基本概述
BoltDB 是一个纯 Go 语言编写的嵌入式键/值数据库。它提供了一种简单、高效的方式来存储键值对。BotlDB 的特点有:
- 单文件数据库:BoltDB 使用单个文件存储所有数据,方便备份和复制。对于 Etcd 来说,etcd 数据目录下的 member/snap/db 文件就是该数据库文件。
- 使用 mmap 来提高性能:db 文件可以通过 mmap 机制被映射到内存中,后续访问 db 文件时都其实都相当于访问内存,可提升文件内容的读写性能。
- ACID 事务:支持完全的 ACID(原子性、一致性、隔离性、持久性)事务。
- 逻辑上使用 B+ 树来管理数据:db 文件由若干 page 组成,逻辑上使用 B+ Tree 来管理这些 page,实现了快速查找、写入 key-value 数据。
- 使用 bucket 作为存储 key-value 的基本数据结构,bucket 类似于关系型数据库中的表,每个 bucket 在逻辑上都是一颗 B+ 树。对于 Etcd 来说,它会创建 meta/lease/auth /key 等 bucket。
bbolt 是基于 BoltDB 项目的一个分支。BoltDB 不再主动维护之后,CoreOS(现为一部分 Red Hat,隶属 IBM)团队决定创建 bbolt,以继续开发和支持 BoltDB 的用户社区。bbolt 继承了 BoltDB 的所有特性,并且在此基础上有所改进和修复。
Etcd 中的 key- value、lease、meta、member、cluster、auth 等数据都存储在 boltdb 中。
磁盘布局
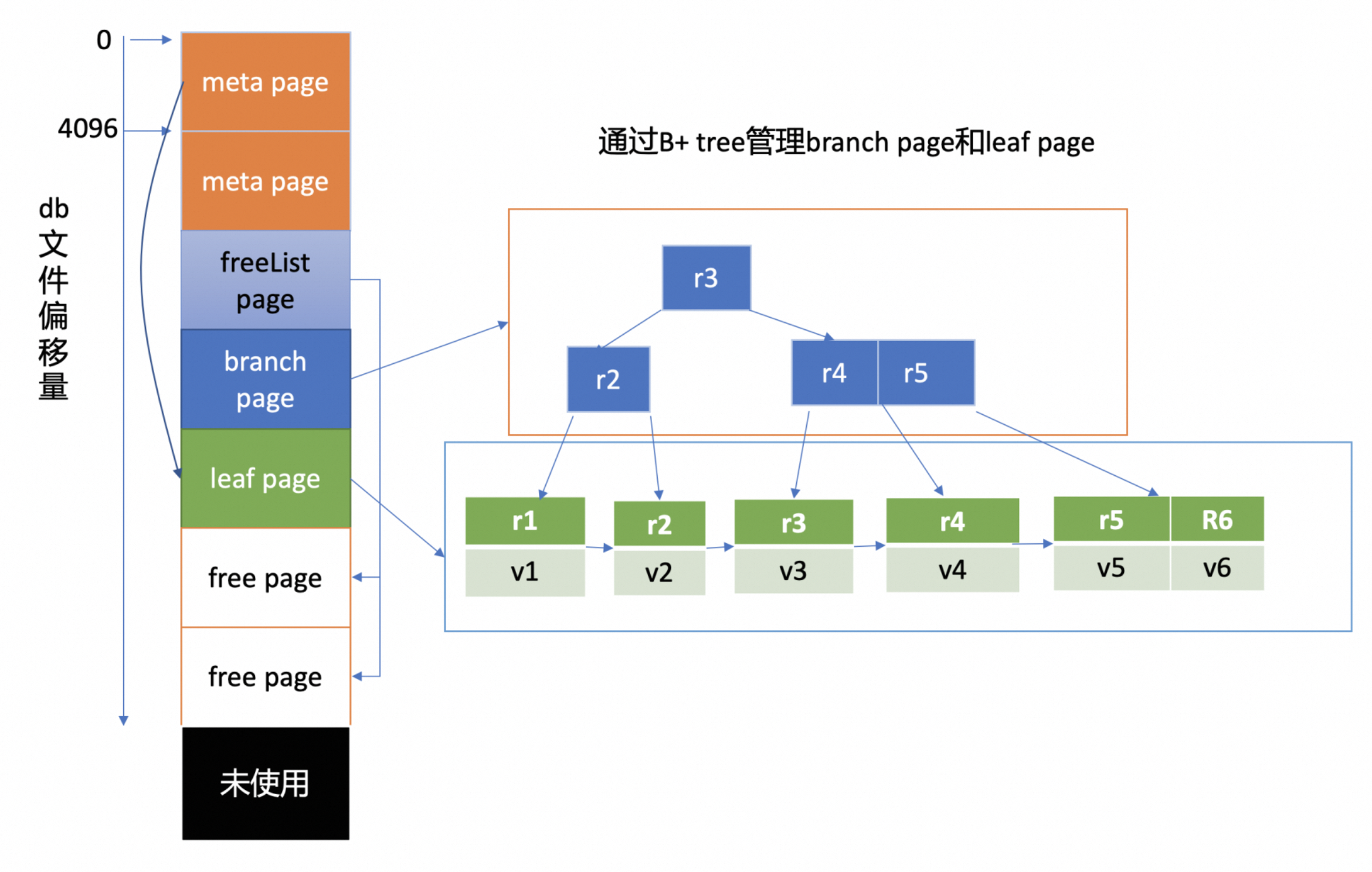
db 文件磁盘布局如上图所示,文件的内容由若干个 page 组成,一般情况下 page size 为 4KB。page 按照功能分为
- meta page(元数据页):也就是文件开头的两个 page,存储的是 db 元数据。
- branch page(B+ tree 索引节点页):记录了 B+tree 中的 key 值。
- leaf page(B+ tree 叶子节点页):记录了 B+tree 中的 key-value 和 bucket 数据。
- freelist page(空闲页管理页)和 free page(空闲页):前者记录了 db 中哪些页是空闲、可使用的。
boltdb 逻辑上通过 B+ tree 来管理 branch/leaf page,实现快速查找、写入 key-value 数据。
page 磁盘结构

每个 page 页中都由以下几个部分组成:
- 页 ID(pgid),8 字节
- 页类型(flags),2 字节,有以下四种四种,
- 0x01 表示 branch page,
- 0x02 表示 leaf page,
- 0x04 表示 meta page,
