前言
etcd v3 中 MVCC(Multiversion Concurrency Control) 机制的核心思想是保存 key-value 的多个历史版本。在 MVCC 中,更新一个 key-value 数据的时候,并不会直接覆盖原来的数据,而是会新增一个版本号来存储新的数据。当删除数据的时候,也会增加版本号,并且会新增一条带删除标识的数据记录。
因此,在 MVCC 机制中每个版本号都会对应一个的数据,同理每个数据也都会有一个版本号。指定版本号读取数据时,它实际上访问的是版本号生成时间点的快照数据。
基于 MVCC 机制,etcd 提供了可靠的 Watch 机制,避免了 client 频繁发起 list pod 等 expensive request 操作,保障 etcd 集群的稳定性。MVCC 还能以较低的并发控制开销,实现各类隔离级别的事务,保障事务的安全性,是事务特性的基础。
整体架构
下图是 etcd 的整体架构,其中 MVCC 模块由 Apply 模块调用,
- 对于用户的读请求(比如 range 操作)来说。它会调用 MVCC 模块来获取 key 对应的 value。
- 对于用户的写请求(比如 put/delete 操作)来说。在对应的 Raft 日志标识为 commited 之后,Apply 模块会异步执行 Raft 日志的内容,此时它就是调用 MVCC 模块来持久化 key-value 数据。

MVCC 主要基于 treeIndex、Backend/boltdb 两个模块,实现了对 key-value 的增删改查。以发起 get hello 请求为例,它会首先从 treeIndex 中获取到 hello 的 revision,然后再通过该 revision 从 boltdb 中获取 value 信息,这个 value 包含 key-value、各种 revision、lease 信息等。
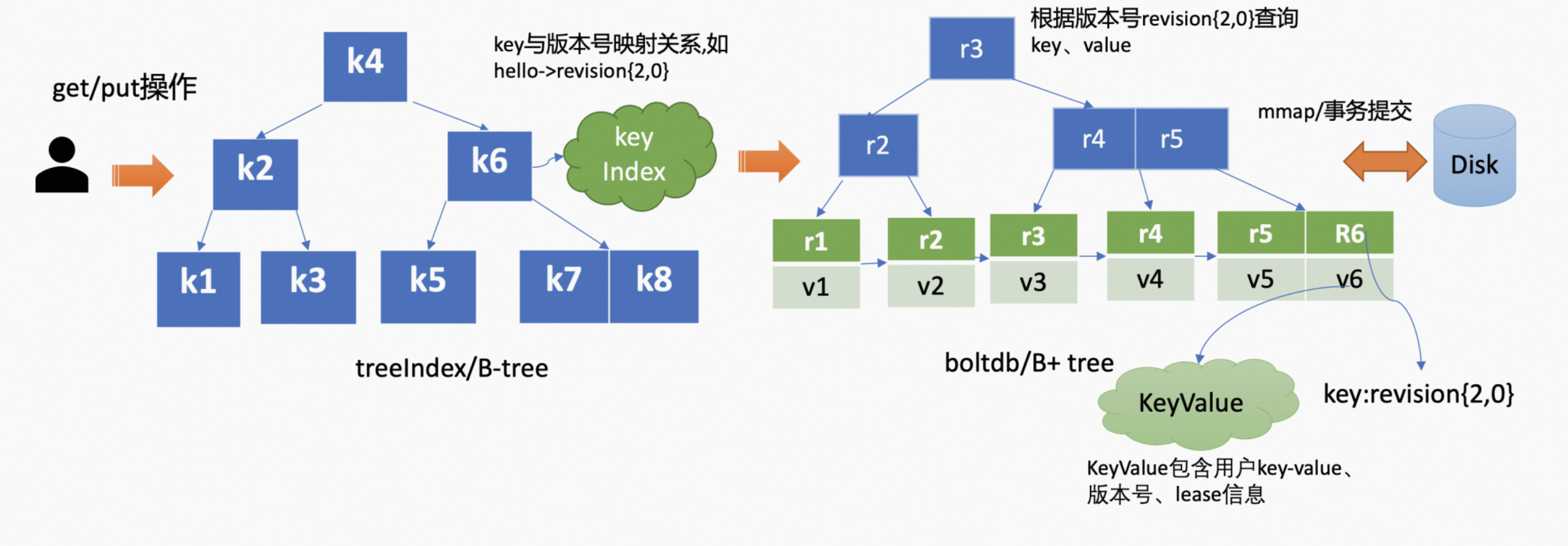
treeIndex 和 boltdb 两个模块的关系如下图所示,

treeIndex
