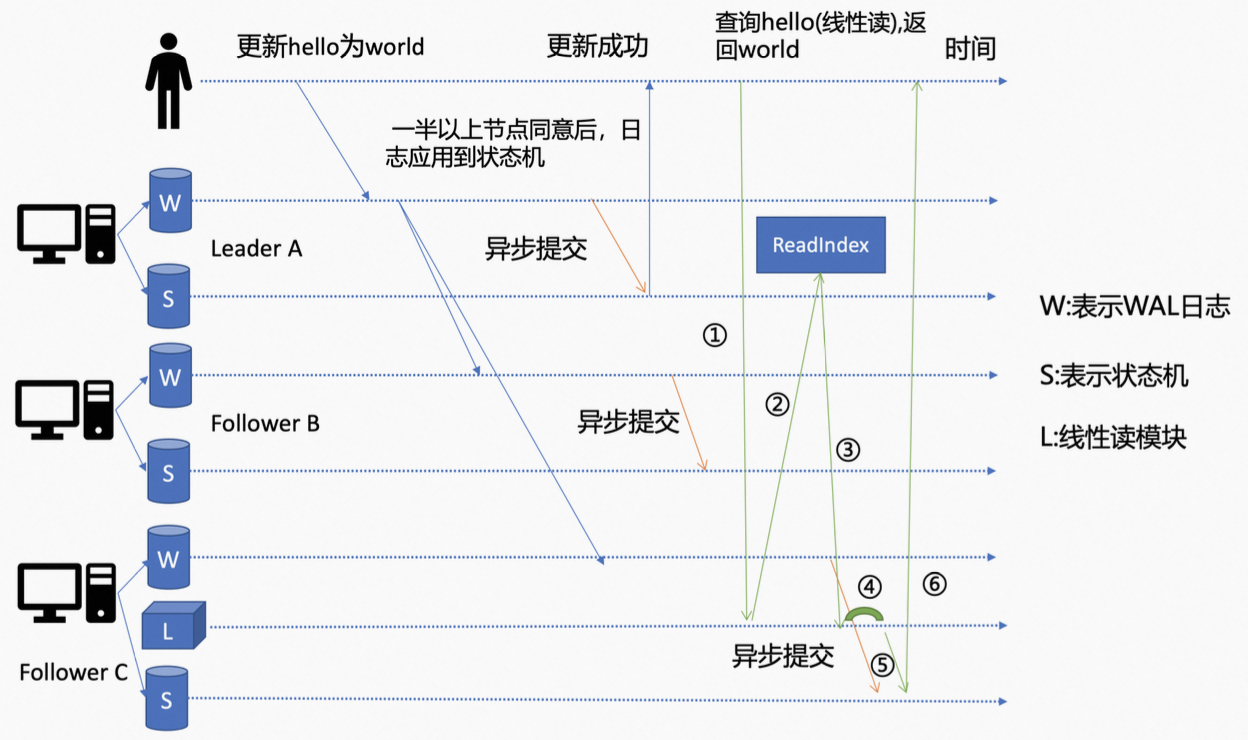
针对线性读来说的话。它会通过 ReadIndex 机制(etcd 3.1 引入)等待 C 节点将更新的日志条目 apply 到 boltdb(状态机)后,再将数据返回,从而保证返回的是最新的数据。整个过程如下:
- Follower C 的 KVServer 模块在处理的时候,会首先向 raft 模块发起 ReadIndex 请求(文章首图),从 leader 获取 etcd 集群最新的已 commited 的日志索引(commited index),下图中的步骤 2。
- leader 收到 ReadIndex 请求后,会先向 follower 节点发送心跳确认,当一半以上的节点都确认 leader 身份后,leader 会将已提交的 commited index 返回给 follower C,下图中的步骤 3(这一步主要是为防止脑裂等异常现象,确保 leader 的身份)。
- (文章首图)follower C 的 raft 模块会将 commited index 封装在 readstate 结构体中,通过 channel 返回给 KVServer 模块。KVServer 模块会一直等待,等到 boltdb(状态机) applied index(已应用索引) 大于等于 leader 返回的 commited index(已提交索引)之后,再通过 MVCC 模块读取 boltdb(状态机)中的数据。从而确保返回的是最新数据。
总结下,
-
串行读,适合对数据敏感度较低的场景,具有低延时、高吞吐量的特点。它可能会出现读取到的数据,不是最新的情况。
-
线性读,适合对数据敏感度高的场景,是 etcd 默认读模式。在延时、吞吐量上相比串行读会差一点。由于线性读经过了 Raft 协议模块,它反应的是 etcd 集群共识,因此使用线性读的 client 都能访问到最新值。
etcd 3.0 线性读使用 raft log read,由于要涉及到 raft 多数投票以及要进行 WAL 日志持久化会有磁盘 IO 开销,因此性能相比 ReadIndex 较差。
4. MVCC 读取数据
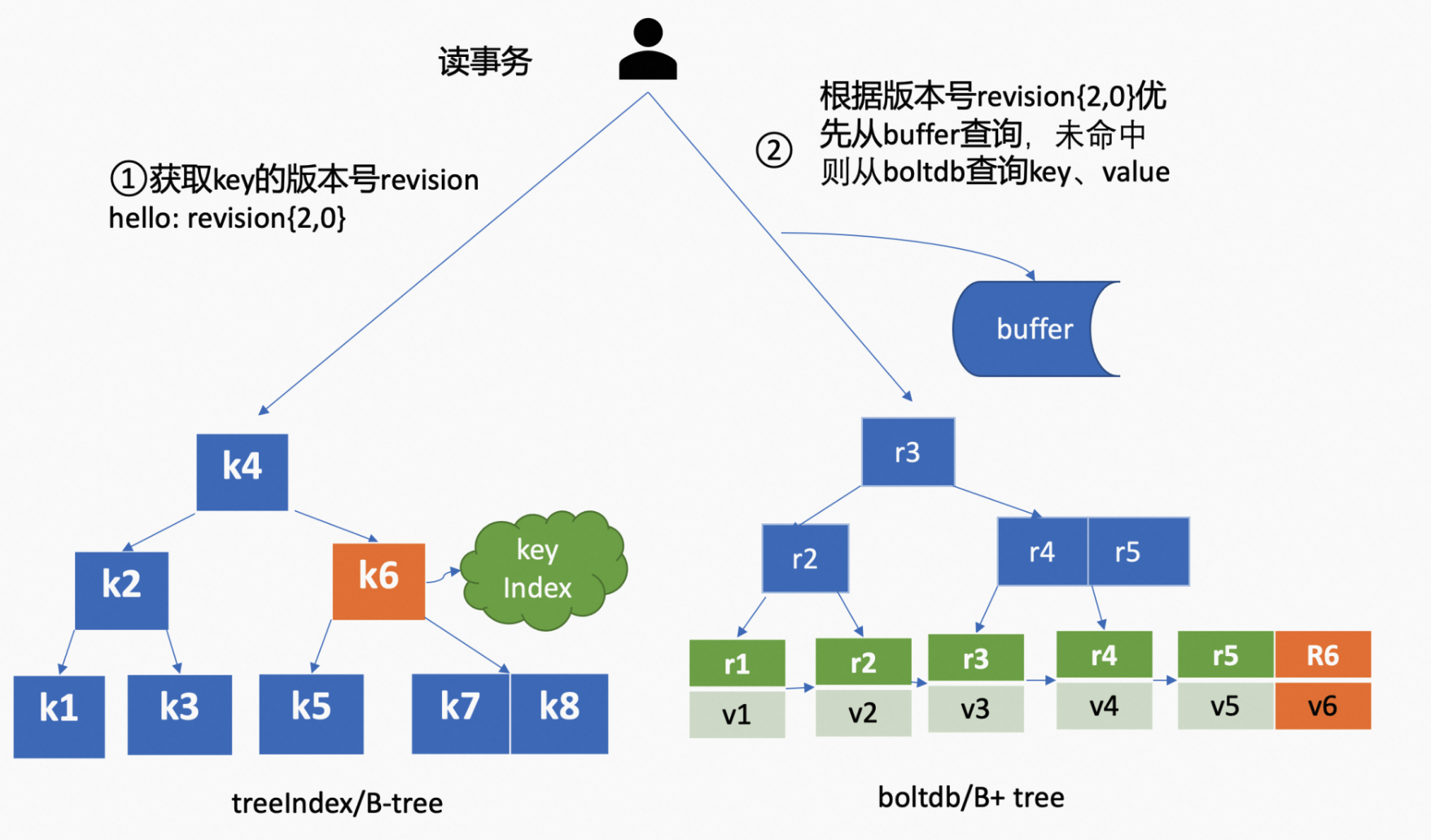
-
首先是从 treeIndex 中获取 key 对应的 revision。
-
获取到 revision 之后,在访问 boltdb 前,会先从一个内存读事务 buffer 中,通过二分查找的方式访问 key 是否在 buffer 中,如果命中则直接返回。
-
如果 buffer 未命中,此时才会以 revision 为 key 作为 blotdb 的 key,向 boltdb 模块查询数据,从 boltdb 中获取相应的 value 信息。