- 0x10 表示 freelist page。
- 数量(count),2 字节:只在页类型为 leaf 和 branch 时生效。
- 溢出页数量(overflow),4 字节:溢出页数量是指当前页面数据存放不下, 需要向后再申请 overflow 个连续页面使用。
- 页面数据:page 的载体数据,上述几个相当于 page header。不同类型的页在这部分存储的数据结构是不一样的,详见下文。
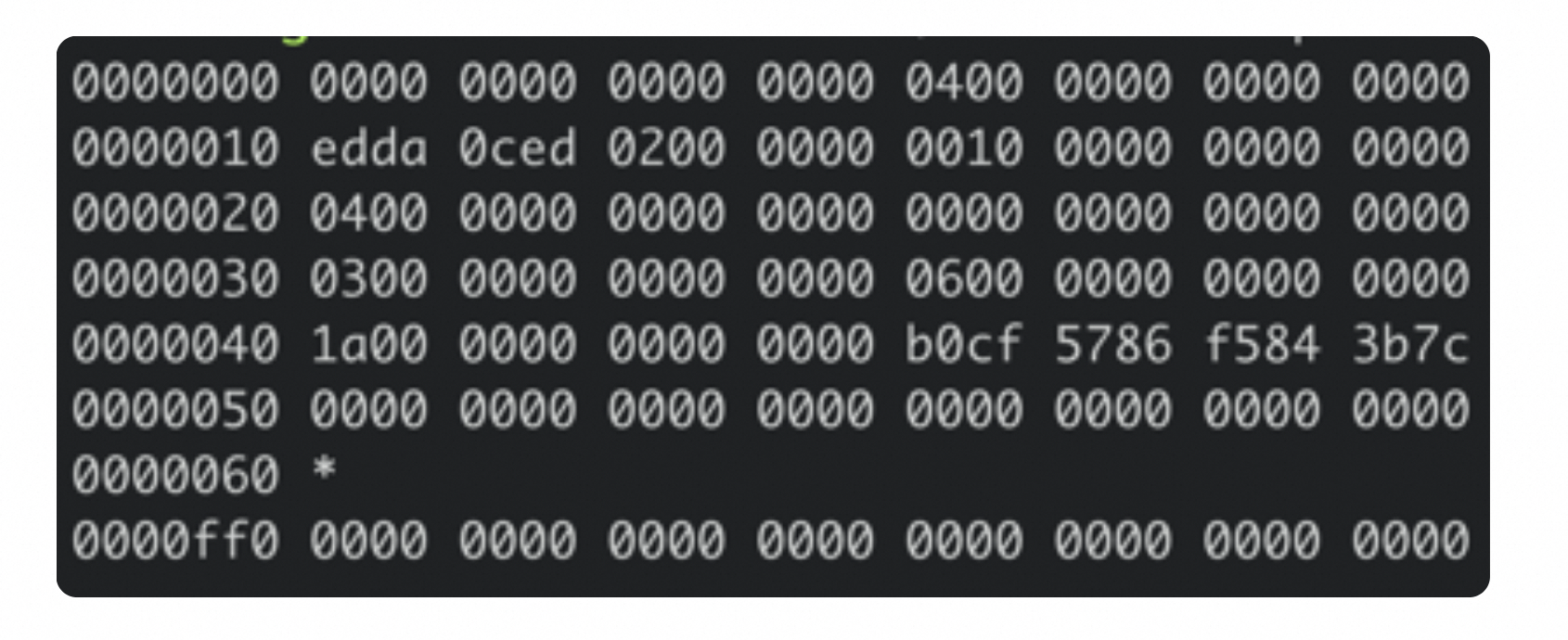
下图中十六进制输出的是 db 文件的 page 0 页结构,左边第一列表示此行十六进制内容对应的文件起始地址,右边每行 16 个字节。可以看到,
- 第一行前 8 个字节描述 pgid(忽略第 一列) 是 0。
- 接下来 2 个字节是页类型,其值为 0x04 表示该 page 是 meta page。
- 从第二行开始存储的是 meta page 内容。
上述内容可由
bblot dump命令获取得到。$ ./bbolt dump ./infra1.etcd/member/snap/db 0
meta page 结构

meta page 的磁盘布局如图所示。首先是 page header(其中页类型为 0x04),之后就是 meta page 存储的主要内容。
-
boltdb 的文件标识(magic),4 字节:上图二进制内容中第二行的前 4 个字节表示 magic number 为 0xED0CDAED。通过它来识别当前文件是否是 boltdb。
-
版本号(version),4 字节:boltdb 的版本号是 0x02。
-
页大小(pagesize),4 字节:页大小为 0x1000=4096=4KB。
-
保留字段(flags),4 字节。
-
boltdb 的 root bucket 结构信息,16 字节。
boltdb 中有一个 root bucket,Etcd 创建的 key/lease/auth 等 bucket 都是 root bucket 的子 bucket。root bucket 通过 B+树来管理这些子 bucket。相当于子 bucket 的结构信息,都是存放在 root bucket 对应的 B+ 树上的。通过 root bucket 可以找到对应的子 bucket。找到子 bucket 之后,再根据 key 可在子 bucket 中找到 key-value 数据。综上来说,root bucket 是按照 B+ 树的方式来管理子 bucket,而子 bucket 又通过 B+ 树的方式来管理 key-value。
上图二进制内容中第三行的 16 个字节表示的就是 root buckect 结构信息。bucket 结构信息由 root 和 sequence 两个字段组成,其中 root 表示该 bucket 的根节点的 page id。可以看到,root bucket 的根节点的 page id 是 4。