treeIndex 模块保存了用户 key 和 revision(版本号)之间的映射关系。treeIndex 使用了内存版 B-tree,一个 google 的开源项目,使用 go 实现,并对外提供简易的调用接口。在 B-tree 中,度是一个核心参数,它决定了每个节点上的数据量是多少。在一个度为 d 的 B-tree 中,每个节点保存的最大数据量为 2d-1,也就是 key 数为 2d-1。否则,需要进行平衡、分裂等操作。在 treeIndex 模块中,可创建的最大度是 32 的 B-tree,也就是一个节点最多可以保存 63 个 key。
那么 treeIndex 模块是怎么保存 key 和 revision 之间的映射关系的呢?针对每个 key,它都会在节点上保存一个 keyIndex 结构(包含了 key 和 revision 的内容),如下所示,
type keyIndex struct {
// 用户的 key 名称,比如 "hello"
key []byte
// 最后一次修改 key 时的 etcd 版本号
modified revision
// generations 保存了一个 key 若干代版本号信息,每代中包含对 key 的多次修改的版本号列表
generations []generation
}
其中 generations 表示一个 key 从创建到删除的过程,对应 key 的一个生命周期的开始与结束。当第一次创建一个 key 时,会生成第 0 代,后续的修改操作都是在第 0 代中追加修改版本号。当把 key 删除后,会生成新的一代,第 1 代。一个 key 不断经历创建、删除的过程,会生成多个代。
type generation struct {
ver int64 // 表示此 key 的修改次数
created revision // 表示 generation 结构创建时的版本号
revs []revision // 每次修改 key 时的 revision 追加到此数组
}
其中版本号 revision 并不是一个简单的整数,而是一个结构体,如下所示。
type revision struct {
main int64 // 一个全局递增的主版本号,随 put/delete/事务请求递增
sub int64 // 一个事务内的子版本号,从 0 开始随事务内 put/delete 操作递增