在从 boltdb 中读取的过程中一般也不会产生磁盘 IO。这是因为,etcd 在启动的时候会通过 mmap 机制将 etcd db 文件映射到 etcd 进程地址空间,并且设置 mmap 的 MAP_POPULATE flag,它会告诉 Linux 内核去预读文件,此时 Linux 内核会将文件内容先拷贝到物理内存中(这个过程是会产生磁盘 IO)。因此,在节点内存足够的情况下,处理读请求过程中其实都不会产生磁盘 IO。但是,如果 etcd 节点内存不足,可能会导致 db 文件对应的内存页被换出,当读请求命中的页未在内存中时,就会产生缺页异常,导致在读过程中产生磁盘 IO。可以通过观察 etcd 进程的 majft 字段来判断 etcd 是否产生了缺页中断。
附录
mmap
mmap 和 read/write 的区别
-
linux 中,文件的读写操作通常通过 read、write 两个系统调用来实现。linux 在执行 read 系统调用时,会首先将文件内容读取到 buffer(页缓存),然后从 buffer 中再将数据拷贝到 read 传递的 buf 中(文件-buffer-buf)。之后的 read/write 操作其实都是先尝试对这块 buffer 进行操作,linux 内核会定期将 dirty page 写回到文件中 ,这些页也可能会被回收。
-
mmap 是直接将文件映射到内存,实现文件的磁盘地址和进程虚拟地址空间中虚拟地址的一一映射。如果之后要对文件内容进行读写的话,都是操作映射的内存。相比 read/write 等读取文件的方式来说,
- mmap 可以使得读写文件的性能更高,因为它操作的是内存而不是磁盘。
- 可以方便地操作文件,文件内容都在内存了,不再需要打开文件等操作。
- mmap 减少了内存拷贝次数,它只需要一次拷贝,就是将磁盘文件到 mmap 映射的内存(文件-buffer),之后的操作也都是在内存上。而 read/write 是有 2 次的。
因此,mmap 适合读写频繁的场景。
mmap 原理
简单来说的话,其实就是在进程的虚拟内存空间开辟一块连续的空间,将其映射到一块物理内存上(这个是真正存文件数据的),并将文件数据读取到这块物理内存上。当进程退出或者意外崩溃,内核会将物理内存上的数据同步到文件中。
Go mmap 示例代码
package main
import (
"fmt"
"log"
"os"
"syscall"
"unsafe"
)
const defaultMaxFileSize = 1 << 30 // 假设文件最大为 1G
const defaultMemMapSize = 128 * (1 << 20) // 假设映射的内存大小为 128M
func main() {
mmpFile := NewMmpFile("test.txt")