type bucket struct { root pgid // page id of the bucket's root-level page sequence uint64 // monotonically incrementing, used by NextSequence() }- 在 bucket 数量比较少的时候,root bucket 根节点的 page 是个 leaf page,直接存储了子 bucket 结构信息。
- 当 bucket 数量较多的时候,root bucket 根节点的 page 是个 branch page,通过该 branch page 和子 bucket 名字,基于 B+树的搜索原理可快速找到子 bucket 的结构信息。
-
freelist 页面的 ID(freelist),8 字节:第四行中前面的 8 个字节 0x3 表示 freelist page 的页 ID。freelist page 记录了 db 当前哪些页面是空闲的。
-
总的页面数量 (pgid),8 字节:第四行后面的 8 个字节,0x06 表示当前 db 的总页面数。
-
上一次写事务 ID(txid),8 字节:第五行前面的 8 个字节,0x1a 表示上一次的写事务 ID。
-
校验码 (checksum),8 字节 :第五行后面的 8 个字节表示校验码,用于检测文件是否损坏。
leaf page 结构
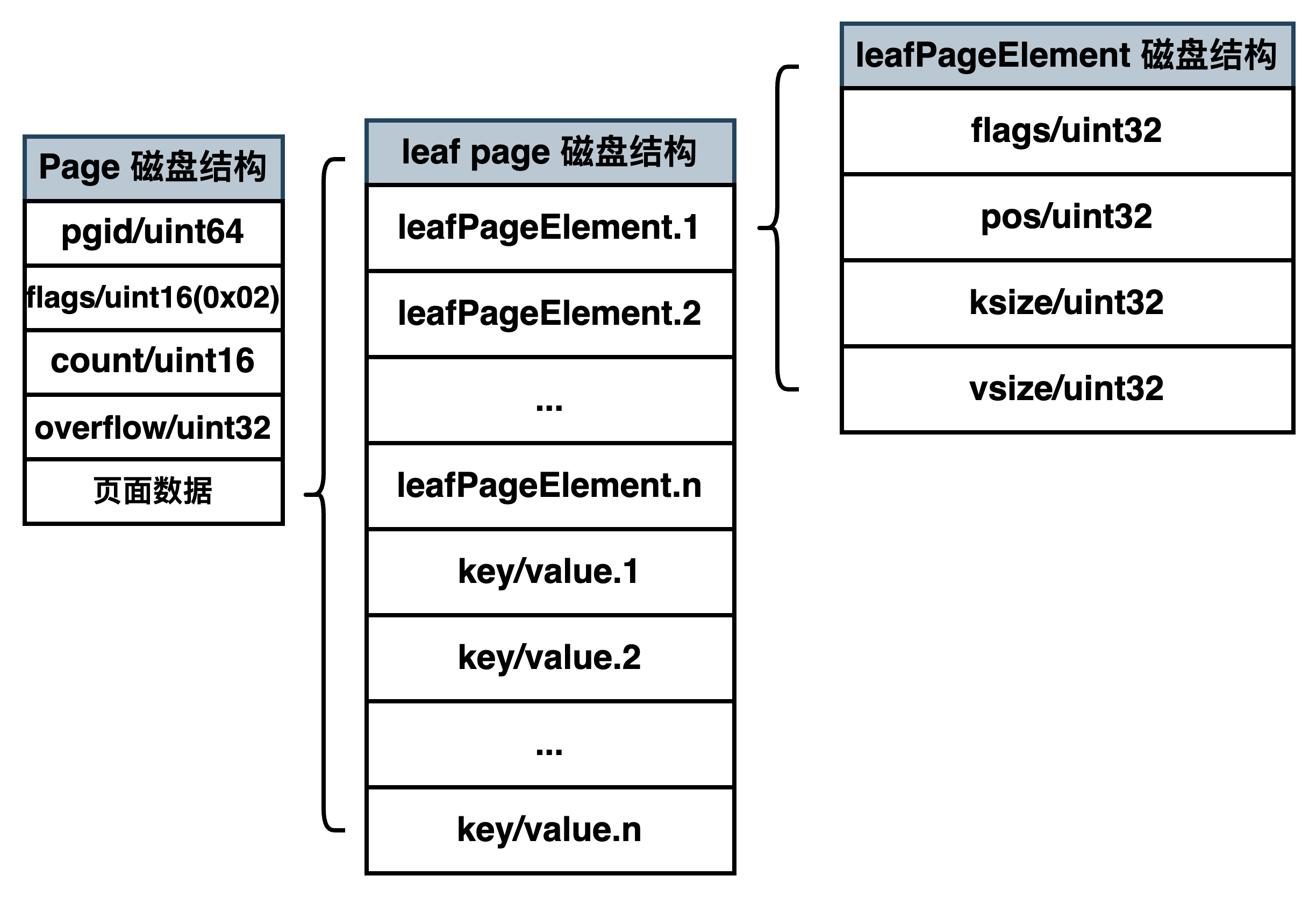
leaf page 的磁盘布局如下图所示。首先还是统一的 page header(其中页类型为 0x02),之后是 leaf page 存储的内容:其中前半部分是 leafPageElement 数组,后半部分是 key-value 数组。leafPageElement 中包含以下信息,
- 类型 flags,4 字节:通过它可以区分存储的是 bucket 名称还是 key-value 数据。
- 当 flag 为 bucketLeafFlag(0x01) 时,表示存储的是 bucket 数据,
- 否则存储的是 key- value 数据。
- 读取偏移量,4 字节。
- key/value 大小,各 4 字节。
- 当存储的是 bucket 数据时,此时 key 是 bucket 名称,value 则是 bucket 结构信息,bucket 结构信息里面包含了 bucket 根节点所在的 page id。通过 bucket 根节点 page id(基于 B+Tree 查找算法)可以快速找到存储在这个 bucket 下的 key-value 数据所在页面。
根据读区偏移量和 key/value 大小,可以方便地从 leaf page 中解析出所有 key-value 对。
branch page 结构