}
如下所示,如果一个空集群,全局版本号默认为 1,执行了一个包含两次 put、一次 get 的事务时。由于全局版本号是随着写请求递增的,因此 main 会变成 2,sub 是随着事务内的 put/delete 操作递增的,最终 key hello 的 revision 为 {2, 0},key world 的 revision 为 {2, 1}。
$ etcdctl txn -i
compares:
success requests (get,put,del):
put hello 1
get hello
put world 2
为什么使用 B-tree
为什么使用 B-tree 来保存 key 和 revision 之间的映射关系呢?而不是使用哈希表、或平衡二叉树呢。主要是考虑到 etcd 要支持范围查询,因此使用的数据结构也必须要支持范围查询才行。
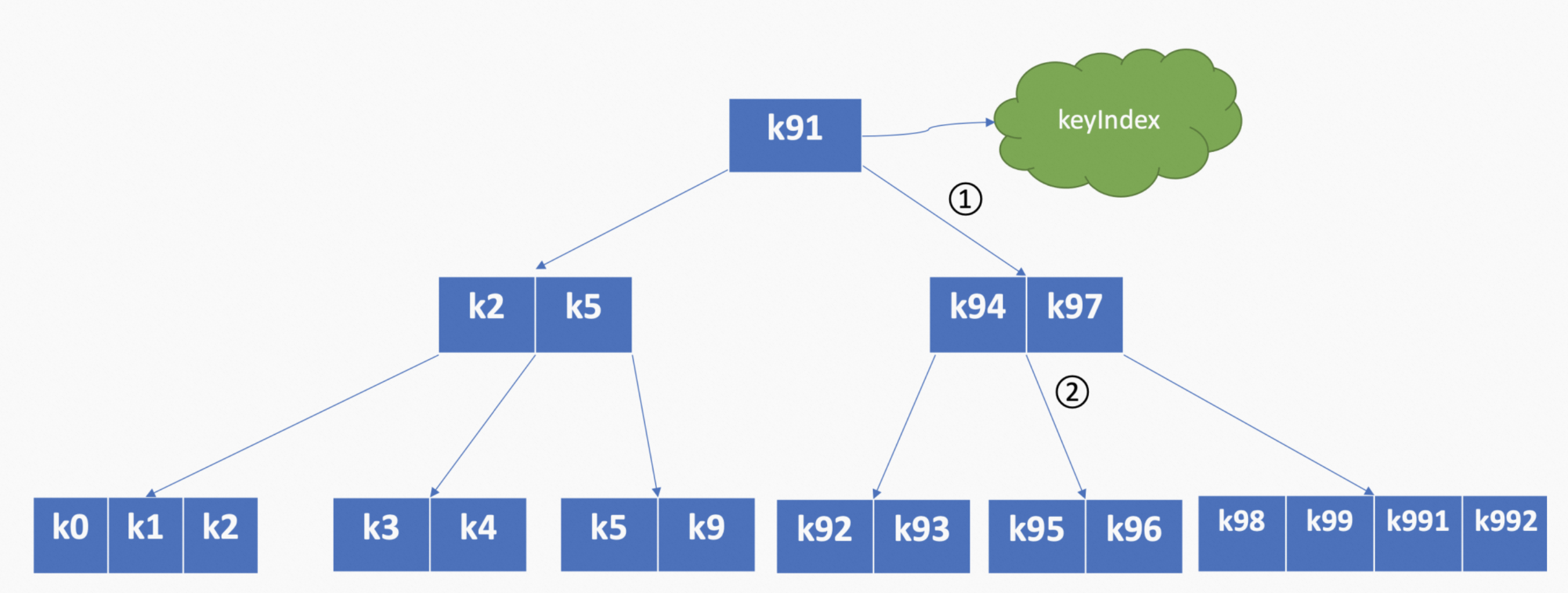
哈希表不支持范围查询不适合,而平衡二叉树每个节点只能容纳一个数据、会导致树的高度较高。B-tree 由于每个节点可以容纳多个数据,相比之下树的高度更低、更扁平,涉及的查找次数更少,因此采用 B-tree。以下图的 B-tree 为例,当要查找 k95 的时候,只需要经过图中两次比较即可快速找到 k95 所在的节点。
boltdb
etcd 默认支持多种后端存储,后端存储模块(Backend)主要负责 key-value 的持久化存储,由 Buffer、ReadTx、BatchTx 组成。Buffer 是数据缓存区,ReadTx 定义了抽象的读事务接口(对应读请求),BatchTx 在 ReadTx 之上定义了抽象的写事务接口(对应写请求)。
目前,etcd 后端存储的实现采用的是 boltdb。boltdb 是一个基于 B+tree 实现的、支持事务的 key-value 嵌入式数据库。
-
在 etcd 中 boltdb 存储的 key 是 revision,比如上文中的 {2,0},value 是 mvccpb.KeyValue 结构体,它由 key、value、create_revision、mod_revision、version、lease 组成。