defer mmpFile.munmap()
defer mmpFile.file.Close()
msg := "hello csdn colinrs!"
mmpFile.grow(int64(len(msg) * 2))
for i, v := range msg {
mmpFile.data[i] = byte(v)
}
}
type MmpFile struct {
file *os.File
data *[defaultMaxFileSize]byte
dataRef []byte
}
func NewMmpFile(fileName string) *MmpFile {
file, err := os.OpenFile(fileName, os.O_RDWR|os.O_CREATE, 0666)
if err != nil {
log.Fatalf("Open file error: %v", err)
}
mmpFile := &MmpFile{file: file}
mmpFile.mmap()
return mmpFile
}
func _assert(condition bool, msg string, v ...interface{}) {
if !condition {
panic(fmt.Sprintf(msg, v...))
}
}
func (mmpFile *MmpFile) mmap() {
b, err := syscall.Mmap(int(mmpFile.file.Fd()), 0,
defaultMemMapSize, syscall.PROT_WRITE|syscall.PROT_READ, syscall.MAP_SHARED)
_assert(err == nil, "failed to mmap", err)
mmpFile.dataRef = b
mmpFile.data = (*[defaultMaxFileSize]byte)(unsafe.Pointer(&b[0]))
}
func (mmpFile *MmpFile) grow(size int64) {
if info, _ := mmpFile.file.Stat(); info.Size() >= size {
return
}
_assert(mmpFile.file.Truncate(size) == nil, "failed to truncate")
}
func (mmpFile *MmpFile) munmap() {
_assert(syscall.Munmap(mmpFile.dataRef) == nil, "failed to munmap")
mmpFile.data = nil
mmpFile.dataRef = nil
}