branch page 的磁盘布局如图所示。首先还是统一的 page header(其中页类型为 0x01),之后是 branch page 存储的内容:其中前半部分是 branchPageElement 数组,后半部分是 key 数组。branchPageElement 中包含以下信息,
- 包含 key 的读取偏移量,4 字节。
- key 大小,4 字节。
- 子节点的 page id,8 字节。
根据偏移量和 key 大小,可以方便地从 branch page 中解析出所有 key,然后二分搜索匹配 key,获取其子节点 page id,递归搜索,直至找到子节点 page id 对应的 page 类型为 leaf page。然后,再从中找到对应的 key-value 或者 bucket 结构信息。
freelist page 结构
freelist page 中记录了空闲页的 id。当在 boltdb 中删除大量数据时,其对应的 page 就会被释放,该页就会变为空闲页,页 ID 就会被记录到 freelist page 中。当需要写入数据的时候,就直接从 freelist page 中找到空闲页。
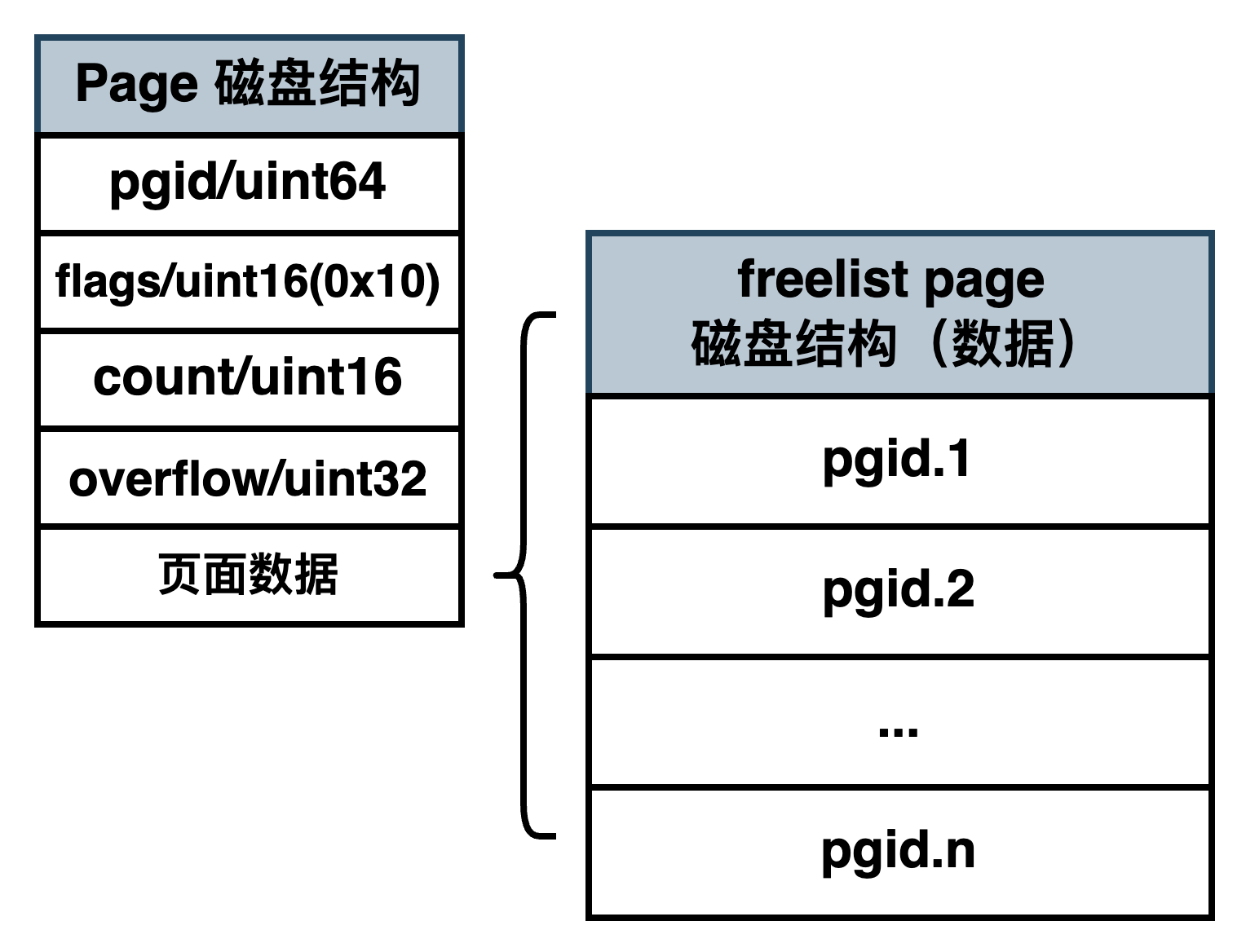
freelist page 的磁盘布局如图所示,首先还是统一的 page header(其中页类型为 0x10),之后就是空闲页 ID 数组。
采用数组的方式会存在一定问题,目前针对 freelist 优化有两个,
-
commit 的时候(下文会提到),B+tree 会进行重平衡和分裂,此时可能会从 freelist 中申请若干连续的 page 存储数据,或释放空闲的 page。如果采用数组的方式,当申请一个连续的 n 个 page 存储数据时,它会遍历 boltdb 中所有的空闲页,直到找到连续的 n 个 page,它的时间复杂度是 O(N)。若 db 文件较大,又存在大量的碎片空闲页,则会导致延时增加,甚至很可能导致超时。同时也可能会释放若干个 page 给 freelist,在合并到 freelist 时,时间复杂度是 O(NLog N)。
因此,etcd 社区在 bbolt 项目中,实现了基于 hashmap 来管理空闲页。通过引入了如下的三个 map 数据结构(freemaps 的 key 是连续的页数, value 是空闲页的起始页 pgid 集合,forwardmap 和 backmap 用于释放的时候快速合并页),将申请和释放时间复杂度降低到了 O(1)。
freemaps map[uint64]pidSet forwardMap map[pgid]uint64 backwardMap map[pgid]uint64现在可以通过 bbolt 的 FreeListType 参数来控制使用 array 还是 hashmap。在 etcd 3.4 版本中还是 array,3.5 版本将默认是 hashmap。