- create_revision 表示该 key 创建时的版本号。
- mod_revision 表示 key 最后一次修改时的版本号。
- version 表示 key 的修改次数。
相比将用户的 key 作为 boltdb key,用户历史的 value 作为 boltdb value 的方式来说。以 revision 为 key 的好处是可以减少并发冲突、读写被放大的问题。因此以用户 key 作为 boltdb key 的话,如果两个 put 请求操作同一个 key 的话,则会出现并发冲突。
-
boltdb 通过 bucket 来隔离集群元数据与用户数据,bucket 类似 MySQL 的一个表。每个 bucket 都相当于一颗 B+ Tree。用户的 key 数据存放在名为 key 的 bucket 中,etcd 元数据存放在名叫 meta 的 bucket 中。
MVCC 的更新/增加
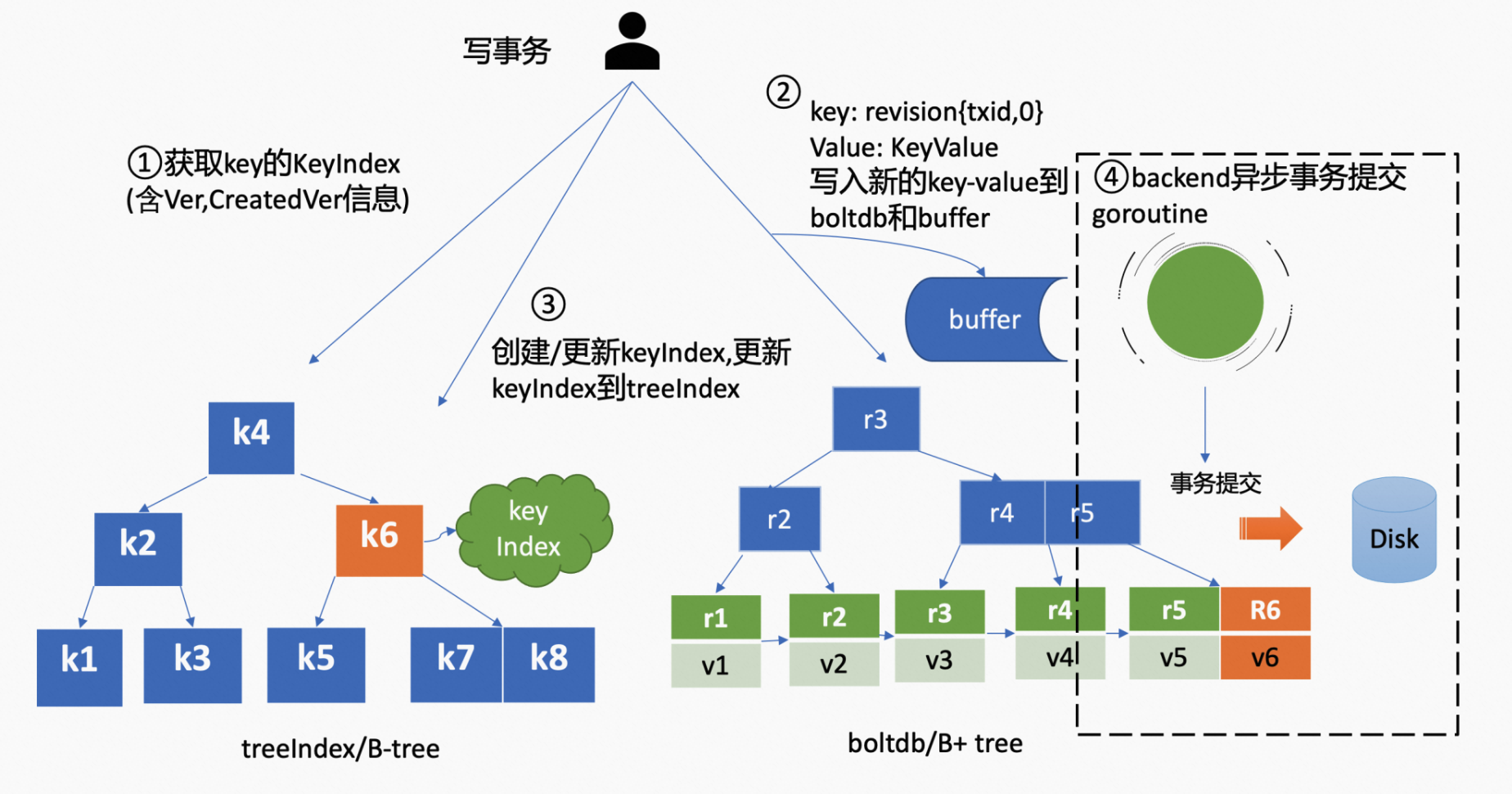
MVCC 针对 put 操作(写事务),如下图所示,
-
它首先从 treeIndex 模块中查询到 key 的 KeyIndex(包含 revision)。如果此时 KeyIndex 为空,etcd 会根据当前的全局版本号(空集群启动时默认为 1)自增,生成 revision。如果 KeyIndex 不为空,则根据 KeyIndex 中的内容和当前的全局版本号,生成 revision。
-
之后填充好 boltdb 的 mvccpb.KeyValue 结构体,并通过后端存储的写事务 BatchTx 接口,将 key:revision,value: mvccpb.KeyValue 保存到 Buffer 中,并更新 boltdb 对应的内存数据结构。

-
然后将新建/更新后的 KeyIndex 对象保存到 treeIndex 模块中。
key hello 的 keyIndex: key: "hello" modified: <2,0> generations: [{ver:1,created:<2,0>,revisions: [<2,0>]}] -