-
同样也是 commit 的时候,如果 db 中存在大量空闲页,此时会导致 freelist page 消耗较多的 db,也会导致持久化时间变长。bbolt 支持启动时扫描全部 page 来构造 freelist,降低了 db 大小和提升写事务提交的性能(相当于 free page 不用再持久化,而是每次启动时都获取一次),但是会带来 etcd 启动延时的上升。可以通过 bbolt 的 NoFreelistSync 参数来控制,默认是 true 启用此特性。
API
boltdb 提供了非常简单的 API 给上层业务使用。通过一个简单的代码示例(创建一个 key bucket,并往这个 bucket 中写入数据为例),看看 boltdb 有提供哪些核心 API。
- 先调用 boltdb 的 Open API,获取到 boltdb 的核心对象 db 实例。
- 再通过 Begin API 开启写事务,获得写事务对象 tx。
- 通过写事务对象 tx,创建 bucket。
- 之后往其中更新了一个 key 为 r94,value 为 world 的数据。
- 最后使用写事务的 Commit 接口提交整个事务,完成 bucket 创建和 key-value 数据写入。在 commit 之前,创建 bucket 和写入数据,其实都相当于是在内存中创建了 boltdb 与之对应的数据结构,而 commit 则是将这些内存中的数据结构写入到 boltdb 中(其实会先写到 boltdb mmap 的内存上,然后由 mmap 持久化到文件中)。
// 打开boltdb文件,获取db对象
db,err := bolt.Open("db", 0600, nil)
iferr!=nil{
log.Fatal(err)
}
defer db.Close()
// 参数true表示创建一个写事务,false读事务
tx,err := db.Begin(true)
if err!=nil{
return err
}
defer tx.Rollback()
// 使用事务对象创建 key bucket
b,err := tx.CreatebucketIfNotExists([]byte("key"))
if err!=nil{
return err
}
// 使用bucket对象更新一个key
if err := b.Put([]byte("r94"),[]byte("world")); err != nil {
return err
}
// 提交事务
if err := tx.Commit(); err != nil {
return err
}
OPEN 原理
-
Open API 会打开 db 文件并对其增加文件锁。文件锁的目的是防止其他进程也以读写模式打开它后,操作 meta 和 free page,导致 db 文件损坏。
-
之后 boltdb 通过 mmap 机制将 db 文件映射到内存中,并读取两个 meta page 到 db 对象实例中(也就是代码中的 db 对象),然后校验 meta page 的 magic、version、checksum 是否有效,若两个 meta page 都无效,那么就表示 db 文件出现了损坏,此时会异常退出。
PUT 原理-创建 Bucket&&Put key
-
首先是根据 meta page 中记录 root bucket 结构找到 root bucket 的 root page,然后按照 B+ tree 的查找算法,从 root page 递归搜索到对应的 leaf page,加载为内存 node 数据结构。内存 node 数据结构记录了 key-value 数据、page id、parent node、children node 以及 B+tree 是否需要进行重平衡和分裂操作等信息。
// node represents an in-memory, deserialized page. type node struct { bucket *Bucket isLeaf bool unbalanced bool spilled bool key []byte pgid pgid parent *node children nodes inodes inodes } -
然后遍历 leaf page 中的 leafPageElement 数组,如果 leafPageElement 类型为 bucketLeafFlag,且 key 相等,那么说明 bucket 已经创建过,不允许 bucket 重复创建,结束请求。否则往 B+ tree 中添加新的 bucket 信息,包括往 leaf page 中添加一个 bucketLeafFlag 类型的 leafPageElement,添加一个 key 名为新增 bucket name,value 为该 bucket 结构信息的内容。如果 B+tree 出现不平衡,可能会对 B+tree 进行调整。
-
创建子 bucket 或者找到子 bucket 之后,往其中添加 key-value 的过程与之类似。
整体过程为,先从子 bucket 的 root page 开始按照 B+ tree 的查找算法,递归搜索到此 key 所在的 leaf page。如果没有找到,则按照 B+ tree 的插入原理插入新的 key 和 value,在 leaf page 中添加 key-value 和 leafPageElement。以一个例子来进行介绍,
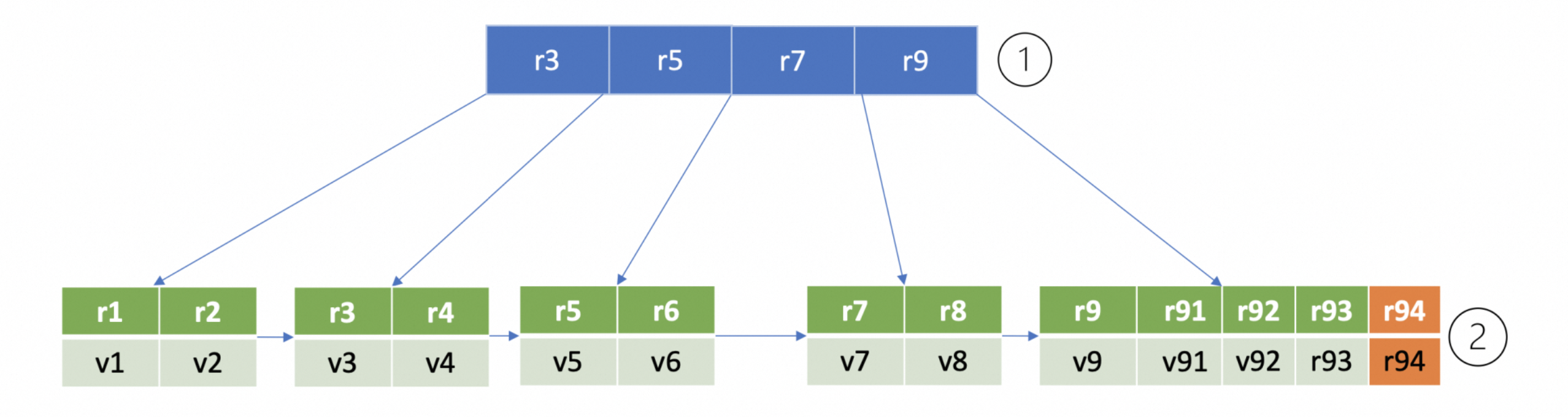
- 从子 bucket 的 root page 中,二分查找大于等于 r94 的 key 所在 page,最终找到 key r9 指向的 leaf page(流程 1)。