此时数据持久化往往是未完成的。etcd 的一个 backend goroutine 会定期、异步、批量持久化之前写事务所做的更改,也就是在 goroutine 中定期调用 boltdb 的 commit 接口。
该接口会对内存数据结构中的 B+tree 进行平衡、分裂,并且将脏数据、元数据信息刷新到磁盘。由于该过程开销昂贵,如果每次 put 请求都同步调用一次 commit 接口,etcd 的写性能将会变得很差。因此,etcd 才采用合并多个写事务后再进行一次提交,这种方式显著提升了 QPS 和吞吐量。通常情况下,goroutine 会默认每隔 100ms,将累积的写事务一次性提交。但是,如果堆积的事务过多(大于 1w)时,也会触发同步提交。
查询原理
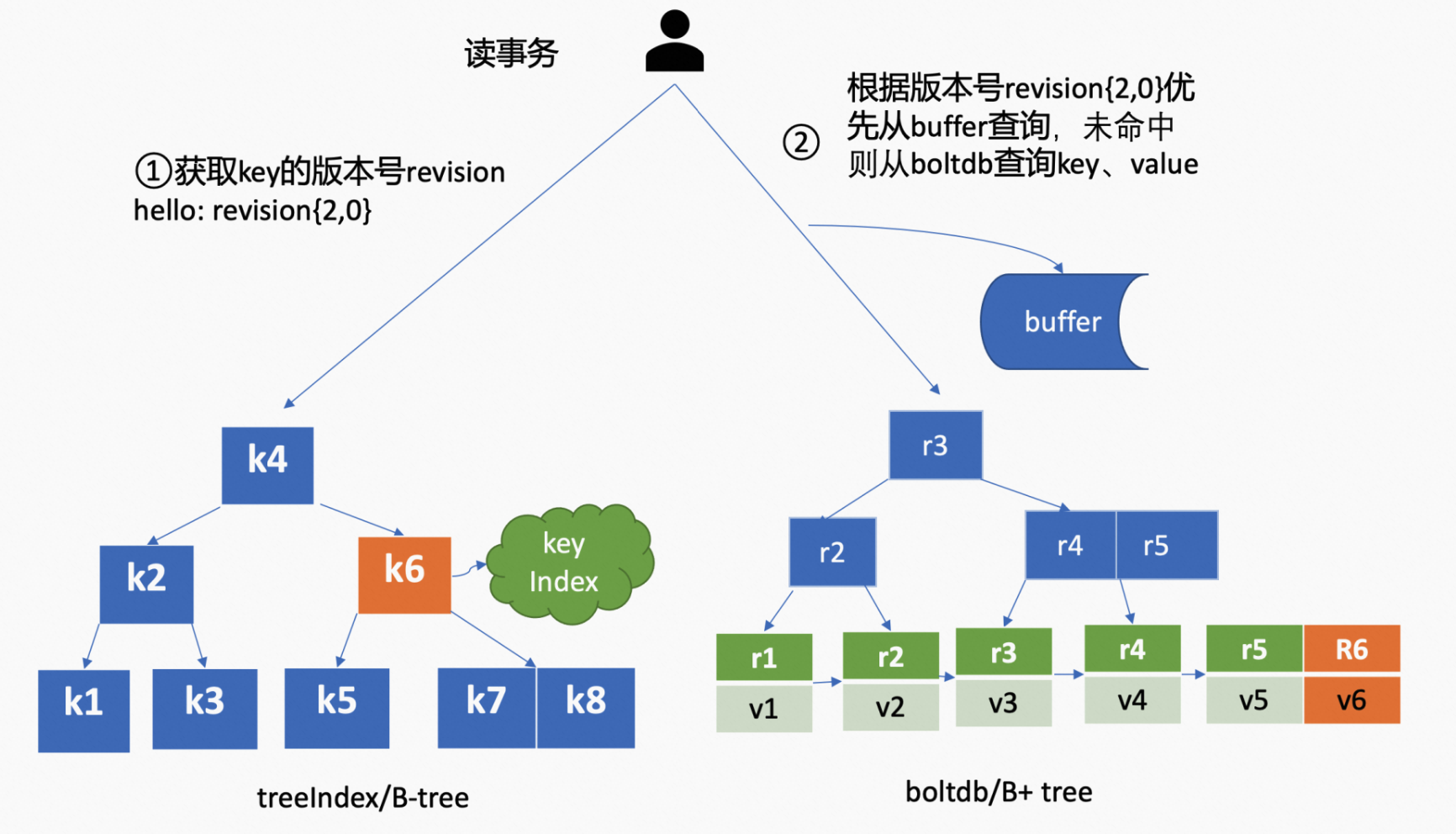
针对 range 操作(读事务)来说,如下图所示,
-
首先 treeIndex 模块根据 key 查找到 KeyIndex 对象,然后匹配有效的 generation。
-
如果是未带版本号的读,默认是读取最新的数据,会返回匹配到的 generation 的 revisions 数组中最后一个 revision。
-
如果是指定版本号,要读取历史记录的话。treeIndex 模块会先遍历匹配到的 generation 的 revisions 数组,返回小于等于指定版本号的最近的 revision。
-
-
之后以返回的 revision 为 key,通过 Backend 提供的并发读事务(ConcurrentReadTx)接口,优先从 Buffer 中查询,命中则返回;否则则从 boltdb 中查询。
ConcurrentReadTx 并发读特性,在 etcd 3.4 中的 Backend 实现。它的核心原理是在进行一次读事务时,会全量拷贝当前写事务未提交的 buffer 数据,此时读事务不再阻塞在一个 Buffer 资源锁上,实现了并发读。
删除原理
MVCC 针对 delete 操作来说,整体流程与 put 流程类似,但是有几点不太相同。
-
首先从 treeIndex 模块中查询到 key 的 KeyIndex(包含 revision)。
-
一方面会生成新的 revision,这个 revision 追加了删除标识(tombstone,简写 t),比如 {4,0,t}