- B+tree 需要确保叶子节点 key 的有序性,因此同样二分查找其插入位置,将 key r94 插入到相关位置(流程二)。
Commit 原理-事务提交
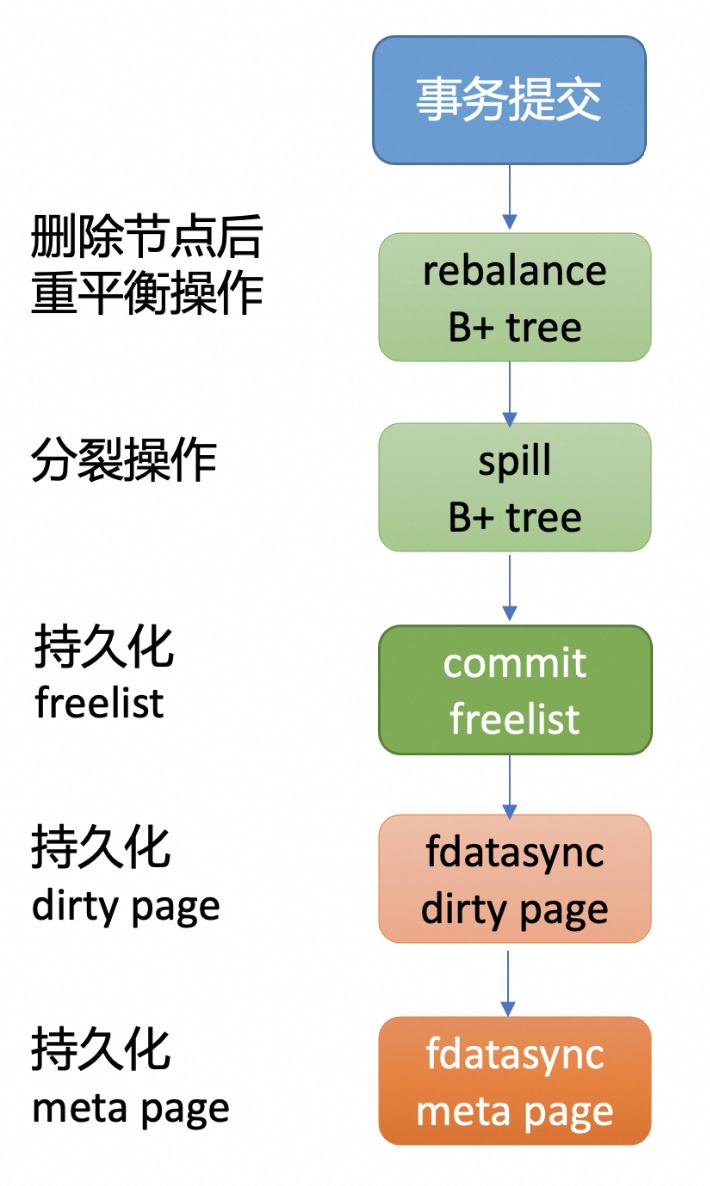
上述 Put 过程中,它会把它访问到的 page 都加载为内存 node 数据结构,更新值也只是更新到了 boltdb 的内存 node 数据结构中,并未持久化到磁盘中。需要执行 tx.Commit 操作才能将数据持久化,tx.Commit 也就是事务提交包括以下步骤:
-
首先是进行重平衡操作。上面 Put 过程中,插入一个新的元素在 B+ tree 的叶子节点上后,它可能已不满足 B+ tree 的特性了。因此,此时需要进行重平衡、分裂操作,使其满足 B+tree 树的特性。此时会涉及到 free page 的申请和释放,etcd 社区针对该步骤进行了优化,简单来说是采用 hashmap 方式来管理 free page,可参考上述 freelist 的介绍。重平衡和分裂的之后的 B+tree 如下图所示,
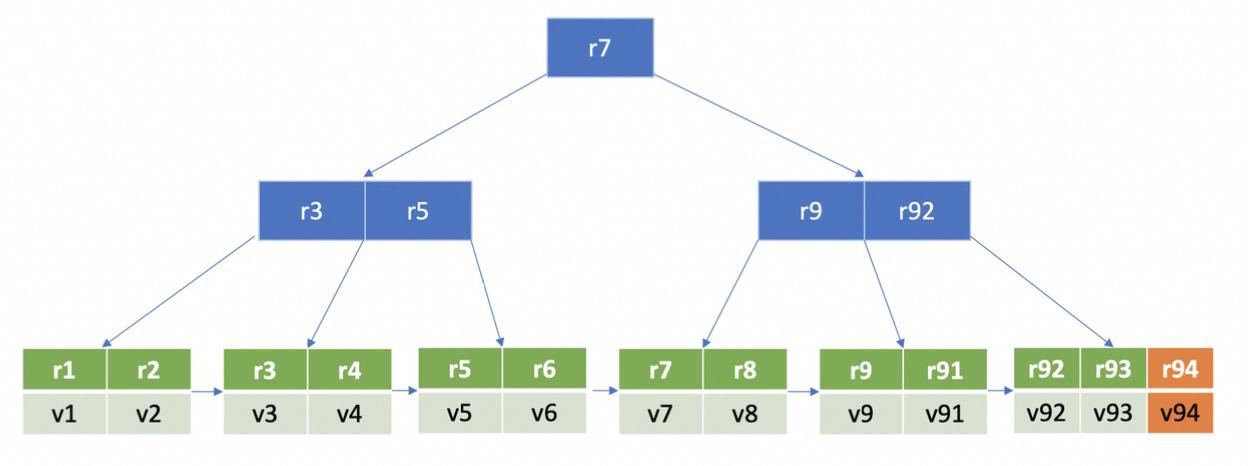
Etcd 中的平衡和分类的条件与常规的 B+tree 树会略有不同,Etcd 相当于借鉴了 B+tree 的思想:
- 合并节点(rebalance):将任何删除过 key 并且大小和 key 数量都不满足要求的 node 进行合并。注意,这里是要有删除过 key 的。
- 分裂节点(spill):将大小超过 page size * FillPercent 的 node 分解为多个 node。可以调整 boltdb 的 bucket.FillPercent 参数,让每个 page 填充更多数据,减少了 page 的分裂次数并且降低 db 空间。
-
由于在重平衡、分裂过程中可能会申请、释放 free page,freelist 所管理的 free page 也发生了变化。因此第二步就是持久化 freelist。
为了优化 commit 的性能等,etcd 社区对 freelist 持久化这一步骤也进行了优化。优化方式是 etcd 启动获取 boltdb db 对象的时候,boltdb 会遍历所有 page,在内存中构建空闲页列表。之后也无需对 freelist 进行持久化,只是每次启动的时候都需要获取,可参考上述 freelist 的介绍。
-
第三步是将操作产生的 dirty page 通过 fdatasync 系统调用,持久化存储到磁盘中。
-
最后在执行写事务过程中,meta page 的 txid、freelist 等字段会发生变化,因此事务的最后一步就是持久化 meta page。
通过以上四大步骤,才算真正完成了事务提交的工作,成功将数据持久化到了磁盘文件中。
总结
-