-
另一方面会给该 KeyIndex 对象,追加一个空的 generation 对象,表示该 key 已经被删除了,示例如下所示。
key hello的keyIndex: key: "hello" modified: <4,0> generations: [ {ver:3,created:<2,0>,revisions: [<2,0>,<3,0>,<4,0>(t)]}, {empty} ]当再次查询被删除 key 的时候,treeIndex 模块在查找到 KeyIndex 对象后,发现存在空的 generation 对象,并且查询的版本号大于等于被删除时的版本号时,会返回空。
-
-
之后针对该 revision {4,0,t} 生成 KeyValue 结构体,并将其持久化。此时 KeyValue 结构体中只包含了用户的 key。为什么要持久化呢?如果不持久化,那么发生错误,etcd 重启后在构建 treeIndex 的时候不知道哪些 key 是已经被删除了的。

-
之后压缩组件(compactor)异步完成删除 treeIndex 中的 KeyIndex 和 boltdb 中的 key-value 内容。etcd 针对删除 key 的操作,不是立刻从 treeIndex 和 boltdb 中删除此数据,而是延期删除模式。
-
另外,key 打上删除标记之后,
- Watch 模块会根据 key 的删除标识,生成相应的 delete event 推送给 etcd 客户端,比如 kubernetes。
- 在重启 etcd 的时候,etcd 会遍历 boltdb 中的 key-value 构建 treeIndex 内存树,此时可以清楚获取哪些 key 是已经被删除了的,并为对应的 key 构建带删除标识的索引。
总结
通过以上原理的分析,可以看到 etcd 实现了对 key 历史版本的保存,同时也为 Watch 机制提供了基础。etcd v2 不支持保存 key 的历史版本,v2 为了解决 Watch 依赖历史版本的问题,它会在内存中维护一个较短的全局事件变更窗口(窗口大小为 1000)。但是,在集群写请求较多等场景下,全局事件变更窗口会很容易爆满,仍旧无法提供可靠的 Watch 机制。