boltdb 如何管理 bucket 和 key-value 的?
boltdb 中有一个 root bucket,root bucket 按照 B+ 树的方式存储和管理了子 bucket 的信息。而子 bucket 又按照 B+ 树的方式存储和管理了 key-value。因此在 Put 的时候,是先通过 root bucket 找到对应的子 bucket,然后在子 bucket 上找到 key-value。
-
写入数据的过程实际是怎么样的?
Put 等写入数据的行为,操作的是内存中的 node 数据结构,也就是一个 Put 请求在完成 WAL 日志写入和数据更新到内存的 node 数据结构中后就算完成了,不会调用 Commit API,也就不涉及到持久化。
Commit 的时候会进行持久化,而 Commit 操作是由一个 goroutine 定期调用的。另外,对于 boltdb 的 mmap 机制,在整个流程中不用太关心,将它作为文件概念中的一部分就好。
附录
相关链接
高可用分布式存储 etcd 的实现原理:https://draveness.me/etcd-introduction/
B树、B+树索引算法原理(上):https://www.codedump.info/post/20200609-btree-1/
B树、B+树索引算法原理(下):https://www.codedump.info/post/20200615-btree-2/
常用命令
# bbolt buckets 命令,输出一个 db 文件中包含哪些 bucket
$ ./bbolt buckets ./infra1.etcd/member/snap/db
alarm
auth
authRoles
authUsers
cluster
key
lease
members
members_removed
meta
# bbolt pages 命令可以查看各个 page 类型和元素数量
$ ./bbolt pages ./infra1.etcd/member/snap/db
ID TYPE ITEMS OVRFLW
======== ========== ====== ======
0 meta 0
1 meta 0
2 free
3 freelist 2
4 leaf 10
5 free
# bbolt page 命令可以查看 page 信息,可以看到 3 号页是 freelist page,
$ ./bbolt page ./infra1.etcd/member/snap/db 3
pageID: 3
page Type: freelist
Total Size: 4096 bytes
Item Count: 2
Overflow: 0
2
5
# bbolt dump 命令,可打印 page 的二进制数据
$ ./bbolt dump ./infra1.etcd/member/snap/db 0

